NULL in Oracle
We thoroughly analyze all the subtleties associated with NULLs in the Oracle DBMS, as well as the issues of using indexes with NULL and query performance.
Join the DZone community and get the full member experience.
Join For FreeKey Points
The special value NULL means no data, a statement of the fact that the value is unknown. By default, columns, and variables of any type can take this value unless they have a NOT NULL constraint. Also, the DBMS automatically adds a NOT NULL constraint to columns included in the table's primary key.
The main feature of NULL is that it is not equal to anything, not even another NULL. You cannot compare any value with it using any operators: =, <, >, like ... Even the expression NULL != NULL will not be true because one cannot uniquely compare one unknown with another. By the way, this expression will not be false either because when calculating the conditions, Oracle is not limited to the TRUE and FALSE states. Due to the presence of an element of uncertainty in the form of NULL, there is one more state — UNKNOWN.
Thus, Oracle operates not with two-valued but with three-valued logic. This feature was laid down in his relational theory by grandfather Codd, and Oracle, being a relational DBMS, fully follows his precepts. In order not to meditate on the УweirdФ results of queries, the developer needs to know the truth table of three-valued logic.
For convenience, we will make a procedure that prints the state of a boolean parameter:
procedure testBool( p_bool in boolean ) is
begin
if p_bool = true then
dbms_output.put_line('TRUE');
elsif p_bool = false then
dbms_output.put_line('FALSE');
else
dbms_output.put_line('UNKNOWN');
end if;
end;Familiar comparison operators give in to NULL:
exec testBool( null = null ); -- UNKNOWN
exec testBool( null != null ); -- UNKNOWN
exec testBool( null = 'a' ); -- UNKNOWN
exec testBool( null != 'a' ); -- UNKNOWNComparison With NULL
There are special operators, IS NULL and IS NOT NULL, that allow comparisons with NULLs. IS NULL will return true if the operand is NULL and false if it is not.
select case when null is null then 'YES' else 'NO' end from dual; -- YES
select case when 'a' is null then 'YES' else 'NO' end from dual; -- NOAccordingly, IS NOT NULL does the opposite: it will return true if the value of the operand is non-NULL and false if it is NULL:
select case when 'a' is NOT null then 'YES' else 'NO' end from dual; -- YES
select case when null is NOT null then 'YES' else 'NO' end from dual; -- NOIn addition, there are a couple of exceptions to the rules regarding comparisons with missing values. The first is the DECODE function, which considers two NULLs to be equivalent to each other. Secondly, these are composite indexes: if two keys contain empty fields, but all their non-empty fields are equal, then Oracle considers these two keys to be equivalent.
DECODE goes against the system:
select decode( null
, 1, 'ONE'
, null, 'EMPTY' -- это условие будет истинным
, 'DEFAULT'
)
from dual;Boolean Operations and NULL
Normally, the UNKNOWN state is handled in the same way as FALSE. For example, if you select rows from a table and the x = NULL condition in the WHERE clause evaluates to UNKNOWN, then you won't get any rows. However, there is a difference: if the expression NOT(FALSE) returns true, then NOT(UNKNOWN) returns UNKNOWN. The logical operators AND and OR also have their own characteristics when handling an unknown state. Specifics in the example below.
In most cases, an unknown result is treated as FALSE:
select 1 from dual where dummy = null; -- query will not return resultThe negation of the unknown gives the unknown:
exec testBool( not(null = null) ); -- UNKNOWN
exec testBool( not(null != null) ); -- UNKNOWN
exec testBool( not(null = 'a') ); -- UNKNOWN
exec testBool( not(null != 'a') ); -- UNKNOWNOR operator:
exec testBool( null or true ); -- TRUE <- !!!!!
exec testBool( null or false ); -- UNKNOWN
exec testBool( null or null ); -- UNKNOWNAND operator:
exec testBool( null and true ); -- UNKNOWN
exec testBool( null and false ); -- FALSE <- !!!!!
exec testBool( null and null ); -- UNKNOWNIN and NOT IN Operators
Let's start with a few preliminary steps. For tests, let's create a table T with one numeric column A and four rows: 1, 2, 3, and NULL.
create table t as select column_value a from table(sys.odcinumberlist(1,2,3,null));Enable request tracing (you must have the PLUSTRACE role for this).
In the listings from the trace, only the filter part is left to show what the conditions specified in the request unfold into.
set autotrace onThe preliminaries are over. Now let's work with the operators. Let's try to select all records that are included in the set (1, 2, NULL):
select * from t where a in ( 1, 2, null ); -- will return [1, 2]
-- Predicate Information:
-- filter("A"=1 OR "A"=2 OR "A"=TO_NUMBER(NULL))As you can see, the line with NULL was not selected. This happened because the evaluation of the predicate "A"=TO_NUMBER(NULL) returned the status UNKNOWN. In order to include NULLs in the query result, you have to specify it explicitly:
select * from t where a in ( 1, 2 ) or a is null; -- will return [1, 2, NULL]
-- Predicate Information:
-- filter("A" IS NULL OR "A"=1 OR "A"=2)Let's try now with NOT IN:
select * from t where a not in ( 1, 2, null ); -- no rows selected
-- Predicate Information:
-- filter("A"<>1 AND "A"<>2 AND "A"<>TO_NUMBER(NULL))Not a single result at all! Let's see why the triple was not included in the query results. Let's manually calculate the filter applied by the DBMS for case A=3:
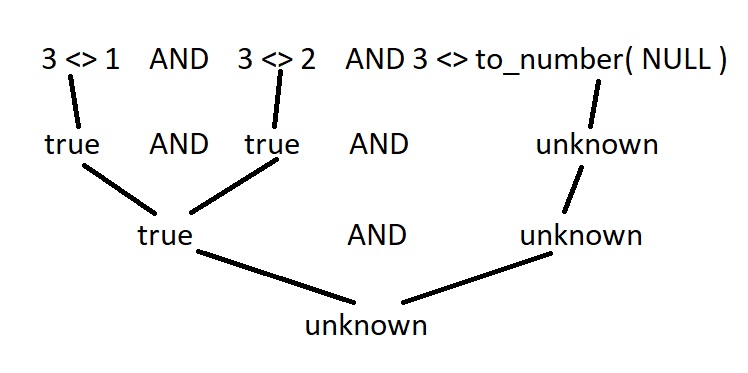
Due to the peculiarities of the three-valued logic, NOT IN is not friendly with NULLs at all: as soon as NULL gets into the selection conditions, do not wait for the data.
NULL and Empty String
Here Oracle deviates from the ANSI SQL standard and declares the equivalence of NULL and the empty string. This is perhaps one of the most controversial features, which from time to time, gives rise to multi-page discussions with the transition to personalities and other indispensable attributes of tough disputes. Judging by the documentation, Oracle itself would not mind changing this situation (it says that even now, an empty string is treated as NULL, this may change in future releases), but today such a colossal amount of code has been written for this DBMS, what to take and change the behavior of the system is hardly realistic. Moreover, they started talking about this, at least from the seventh version of the DBMS (1992-1996), and now the twelfth is on its way.
NULL and empty string are equivalent:
exec testBool( '' is null ); -- TRUEIf you follow the precept of the classic and look at the root, then the reason for the equivalence of an empty string and NULL can be found in the storage format of varchars and NULLs inside data blocks. Oracle stores table rows in a structure consisting of a header followed by data columns. Each column is represented by two fields: the length of the data in the column (1 or 3 bytes) and, in fact, the data itself. If varchar2 has zero length, then there is nothing to write in the data field, it does not take a single byte, and the special value 0xFF is written in the length field, indicating the absence of data. NULL is represented in exactly the same way: there is no data field, and 0xFF is written in the length field. The developers of Oracle could, of course, separate these two states, but that's how it has been with them since ancient times.
Personally, the equivalence of an empty string and NULL seems quite natural and logical to me. The very name "empty line" implies the absence of meaning, emptiness, a donut hole. NULL basically means the same thing. But there is an unpleasant consequence here: if you can say with certainty about an empty string that its length is equal to zero, then the length of NULL is not defined in any way. Therefore, the expression length('') will return NULL for you, not zero, as you obviously expected. Another problem: you can't compare against an empty string. The expression val = '' will return the status UNKNOWN since it is essentially equivalent to val = NULL.
The length of the empty string is undefined:
select length('') from dual; -- NULLComparison with an empty string is not possible:
exec test_bool( 'a' != '' ); -- UNKNOWNCritics of Oracle's approach argue that an empty string does not necessarily mean unknown. For example, a sales manager fills out a customer card. He may indicate his contact number (555-123456), may indicate that he is unknown (NULL), or may indicate that there is no contact number (empty string). With the Oracle method of storing empty strings, it will be problematic to implement the latter option. From the point of view of semantics, the argument is correct, but I always have a question on it to which I have not received a complete answer: how will the manager enter an empty string in the УphoneФ field, and how will he further distinguish it from NULL? Of course, there are options, but still...
Actually, if we talk about PL/SQL, then somewhere deep inside its engine, an empty string NULL are different. One way to see this is because associative collections allow you to store an element at index '' (an empty string) but do not allow you to store an element at index NULL:
declare
procedure empty_or_null( p_val varchar2 )
is
type tt is table of varchar2(1) index by varchar2(10);
t tt;
begin
if p_val is not null then
dbms_output.put_line('not null');
else
-- trying to create an element with index p_val
t(p_val) := 'x';
-- happened!
dbms_output.put_line('empty string');
end if;
exception
-- it was not possible to create an element with index p_val
when others then dbms_output.put_line('NULL');
end;
begin
empty_or_null( 'qwe' ); -- not null
empty_or_null( '' ); -- empty string
empty_or_null( NULL ); -- NULL
end;In order to avoid problems, it is better to learn the rule from the docs: an empty string and NULL are indistinguishable in Oracle.
NULLMath
select decode( null + 10, null, 'UNKNOWN', 'KNOWN') a from dual; -- UNKNOWN
select decode( null * 10, null, 'UNKNOWN', 'KNOWN') a from dual; -- UNKNOWN
select decode( abs(null), null, 'UNKNOWN', 'KNOWN') a from dual; -- UNKNOWN
select decode( sign(null), null, 'UNKNOWN', 'KNOWN') a from dual; -- UNKNOWNThings are different with concatenation: you can add NULL to a string, and it won't change it. Such is the policy of double standards.
select null ||'AA'|| null ||'BB'|| null from dual; -- AABBNULL and Aggregate Functions
Almost all aggregate functions, with the exception of COUNT (and even then, not always), ignore null values during calculations. If they didn't, then the first NULL that came along would lead the function result to an unknown value. Take, for example, the SUM function, which needs to sum the series (1, 3, null, 2). If it took into account empty values, then we would get the following sequence of actions:
1 + 3 = 4; 4 + null = null; null + 2 = null.
It is unlikely that you will be satisfied with such a calculation when calculating aggregates because you probably did not want to get it.
Table with data. Used below many times:
create table agg( id int, n int );
insert into agg values( 1, 1 );
insert into agg values( 2, 3 );
insert into agg values( 3, null );
insert into agg values( 4, 2 );
commit;Empty values are ignored by aggregates:
select sum(n) from agg; -- 6The COUNT row count function, if used as COUNT(*) or COUNT(constant), will count null values. However, if it is used as COUNT(expression), then null values will be ignored.
with a constant:
select count(*) from agg; -- 4
select count(1+1) from agg; -- 4
select count(user) from agg; -- 4with expression:
select count(n) from agg; -- 3
select count(id) from agg; -- 4
select count(abs(n)) from agg; -- 3Also, you should be careful with functions like AVG. Because it will ignore null values, the result for field N will be (1+3+2)/3, not (1+3+2)/4. Perhaps you do not need such an average calculation. To solve such problems, there is a standard solution — use the NVL function:
select avg(n) from agg; -- (1 + 3 + 2) / 3 = 2
select avg(nvl(n,0)) from agg; -- (1 + 3 + 0 + 2) / 4 = 1.5Aggregate functions return UNKNOWN if they are applied to an empty dataset or if it consists of only NULLs. The exceptions are the REGR_COUNT and COUNT(expression) functions designed to count the number of rows. They will return zero in the cases listed above.
A data set of only NULLs:
select sum(n) from agg where n is null; -- UNKNOWN
select avg(n) from agg where n is null; -- UNKNOWN
select regr_count(n,n) from agg where n is null; -- 0
select count(n) from agg where n is null; -- 0Empty dataset:
select sum(n) from agg where 1 = 0; -- UNKNOWN
select avg(n) from agg where 1 = 0; -- UNKNOWN
select regr_count(n,n) from agg where 1 = 0; -- 0
select count(n) from agg where 1 = 0; -- 0NULL in Indexes
When creating an index, Oracle includes entries in the index structures for all rows containing NULL values in the indexed column. Such records are called NULL records. This allows you to quickly identify rows where the corresponding column contains NULL, which can be useful when executing queries with NULL or non-NULL conditions.
- Using
NULLvalues in regular indexes: Regular indexes include references to table rows, indicating the values of the indexed column and the correspondingROWIDsof these rows. For rows withNULLvalues, the index stores a specialNULLmarker to indicate the presence ofNULLin the indexed column. This allows Oracle to quickly findNULLrows in an indexed column. - Using
NULLvalues in composite indexes: In composite indexes that index multiple columns, each column has its own index structure. Thus, for composite indexes containingNULLcolumns, aNULLtoken will be present for each column containingNULLs. - Functional indexes and
NULLs: Functional indexes are built on the basis of expressions or functions on table columns. If the function allowsNULLarguments, then the index will include entries forNULLfunction arguments. This can be useful when optimizing queries that use nullable functions.
Bad Practices
- Indexing columns with low
NULLcardinality: Creating indexes on columns where most values areNULLcan result in suboptimal index usage and poor query performance. This is because indexes with lowNULLcardinality will take up a lot of space in the database, and queries with such indexes can be slower than full table scans. - Indexing non-selective columns with
NULL: Non-selective columns are columns that have few unique values or many duplicateNULLvalues. Creating indexes on such columns may not be practical, as such indexes may not provide a significant improvement in query performance and require more resources to maintain. - Using
NULLIndexes withIS NOT NULLOperators: If the query contains conditions with theIS NOT NULLoperator, thenNULLindexes will not be used by the query optimizer. Thus, usingNULLindexes in such queries will be useless and waste resources on creating and maintaining unnecessary indexes. - Indexing large text columns with
NULL: Creating indexes on large text columns that may containNULLvalues can be disadvantageous due to the large amount of data that must be stored in the index. Indexing such columns can significantly increase the size of the index and slow query performance. - Overuse of functional indexes with
NULL: Functional indexes can be useful for optimizing queries with functions that allow null arguments. However, excessive use ofNULLfunctional indexes can lead to undesired index size and performance degradation. - Irrelevant and unused indexes with
NULL: Stale and unusedNULLindexes remain in the database, consume space, and need to be updated when the data changes. Such indexes should be parsed and removed regularly to reduce system load and optimize performance.
It's important to keep in mind that using NULL in indexes can be useful, but not always. When creating indexes with NULL, you should pay attention to the cardinality of NULL values in columns and their actual use in queries. This will help avoid unnecessary indexes and improve database performance.
Good Practices
- Indexing columns with high
NULLcardinality: Creating indexes on columns with highNULLcardinality can be beneficial because indexes allow you to quickly identify rows withNULLvalues. This is especially useful when queries frequently use null or non-null conditions in a column. - Indexing columns commonly used in queries: Creating indexes on columns that are frequently used in queries can greatly improve query performance. Indexes can help speed up data retrieval and reduce query execution time.
- Using Functional Indexes with
NULL: Functional indexes can be useful for optimizing queries with functions that allow null arguments. Such indexes can improve the performance of queries that use functions withNULLarguments. - Using indexes with
NULLin combination withIS NULL:NULLindexes can be very useful when using theIS NULLoperator to find rows withNULLvalues. Such indexes allow you to quickly find all rows withNULLin the corresponding columns.
Performance Analysis Using NULL Indexes
When creating indexes with NULL, it is recommended that you analyze query performance and compare it to performance without indexes. This will help you determine which NULL indexes actually improve query performance and are justified in your particular situation.
- Periodic index maintenance:
NULLindexes, like normal indexes, require periodic maintenance. Regularly updating index statistics will help the query optimizer evaluate query execution plans correctly and avoid unnecessary operations. - Removing unused
NULLindexes: UnusedNULLindexes should be parsed and dropped regularly to reduce system load and optimize database performance. - Control over updates and inserts: When using
NULLindexes, you need to control the update and insert operations.NULLindexes can impact the performance of such operations, so it's important to consider them when designing and optimizing queries.
Following these good practices will effectively use NULLs in Oracle indexes, improve query performance, and reduce the impact on the database. Using NULL indexes wisely will help you get the most out of indexes and increase database efficiency.
Opinions expressed by DZone contributors are their own.
Comments