MongoDB: Consistency Levels and the CAP/PACLEC Theorem
This article seeks to address this w.r.t MongoDB in-depth, thereby providing a broad overview of approaching CAP and PACLEC theorems.
Join the DZone community and get the full member experience.
Join For Free
There is a lot of discussion in the NoSQL community about consistency levels offered by NoSQL DBs and its relation to CAP/PACELC theorem. This article seeks to address this w.r.t MongoDB in-depth, thereby providing a broad overview of approaching CAP and PACLEC theorems from a NoSQL perspective. For a quick summary of consistency levels, please refer to Consistency Matrix towards the end of the article.
You might also enjoy: Understanding the CAP Theorem
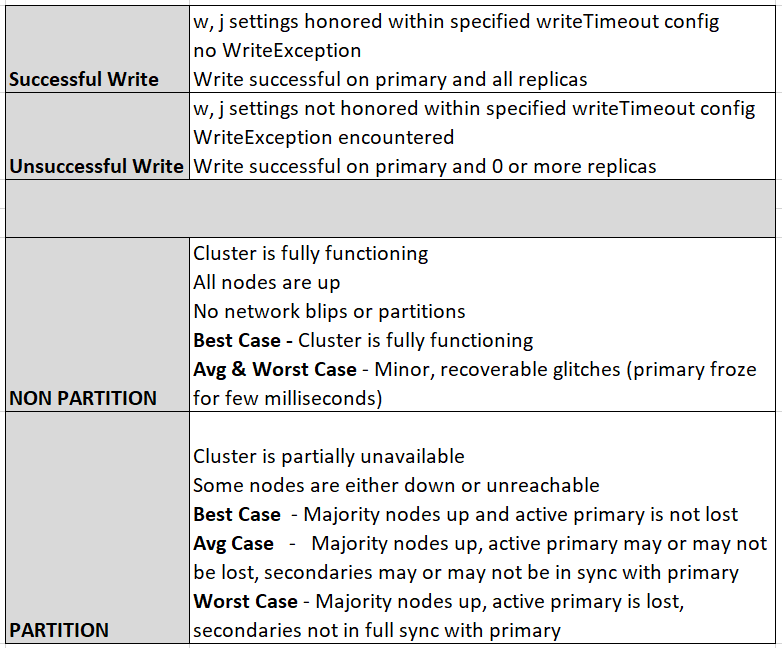
MongoDB Notes for the Purpose of This Article
MongoDB always replicates data asynchronously from primary to secondaries. This cannot be changed.
Even when you increase writeconcern to w:2 or w:majority and enable journaling, replication is still asynchronous.
Secondaries read data from the primary's oplog and apply operations asynchronously.
Default writeconcern of MongoDB is w:1 (successful write to primary) and journaling is disabled j:false
WRITEs can be performed only on PRIMARY
By Default, READs are done on PRIMARY. This can be changed by sacrificing consistency.
Enabling READs from SECONDARIES results in stale/dirty reads and and makes MongoDB EVENTUAL CONSISTENT even without a PARTITION.
Availability during a partition of MongoDB cluster is always on BEST EFFORT basis. A part of the cluster is always lost in the event of a partition.
Loss of Consistency in MongoDB
During Partition — By default, due to asynchronous replication, when there is a partition in which primary is lost or becomes isolated on the minority side, there is a chance of losing data that is unreplicated to secondaries, hence there is loss of consistency during partitions. More on how to address this below.
Without Partition — If reads from secondaries are enabled, async replication forces MongoDB to be eventually consistent even when there is no partition.
Some Definitions
Tuneable Consistency (Consistency Continuum)
Consistency is not a discrete point in space, it is a continuum, ranging from Strong Consistency at one extreme to Weak Consistency on the other, with varying points of Eventual Consistency in between. Each software application, according to the use case, may choose to belong anywhere in between.
With availability during a partition being always on Best-Effort basis, Consistency Level during a PARTITION is traded off with latency during NON-PARTITION. Decisioning on write latency as per our application requirement drives us to a point in the Consistency Continuum and vice versa.
We can achieve varying levels of latency during NON-PARTITION and varying consistency guarantees during PARTITION by tuning w and j values as below:
Example, w:0 no guarantees — very very low latency, very very low consistency - writes can be lost without PARTITION
Example, w:1 and j:false guarantees writes onto primary(disk) — very low latency, very low consistency
Example, w:2 and j:false guarantees writes onto primary(disk) + 1 secondary (memory) — low latency, low consistency
Example, w:2 and j: true guarantees writes onto primary(disk) + 1 secondary (disk) — mid latency, mid consistency
Example, w:majority and j: false guarantees writes onto primary(disk) + majority secondary (memory) — mid latency, mid consistency
Example, w:majority and j: true guarantees writes onto primary(disk) + majority secondary (memory) — high latency, high consistency
With {w:1, j:false} — writes are faster when there is no partition as writes do not wait on replication.
And with {w:1, j:false} — in the event of PARTITION when primary node is lost, there is a high probability of successful writes being lost.
The probability of losing successful writes decreases with an increase in writeconcern and by enabling journaling.
To READ or NOT-TO-READ From Secondaries
Barring the below cases:
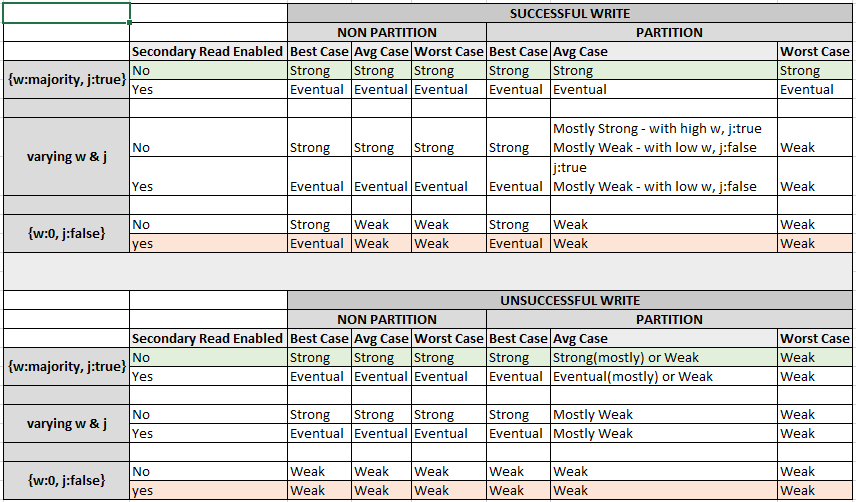
{w:majority, j: true } — Strong Consistency in most cases
{w:0, j:false} — Weak Consistency in any primary failure,
for all other combinations of w & j, the below is how reading/not reading from secondaries affect the consistency levels.
If reads from secondaries are enabled, stale data is read and MongoDB offers following consistency levels,
Successful writes when there is NO PARTITION — Eventual Consistency
Unsuccessful writes when there is NO PARTITION — Eventual Consistency
Worst Case for successful writes when there is PARTITION — Weak Consistency
Avg case for successful writes heavily depends on the configuration and the way cluster is partitioned leaning towards Eventual Consistency.
Best Case for successful writes when there is PARTITION when acting primary is not lost — Eventual Consistency
Worst Case for unsuccessful writes when there is PARTITION — Weak Consistency
Avg case for unsuccessful writes heavily depends on the configuration and the way cluster is partitioned leaning towards Weak Consistency
Best case for unsuccessful writes when there is PARTITION when acting primary is not lost — Eventual Consistency
If reads from secondaries are disabled, MongoDB offers the following consistency levels:
Successful writes(no writeTimeout) when there is NO PARTITION — Strong Consistency
Unsuccessful writes( errored with writeTimeout) when there is NO PARTITION — Strong Consistency
Worst Case for successful writes(no writeTimeout) when there is PARTITION — Weak Consistency
Avg case for successful writes heavily depends on the configuration and the way the cluster is partitioned leaning towards Strong Consistency.
Best Case for successful writes(no writeTimeout) when there is PARTITION and the acting primary is not lost — Strong Consistency
Worst Case for unsuccessful writes (errored writeTimeout) when there is PARTITION and the acting primary is lost — Weak Consistency
Avg case for unsuccessful writes(errored writeTimeout) heavily depends on the configuration and the way cluster is partitioned leaning towards Weak Consistency
Best case for unsuccessful writes(errored writeTimeout) when there is PARTITION and the acting primary is not lost — Strong Consistency
It becomes 0 when {w:majority, j:true}
Caveats and Considerations of Varying w and j Values
If we want low latency during non-partition a.k.a normal times then writeconcern should be set to a lower value and journaling should be disabled.
However, the trade-off here is when partition occurs on such a cluster, the probability of losing successful writes is very high.
When there is no partition or when all nodes are up, MongoDB is consistent and achieves low latency
When there is a partition, MongoDB's consistency depends on the writeconcern and journaling settings.
The lower the latency expectation. the lower should be the value of writeconcern(w:1) with journaling disabled (j:false).
Concluding Remarks on Tuneable Consistency — CAP/PACELC Theorem
Barring the below cases
{w:majority, j: true } - Strong Consistency in most cases
{w:0, j:false} - Weak Consistency in any primary failure,
For all other combinations of w & j, we cannot precisely define where a MongoDB cluster lies in the Consistency Continuum defined by CAP or PACELC theorems.
Availability [Applicable for the Entire Consistency Continuum]
MongoDB provides Best Effort Availability because in case of partition, we will always lose a part of the cluster — at least a minority.
If MAJORITY of the cluster is lost we can only READ from MongoDB. Write availability is totally impacted.
if MINORITY of the cluster is lost we can READ and WRITE from MongoDB. Partial Availability.
Achieving Strong Consistency
With the below settings, MongoDB offers strong consistency in most cases for practical purposes.
{w:majority} and {j:true}
WRITE on primary node(only possible setting with MongoDB)
READ from primary node only (for max consistency)
Consistency Levels Offered Under Various Scenarios
Successful writes when there is NO PARTITION — Strong Consistency
Unsuccessful writes when there is NO PARTITION — Strong Consistency
Worst Case for successful writes when there is PARTITION — Strong Consistency
Worst Case for successful writes Strong Consistency.
Best Case for successful writes when there is PARTITION and acting primary is not lost — Strong Consistency
Worst Case for unsuccessful writes when there is PARTITION and acting primary is lost — Weak Consistency
Avg case for unsuccessful writes heavily depends on the configuration and the way cluster is partitioned — Leans towards Strong Consistency
Best case for unsuccessful writes(errored writeTimeout) when there is PARTITION and acting primary is not lost — Strong Consistency
Caveats and Considerations of the Above Settings
Setting {w:majority} and {j:true} forces the client to wait till the majority of the secondaries accept and persist the write.
Setting {w:majority} and {j:true} introduces latency in writes.
Event with this setting, unsuccessful writes might be lost during partition when the primary is lost.
With this setting, successful writes are not lost during partition.
Concluding Remarks on Strong Consistency — CAP/PACELC Theorem
With {w:majority, j:true} and READ from primary only, MongoDB could be categorized as CP in CAP and CP/EC in PACELC theorem
Consistency Matrix
Further Reading
Cloud-Native Applications and the CAP Theorem
Opinions expressed by DZone contributors are their own.
Comments