Setting Up Data Pipelines With Snowflake Dynamic Tables
This is a walkthrough of the process for building an automated data pipeline with dynamic table capabilities in Snowflake for various refresh frequencies.
Join the DZone community and get the full member experience.
Join For FreeThis guide walks through the steps to set up a data pipeline specifically for near-real-time or event-driven data architectures and continuously evolving needs. This guide covers each step, from setup to data ingestion, to the different layers of the data platform, and deployment and monitoring, to help manage large-scale applications effectively.
Prerequisites
- Expertise in basic and complex SQL for scripting
- Experience with maintaining data pipelines and orchestration
- Access to a Snowflake for deployment
- Knowledge of ETL frameworks for efficient design
Introduction
Data pipeline workloads are an integral part of today’s world, and maintaining these workloads needs massive effort, and it's cumbersome. A solution is provided within Snowflake, which is called dynamic tables.
Dynamic tables provide an automated, efficient way to manage and process data transformations within the platform. The automated approach to dynamic tables streamlines data freshness, reduces manual intervention, and optimizes data ETL/ELT processes and data refresh needs.
Dynamic tables are part of Snowflake that allow users to design tables with automatic data refresh and transformation schedules. They are very handy for streaming data and incremental processing without requiring complex orchestration and handshakes across multiple systems for orchestration.
A straightforward process flow is illustrated below.
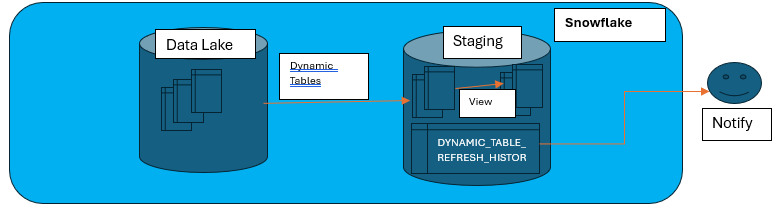
Key Features
- Automated data refresh: Data in dynamic tables is updated based on a defined refresh frequency.
- Incremental data processing: Supports efficient change tracking, reducing computation overhead.
- Optimal resource management: Reduces/eliminates manual intervention and ensures optimized resource utilization.
- Schema evolution: Allows flexibility to manage schema changes.
Setup Process Walkthrough
The simple use case we discuss here is setting up a dynamic table process on a single-source table. The step-by-step setup follows.
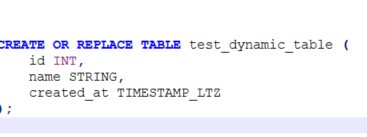
Step 1: Creating a Source Table
Create a source table test_dynamic_table:
Step 2: Create a Stream (Change Data Capture)
Stream tracks the changes (inserts, updates, deletes) made to a table. This allows for capturing the incremental changes to the data, which can then be applied dynamically.

SHOW_INITIAL_ROWS = TRUE: This parameter captures the initial state of the table data as well.ON TABLE test_dynamic_table: This parameter specifies which table the stream is monitoring.
Step 3: Create a Task to Process the Stream Data
A task allows us to schedule the execution of SQL queries. You can use tasks to process or update data in a dynamic table based on the changes tracked by the stream.
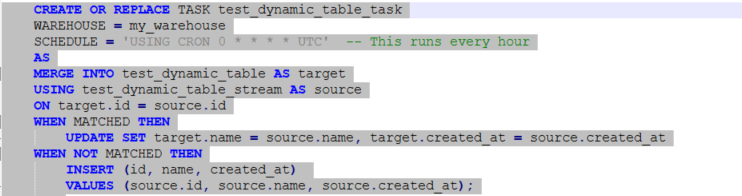
- The
MERGEstatement synchronizes thetest_dynamic_tablewith the changes captured intest_dynamic_table_stream. - The task runs on a scheduled basis (in this case, every hour), but can be modified as needed.
- The task checks for updates, inserts, and even deletes based on the changes in the stream and applies them to the main table.
Step 4: Enable the Task
After the task is created, enable it to start running as per the defined schedule.
Step 5: Monitor the Stream and Tasks
Monitor the stream and the task to track changes and ensure they are working as expected. Use streams to track the changes in the data. Use tasks to periodically apply those changes to the table.
Best Practices
- Choose optimal refresh intervals: Adjust the
TARGET_LAGbased on business needs and timelines. - Monitor performance: Use Snowflake’s monitoring tools to track the refresh efficiency of all the data pipelines.
- Clustering and partitioning: Optimize query performance with appropriate data organization.
- Ensure data consistency: Use appropriate data validation and schema management practices.
- Analyze cost metrics: Use Snowflake’s cost reporting features to monitor and optimize spending.
- Task scheduling: Consider your task schedule carefully. If you need near real-time updates, set the task to run more frequently (e.g., every minute).
- Warehouse sizing: Ensure your Snowflake warehouse is appropriately sized to handle the load of processing large streams of data.
- Data retention: Snowflake streams have a retention period, so be mindful of that when designing your dynamic table solution.
Limitations
- UDF (user-defined functions), masking policy, row-level restrictions, and non-deterministic functions like
current_timestampwon’t be supported for incremental load. - SCD TYPE2 and SNAPSHOT tables won’t support.
- Can’t alter table (Like include new column or changing data types)
Use Cases
- Real-time analytics: Keep data fresh for dashboards and reporting.
- ETL/ELT pipelines: Automate transformations for better efficiency.
- Change data capture (CDC): Track and process changes incrementally.
- Data aggregation: Continuously process and update summary tables.
- Cost savings with dynamic tables: Dynamic tables help reduce costs by optimizing Snowflake’s compute and storage resources.
- Reduced compute costs: Since dynamic tables support incremental processing, only changes are processed instead of full-table refreshes, lowering compute usage.
- Minimized data duplication: By avoiding redundant data transformations and storage of intermediate tables, storage costs are significantly reduced.
- Efficient resource allocation: The ability to set refresh intervals ensures that processing occurs only when necessary, preventing unnecessary warehouse usage.
- Effective pipeline management: The need for third-party orchestration tools is eliminated by reducing operational overhead and associated costs.
- Optimizing query performance: Faster query response and execution times due to pre-aggregated and structured data, reducing the need for expensive ad-hoc computations and processing times.
Conclusion
In real-world scenarios, traditional data pipelines are still widely used, often with a lot of human intervention and maintenance routines. To reduce complexity and for more efficient methodologies, dynamic tables provide a good solution. With a dynamic tables approach, organizations can improve data freshness, enhance performance, and streamline their data pipelines while achieving significant cost savings.
The development and maintenance costs can be significantly reduced, and more emphasis can be given to business improvements and initiatives. Several organizations have successfully leveraged dynamic tables in Snowflake to enhance their data operations and reduce costs.
Opinions expressed by DZone contributors are their own.
Comments