RAG vs. CAG: A Deep Dive into Context-Aware AI Generation Techniques
RAG retrieves external knowledge to ground AI responses, while CAG uses internal context for personalization—combine both for smarter, context-aware systems.
Join the DZone community and get the full member experience.
Join For FreeAs artificial intelligence systems become core components of everything from enterprise workflows to everyday tools, one thing is becoming crystal clear: context matters. It's no longer enough for a model to simply string together grammatically correct sentences. To truly add value—whether as a legal assistant, an AI tutor, or a customer support bot—an AI system needs to deliver the right answer at the right time, grounded in real-world knowledge and tuned to the situation at hand.
That’s where two key techniques come into play: Retrieval-Augmented Generation (RAG) and Context-Aware Generation (CAG). These two approaches offer different solutions to the same challenge: how to make large language models (LLMs) smarter, more reliable, and more useful.
RAG bridges the gap between generative models and real-time information by pulling in relevant documents from a knowledge base before generating a response. It’s like giving your model a stack of reference material moments before it starts talking. CAG, meanwhile, focuses on embedding relevant context—like conversation history, user preferences, or task-specific metadata—right into the generation process. Instead of looking outward for new information, CAG leverages what the system already knows or remembers about the user or task.
In this article, we’ll break down how each method works, what problems they solve, where they shine, and how they’re being used in the wild today.
RAG Explained: Making Models Smarter With On-the-Fly Knowledge
One of the biggest challenges with LLMs is that their knowledge is static. They're trained on massive amounts of data, but once that training is done, they can't adapt to new information—unless you retrain them, which is slow, expensive, and rarely practical. This leads to a major issue known as hallucination, where models confidently output incorrect or outdated facts.
Retrieval-Augmented Generation (RAG) solves this by plugging the model into a live source of knowledge. Here’s the idea: when a user submits a prompt, the system first sends that query to a retriever. This retriever searches an external document store—like a vector database or search index—and fetches the most relevant results. These documents are then combined with the original prompt to create an enriched input that’s sent to the language model. The model uses this combined context to generate a response that’s not only coherent, but also grounded in real, up-to-date information.
RAG pipeline in action:
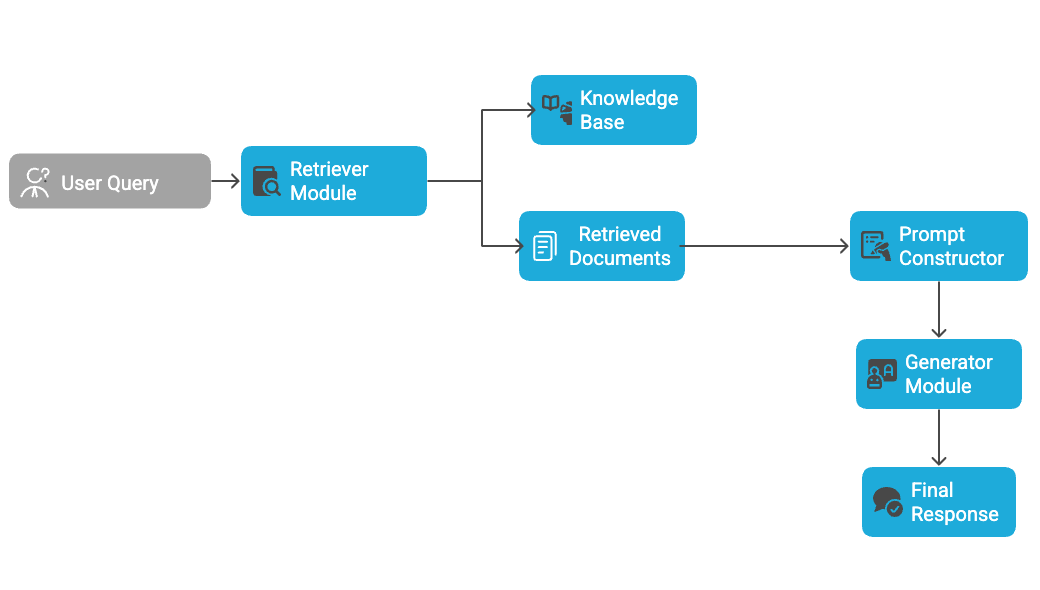
This modular structure is why RAG is so flexible. You can swap out the document store or retriever depending on your domain (e.g., use Pinecone for support articles, Elasticsearch for financial reports), and you never have to retrain the model to reflect new information.
Why Use RAG?
- Factual grounding: Reduces hallucination by basing responses on source material.
- Easy to update: Swap in new documents at any time without touching the model.
- Domain-specific answers: Great for legal, medical, technical, or regulatory contexts.
- Explainability: Enables citations and traceability in responses.
CAG Explained: Teaching Models to Pay Attention to Context
While RAG is great for injecting external knowledge, it doesn’t handle one important thing: what the model already knows about the user, task, or conversation. That’s where Context-Aware Generation (CAG) comes in.
CAG techniques aim to make LLMs more “aware” of their environment. Instead of reaching out to fetch new data, they focus on embedding relevant context into the generation process. This could include previous chat messages, system roles or instructions, metadata about the user, or even memory modules that store persistent data across sessions.
There are many ways to implement CAG, depending on your needs:
| Technique | What It Does | Tools Used |
|---|---|---|
| Prompt chaining | Carries over past inputs/outputs | LangChain, LlamaIndex |
| Instruction prompting | Defines behavior or tone with role/system messages | OpenAI system prompts |
| Embedding memory | Stores past interactions as retrievable embeddings | Pinecone, Redis |
| Fine-tuning | Trains models on custom data or tone | Hugging Face Transformers |
| LoRA / Adapters | Injects domain or user-specific behavior efficiently | QLoRA, PEFT |
CAG pipeline in action:
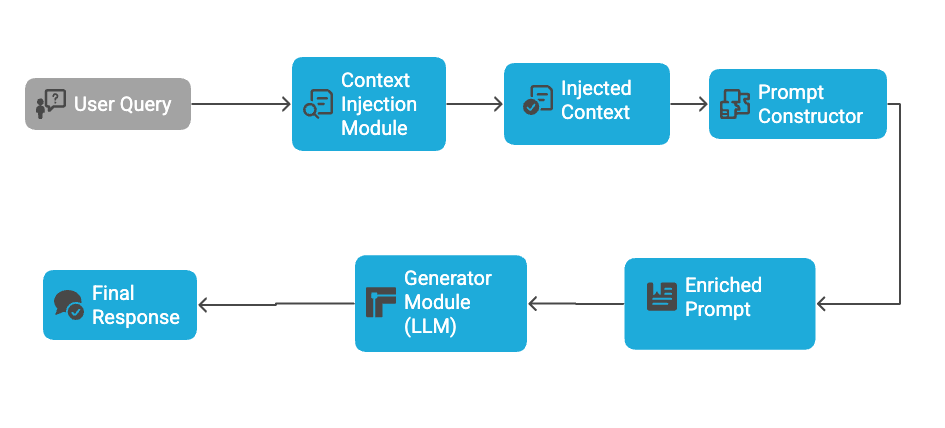 In practice, CAG is ideal for personalized experiences—like AI writing assistants, virtual therapists, or sales bots that need to maintain context across a conversation.
In practice, CAG is ideal for personalized experiences—like AI writing assistants, virtual therapists, or sales bots that need to maintain context across a conversation.
Why Use CAG?
- Continuity: Keeps the conversation or task flow consistent.
- Personalization: Adapts tone, style, or content based on user preferences.
- Low latency: No retrieval step means faster responses.
RAG vs. CAG: Key Differences at a Glance
| Feature | RAG | CAG |
|---|---|---|
| Source of context | External document retrieval | Internal session memory / prompt injection |
| Model architecture | Retriever + Generator | Unified prompt-aware model |
| Latency | Medium to high (due to retrieval) | Low (fast inference) |
| Best for | Knowledge-grounded Q&A | Personalized, ongoing user interactions |
| Explainability | Strong (can cite sources) | Weaker (depends on context injection) |
| Complexity | Higher (needs vector DB, retriever setup) | Moderate (prompt or memory handling) |
| Failure risks | Poor retrieval = poor output | Context window overflow or drift |
Where Each One Shines
Use RAG when you need:
- Support bots that pull answers from up-to-date articles or FAQs
- Legal or medical assistants referencing formal documentation
- Internal research copilots querying knowledge bases
Use CAG when you want:
- Long-term memory in productivity tools or agents
- AI storytelling or creative writing that remembers plot or tone
- Sales agents adapting pitch and language to each client
Combine Them: Hybrid Systems Are the Future
In most serious AI systems today, you don’t have to pick between RAG and CAG—you can use both. Many modern tools, like Microsoft Copilot, Notion AI, and Salesforce Einstein GPT, combine these strategies to create truly powerful assistants.
Here’s how it works: CAG handles memory, such as the user’s goals, past actions, and tone, while RAG brings in real-time facts, like documentation or product updates. The LLM takes both kinds of context and merges them into a single, coherent response.
This hybrid setup is already being used in:
- Customer support bots that remember past tickets and cite the latest help docs
- AI tutors that remember the user’s learning goals and fetch content on-demand
- Enterprise copilots that blend personalization with structured document access
Engineering Considerations
| Factor | RAG | CAG |
|---|---|---|
| Token usage | Retrieved docs add to prompt | History/context adds to prompt |
| Infrastructure | Requires retriever + vector DB setup | Needs prompt memory or caching logic |
| Cost | Higher due to search + LLM usage | Moderate, depending on implementation |
| Maintainability | Easy to update documents | Harder to design long-term memory |
| Training need | No retraining needed | May benefit from fine-tuning |
What’s Next for RAG and CAG?
Both techniques are evolving fast.
In RAG, expect to see:
- Multimodal retrieval (images, charts, PDFs—not just text)
- Streaming RAG for real-time monitoring and alert systems
- Agentic RAG, combining document fetching with reasoning chains
In CAG, we’ll see:
- Support for longer context windows (up to 1 million tokens!)
- Persistent memory APIs (like ChatGPT’s memory feature)
- Context compression techniques to avoid prompt bloat
Conclusion: When (and Why) to Use RAG, CAG, or Both
When building modern AI systems, context is no longer optional—it’s foundational. RAG and CAG give you two powerful ways to give your models the context they need to be useful and reliable.
- Choose RAG when factual accuracy and document grounding matter most.
- Choose CAG when you need memory, personalization, or conversational continuity.
- Combine both to build systems that are both informed and intelligent.
In short:
- Use RAG when knowledge matters.
- Use CAG when context matters.
- Use both when everything matters.
References
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., & Kiela, D. (2020, May 22). Retrieval-Augmented Generation for Knowledge-Intensive NLP tasks. arXiv.org. https://arxiv.org/abs/2005.11401
- Retrieval Augmented Generation (RAG). (n.d.). Pinecone. https://www.pinecone.io/learn/retrieval-augmented-generation/
- Memory and new controls for ChatGPT. (2024, February 13). OpenAI. https://openai.com/index/memory-and-new-controls-for-chatgpt/
- RAG. (n.d.). https://huggingface.co/docs/transformers/en/model_doc/rag
- [Beta] Memory | ️ LangChain. (n.d.). https://python.langchain.com/v0.1/docs/modules/memory/
Opinions expressed by DZone contributors are their own.
Comments