Mule 4: Processing Multibyte Characters in Fixed-Width Flat Files
A custom solution to handle multibyte characters for fixed-width flat files in Mulesoft. Dataweave can process several different types of data formats.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Dataweave can process several different types of data formats like flat files, copybooks, fixed-width files, etc. For most of these types, you can import a schema that describes the input structure in order to have access to valuable metadata at design time.
Problem Statement
These schemas currently only work with certain single-byte character encodings. All foreign languages — Spanish, Japanese, French, etc. are of multibyte size unlike English, where 1 character = 1 byte.
Mulesoft doesn’t have the capability to handle multibyte characters. While processing, the mule runtime considers each character present in the fixed-width flat file of 1 (one) byte.
Thus, if there is any multibyte character present in the flat file it couldn’t be parsed correctly.
Solution Brief
Conversion of flat files with multibyte characters, to single byte, thus ensuring correct parsing while it is processed in Mulesoft.
Optional conversion back to the original structure while exporting the file to external systems.
Prerequisites
Anypoint Studio 7.6, Mule Runtime 4.3.0, Knowledge of Flat File Schemas.
Problem
For the purpose of demonstration, I am using the Flat File Definition (.ffd) as given below:
formFIXEDWIDTH
id'flatfile'
name'flatfile'
values
name'Id' usageM typeString length2
name'FirstName' usageM typeString length10
name'LastName' usageM typeString length10
name'City' usageM typeString length10
name'State' usageM typeString length10
name'Country' usageM typeString length10
As per the schema definition, the FirstName length should be size 10 (ten). When a fixed width flat file is created by ERP systems, each line is written by bytes and not characters. For example, the Japanese characters are of 3 (three) bytes in UTF-8 format. They will occupy only one space in a file but in actual as per the ERP system, it is 3 spaces.
x
日 -> 3 bytes
本 -> 3 bytes
語 -> 3 bytes
日本語 -> 9 bytes
ABC -> 3 bytes (English Alphabets 1 character = 1 byte)
The process flow below is used for processing fixed-width flat file:

The fixed-width flat file to be processed is as below:
xxxxxxxxxx
1 Ravneet Bhardwaj Gurugram Haryana India
2 日本語 Bhardwaj Gurugram Haryana India
Here the first line contains single-byte characters so Mulesoft will be able to handle them without any problems, but in the second line for FirstName certain Japanese characters are passed. These characters occupy only 3 spaces but in actual these are 9 bytes. As per the FFD schema, the FirstName should be of size 10 (ten). While processing, Mulesoft will throw an exception.

Since Mulesoft considers all characters as single bytes, it throws an exception that the expected size is not met for a particular field. In this case, it's the FirstName.
Solution
A custom Java utility that will read each character of the flat file, line by line. As soon a multibyte character is encountered, the custom solution appends extra spaces next to each multibyte character.
The number of spaces added is dynamic, based on the size of the multibyte character.
MyUtility.java
xxxxxxxxxx
package com.ravneet.utility;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class MyUtils {
public static String convertflatfile(Object input) {
StringBuilder builder = new StringBuilder();
try {
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader((InputStream) input)) {
};
String fileOutput;
while ((fileOutput = bufferedReader.readLine()) != null) {
String[] arr = fileOutput.split("");
for (int i = 0; i < arr.length; i++) {
builder.append(arr[i]);
if (arr[i].getBytes().length > 1) {
int bytelength = arr[i].getBytes().length;
while (bytelength != 1) {
builder.append(" ");
--bytelength;
}
}
}
builder.append("\n");
}
//System.out.println(builder.toString());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return builder.toString();
}
public static String removingSpace(String input) {
String[] arr = input.split("");
StringBuilder builder = new StringBuilder();
for (int i = 0; i < arr.length; i++) {
builder.append(arr[i]);
if (arr[i].getBytes().length > 1) {
int bytelength = arr[i].getBytes().length;
while (bytelength != 1) {
--bytelength;
i++;
}
}
}
//System.out.println(builder.toString());
return builder.toString();
}
}
The above Java utility has two functions: convertflatfile and removingSpace.
convertflatfile— This is a preprocessor that reads the flat file and converts the multibyte characters to single-byte characters.removingSpace— This is a post-processor that removes the extra spaces added by the preprocessor.
Below is the modified process flow:
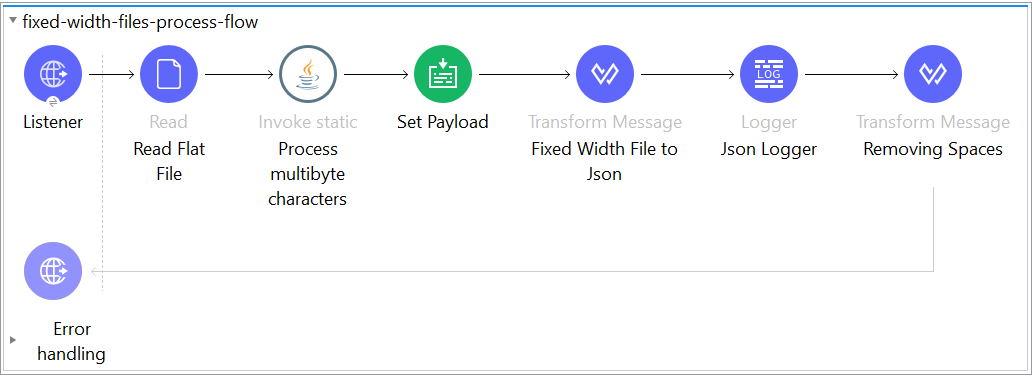
While reading the file, the below property should be selected:

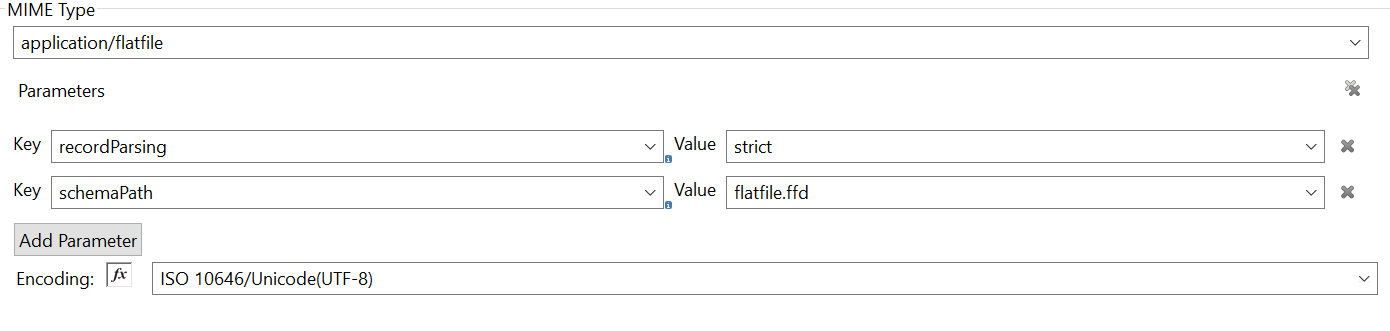
The Set Payload component will contain the FFD schema details.

In the post-processing, the spaces are removed:
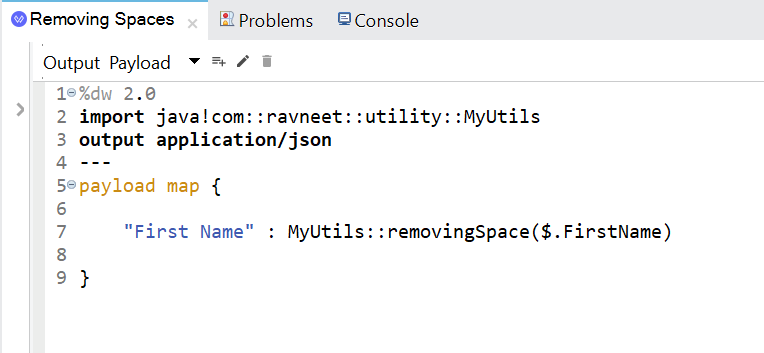
Output:

Conclusion
The above solution will enable Mulesoft to process and parse flat files with multibyte characters. This is an interim solution until Mulesoft provides an out-of-the-box functionality for the problem.
Opinions expressed by DZone contributors are their own.
Comments