Questioning an Image Database With Local AI/LLM on Ollama and Spring AI
In this article, the reader will learn how to query an image database with natural language. Read further to learn more!
Join the DZone community and get the full member experience.
Join For FreeThe AIDocumentLibraryChat project has been extended to include an image database that can be questioned for images. It uses the LLava model of Ollama, which can analyze images. The image search uses embeddings with the PGVector extension of PostgreSQL.
Architecture
The AIDocumentLibraryChat project has this architecture:
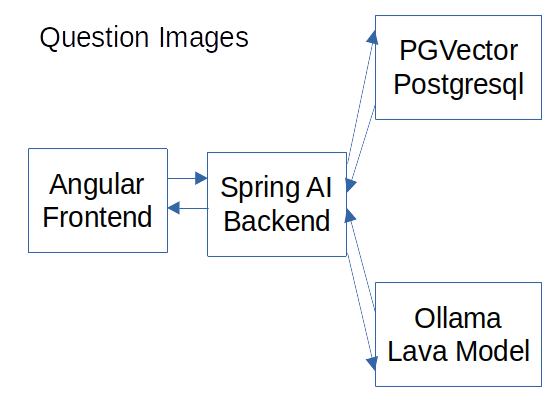
The Angular front-end shows the upload and question features to the user. The Spring AI Backend adjusts the model's image size, uses the database to store the data/vectors, and creates the image descriptions with the LLava model of Ollama.
The flow of image upload/analysis/storage looks like this:
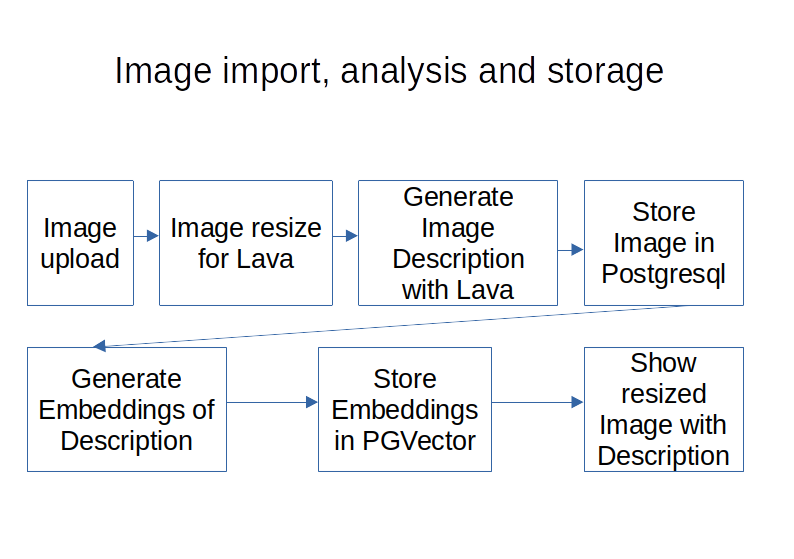
The image is uploaded with the front-end. The back-end resizes it to a format the LLava model can process. The LLava model then generates a description of the image based on the provided prompt. The resized image and the metadata are stored in a relational Table of PostgreSQL. The image description is then used to create Embeddings. The Embeddings are stored with the description in the PGVector database with metadata to find the corresponding row in the PostgreSQL Table. Then the image description and the resized image are shown in the frontend.
The flow of image questions looks like this:
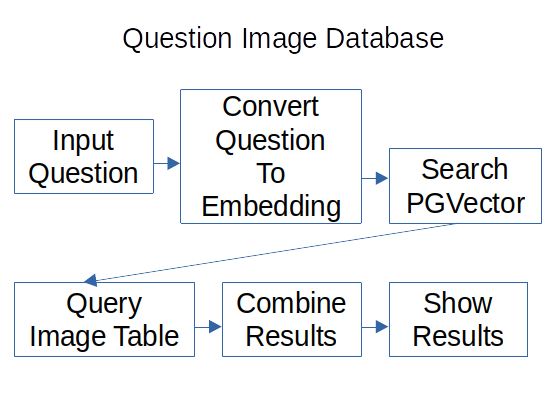
The user can input the question in the front-end. The backend converts the question to Embeddings and searches the PGVector database for the nearest entry. The entry has the row ID of the image table with the image and the metadata. The image table data is queried combined with the description and shown to the user.
Backend
To run the PGVector database and the Ollama framework the files runPostgresql.sh and runOllama.sh contain Docker commands.
The backend needs these entries in application-ollama.properties:
# image processing
spring.ai.ollama.chat.model=llava:34b-v1.6-q6_K
spring.ai.ollama.chat.options.num-thread=8
spring.ai.ollama.chat.options.keep_alive=1sThe application needs to be built with Ollama support (property: ‘useOllama’) and started with the ‘ollama’ profile and these properties need to be activated to enable the LLava model and set a useful keep_alive. The num_thread is only needed if Ollama does not select the right amount automatically.
The Controller
The ImageController contains the endpoints:
@RestController
@RequestMapping("rest/image")
public class ImageController {
...
@PostMapping("/query")
public List<ImageDto> postImageQuery(@RequestParam("query") String
query,@RequestParam("type") String type) {
var result = this.imageService.queryImage(query);
return result;
}
@PostMapping("/import")
public ImageDto postImportImage(@RequestParam("query") String query,
@RequestParam("type") String type,
@RequestParam("file") MultipartFile imageQuery) {
var result =
this.imageService.importImage(this.imageMapper.map(imageQuery, query),
this.imageMapper.map(imageQuery));
return result;
}
}The query endpoint contains the ‘postImageQuery(…)’ method that receives a form with the query and the image type and calls the ImageService to handle the request.
The import endpoint contains the ‘postImportImage(…)’ method that receives a form with the query(prompt), the image type, and the file. The ImageMapper converts the form to the ImageQueryDto and the Image entity and calls the ImageService to handle the request.
The Service
The ImageService looks like this:
@Service
@Transactional
public class ImageService {
...
public ImageDto importImage(ImageQueryDto imageDto, Image image) {
var resultData = this.createAIResult(imageDto);
image.setImageContent(resultData.imageQueryDto().getImageContent());
var myImage = this.imageRepository.save(image);
var aiDocument = new Document(resultData.answer());
aiDocument.getMetadata().put(MetaData.ID, myImage.getId().toString());
aiDocument.getMetadata().put(MetaData.DATATYPE,
MetaData.DataType.IMAGE.toString());
this.documentVsRepository.add(List.of(aiDocument));
return new ImageDto(resultData.answer(),
Base64.getEncoder().encodeToString(resultData.imageQueryDto()
.getImageContent()), resultData.imageQueryDto().getImageType());
}
public List<ImageDto> queryImage(String imageQuery) {
var aiDocuments = this.documentVsRepository.retrieve(imageQuery,
MetaData.DataType.IMAGE, this.resultSize.intValue())
.stream().filter(myDoc -> myDoc.getMetadata()
.get(MetaData.DATATYPE).equals(DataType.IMAGE.toString()))
.sorted((myDocA, myDocB) ->
((Float) myDocA.getMetadata().get(MetaData.DISTANCE))
.compareTo(((Float) myDocB.getMetadata().get(MetaData.DISTANCE))))
.toList();
var imageMap = this.imageRepository.findAllById(
aiDocuments.stream().map(myDoc ->
(String) myDoc.getMetadata().get(MetaData.ID)).map(myUuid ->
UUID.fromString(myUuid)).toList())
.stream().collect(Collectors.toMap(myDoc -> myDoc.getId(),
myDoc -> myDoc));
return imageMap.entrySet().stream().map(myEntry ->
createImageContainer(aiDocuments, myEntry))
.sorted((containerA, containerB) ->
containerA.distance().compareTo(containerB.distance()))
.map(myContainer -> new ImageDto(myContainer.document().getContent(),
Base64.getEncoder().encodeToString(
myContainer.image().getImageContent()),
myContainer.image().getImageType())).limit(this.resultSize)
.toList();
}
private ImageContainer createImageContainer(List<Document> aiDocuments,
Entry<UUID, Image> myEntry) {
return new ImageContainer(
createIdFilteredStream(aiDocuments, myEntry)
.findFirst().orElseThrow(),
myEntry.getValue(),
createIdFilteredStream(aiDocuments, myEntry).map(myDoc ->
(Float) myDoc.getMetadata().get(MetaData.DISTANCE))
.findFirst().orElseThrow());
}
private Stream<Document> createIdFilteredStream(List<Document> aiDocuments,
Entry<UUID, Image> myEntry) {
return aiDocuments.stream().filter(myDoc -> myEntry.getKey().toString()
.equals((String) myDoc.getMetadata().get(MetaData.ID)));
}
private ResultData createAIResult(ImageQueryDto imageDto) {
if (ImageType.JPEG.equals(imageDto.getImageType()) ||
ImageType.PNG.equals(imageDto.getImageType())) {
imageDto = this.resizeImage(imageDto);
}
var prompt = new Prompt(new UserMessage(imageDto.getQuery(),
List.of(new Media(MimeType.valueOf(imageDto.getImageType()
.getMediaType()), imageDto.getImageContent()))));
var response = this.chatClient.call(prompt);
var resultData = new
ResultData(response.getResult().getOutput().getContent(), imageDto);
return resultData;
}
private ImageQueryDto resizeImage(ImageQueryDto imageDto) {
...
}
}In the ‘importImage(…)’ method the method ‘createAIResult(…)’ is called. It checks the image type and calls the ‘resizeImage(…)’ method to scale the image to a size that the LLava model supports. Then the Spring AI Prompt is created with the prompt text and the media with the image, media type, and the image byte array. Then the ‘chatClient’ calls the prompt and the response is returned in the ‘ResultData’ record with the description and the resized image. Then the resized image is added to the image entity and the entity is persisted. Now the AI document is created with the embeddings, description, and the image entity ID in the metadata. Then the ImageDto is created with the description, the resized image, and the image type and returned.
In the ‘queryImage(…)’ method the Spring AI Documents with the lowest distances are retrieved and filtered for AI documents of image type in the metadata. The Documents are then sorted for the lowest distance. Then the image entities with the metadata IDs of the Spring AI Documents are loaded. That enables the creation of the ImageDtos with the matching documents and image entities. The image is provided as a Base64 encoded string. That enables the MediaType the easy display of the image in an IMG tag.
To display a Base64 Png image you can use: ‘<img src=”data:image/png;base64,iVBORw0KG…” />’
Result
The UI result looks like this:
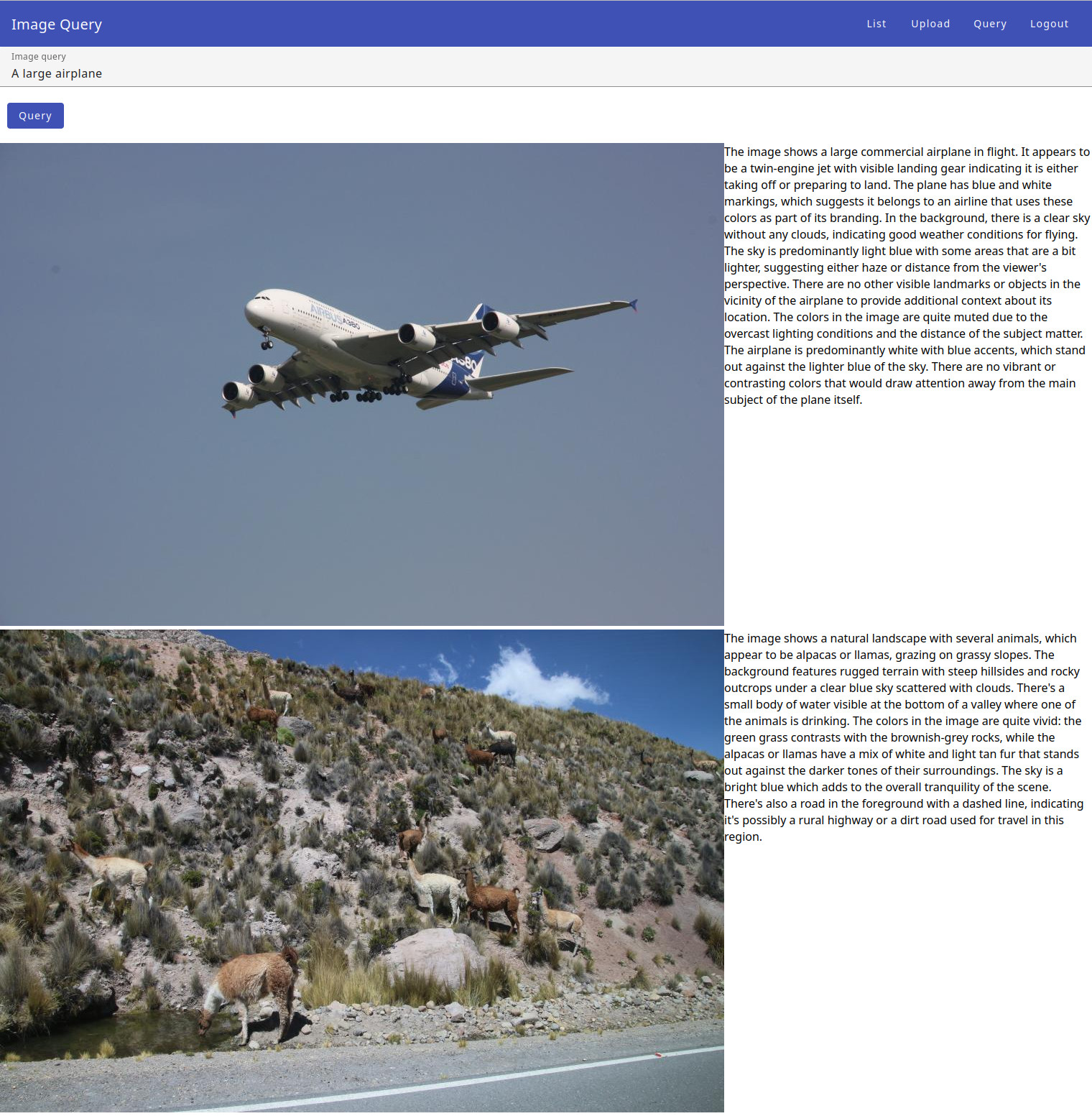
The application found the large airplane in the vector database using the embeddings. The second image was selected because of a similar sky. The search took only a fraction of a second.
Conclusion
The support of Spring AI and Ollama enables the use of the free LLava model. That makes the implementation of this image database easy. The LLava model generates good descriptions of the images that can be converted into embeddings for fast searching. Spring AI is missing support for the generate API endpoint, because of that the parameter ‘spring.ai.ollama.chat.options.keep_alive=1s’ is needed to avoid having old data in the context window. The LLava model needs GPU acceleration for productive use. The LLava is only used on import, which means the creation of the descriptions could be done asynchronously. The LLava model on a medium-powered Laptop runs on a CPU, for 5-10 minutes per image. Such a solution for image searching is a leap forward compared to previous implementations. With more GPUs or CPU support for AI such Image search solutions will become much more popular.
Published at DZone with permission of Sven Loesekann. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments