Real-Time Data Batching With Apache Camel
If you want your message flow to scale, it takes some work. This proposal, using Apache Camel, let's you handle high volume requests with a variety of databases.
Join the DZone community and get the full member experience.
Join For FreeOver the past few years, I've been working with high volume real-time message based applications that process and store time-series data. As we scale these systems out, resource usage becomes increasingly important — and various trade-offs have to be considered.
From a storage perspective, many of the NoSQL techs claim to handle mass volumes of parallel requests and data with ease. In the real world, however, most techs have similar system resource limitations (threading, CPU, memory, I/O, etc) that all contribute to latency/stability issues. Though many symptoms can be masked by horizontal scaling, at the end of the day, the more efficiently your applications use resources, the better things scale out.
One approach is to batch process data to more efficiently use resources (threads/connections) by reducing per message/request overhead. This is a widely used pattern for at-rest/bulk data processing, but not often considered for real-time/event driven processing. As it turns out, this pattern is often a best practice (or even required) for reasonable performance from external systems and storage techs when working with high volume data.
I first encountered this use case when storing high volume messaging in Oracle. The issue is that transaction commits are expensive and committing a single message at a time simply doesn't scale. Instead, we switched to aggregating messages in memory and then passed these to Oracle via an array. The net result was dramatically reduced load against the database, negligible delays in processing data and a theoretical increased chance of message loss...overall, this addressed our performance issues with relatively little impact.
Then, as we moved into NoSQL solutions (Cassandra, HDFS, ElasticSearch, etc), I revisited the need for batching. It was obvious that the same batching strategy still applied to these new techs as well.
Luckily, we are working with Apache Camel, and its implementation of EIPs (Enterprise Integration Patterns) makes solving these types of issues fairly straightforward. In particular, the split and aggregator patterns are designed for just this type of message flow.
For example, let's say I have three systems that process messages...A, B, C. System A produces messages and sends them to system B. System B does some processing and then sends them to system C for final processing.

In Camel, this is expressed by the following simple route (assuming ActiveMQ is used as a message bus in between systems)
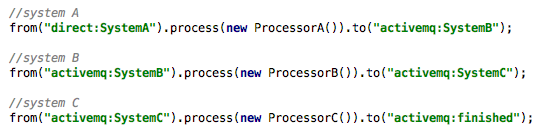
Now, if we find that system B requires batch sizes of 100, I can easily batch these together using a simple aggregator as follows...
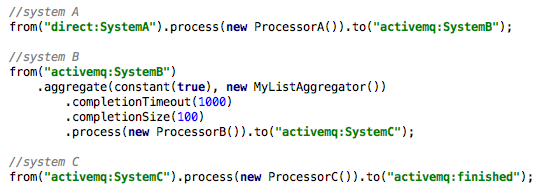
Given the config above, we'll pass on a batch after 100 messages are aggregated (completionSize) OR after 1000ms (completionTimeout). The latter is key to limiting the delay in processing when volume is low. Also note that the above would pass on a batch size of 100 to system C.
Now, let's assume system C prefers a batch size of 10 and must get groups for the same accountId. Here are the changes required
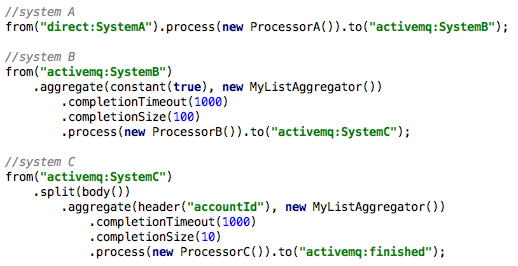
Notice that in the system C route, I now call split(body()) which will split the incoming batch from system B and allow us to re-aggregate per the requirements for this system. Also, the header("accountId")in place of constant(true) tells the aggregator to build batches/groups for similar accountId values only and still complete after 10 are received or after 1000ms.
As you can see, these are very flexible and easy to implement patterns for message flow. That said, you do have to give some consideration to memory/CPU usage and overall message reliability requirements when using these.
Overall, I've used this pattern to successfully scale out high volume requests to Oracle, Cassandra, HDFS, and ElasticSearch.
Opinions expressed by DZone contributors are their own.
Comments