Building Event-Driven Data Pipelines in GCP
An analysis of modernizing event-driven data pipelines using BigQuery, Firestore, and Dataflow on Google Cloud Platform (GCP).
Join the DZone community and get the full member experience.
Join For FreeThe old-fashioned batch processing is not applicable in the current applications. Pipelines need to respond to events in real time when businesses rely on real-time data to track user behavior, to process financial transactions, or to monitor Internet of Things (IoT) devices, instead of hours after the event.
Why Event-Driven Architecture Matters
Event-driven processing versus batch processing is a paradigm shift in the flow of data through the systems. With batch pipelines, data is idle until it is run. In event pipelines, each change is followed by an immediate response. This difference is crucial in the development of fraud detection systems that demand sub-second response times or in systems that offer recommendations that are updated in real-time according to who is currently using it.
The hybrid approaches are also problematic in teams, where they are striving to introduce real-time functionality into batch systems. The design must be event-oriented at its base.
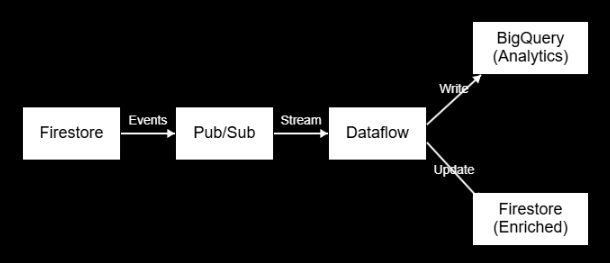
The Core Architecture Pattern
The majority of event-driven use cases are dealt with through a proven pattern. Firestore is used as the operational database where events are created. These changes are captured using Cloud Functions or Eventarc and sent to pub/sub topics. All these topics are subscribed to by dataflow and processed by dataflow to transform data on the fly and write the results to BigQuery to be analyzed, and optionally, enriched data is written back to Firestore.
Such architecture has proven robust in a number of applications, including e-commerce order processing and IoT sensor data aggregation.
Firestore as the Event Source
Firestore is not only a NoSQL database but also a natural event generator. Any update, document write, or delete can act as a downstream trigger. The trick is to come up with data models with events in mind. Records should be designed so that every modification is an event that makes sense to the business, rather than a simple database modification. One of the successful patterns is to separate raw event collections and processed state collections. Raw events are append-only, and, therefore, replaying and debugging is quite easy.
Pub/Sub as the Event Backbone
Pub/Sub separates producers of events and their consumers, which is essential in resilience. To ensure that Dataflow maintains its operation or performs some backlog processing, Firestore will write events to Pub/Sub without losing any data. The retention of messages that should last at least 24 hours is a breathing room during incidents.
The at-least-once delivery provides Dataflow jobs with the idempotency requirement. Transforms should be written in a way that they provide the same results when a similar event is processed twice.
Dataflow for Real-Time Transformations
The fundamental processing activity is carried out by Dataflow. All windowing, aggregations, enrichments, and joins take place here, and then the data is landed in BigQuery or back to Firestore. Checkpointing is automatically done under the streaming engine to ensure that there is no loss of progress when workers fail.

Pipelines are to be designed in distinct steps: input events are to be parsed, business logic transformations are to be done, time-based aggregations are to be windowed, and sinks are to be written. The stages are testable, thus making the debugging process less complicated.
Essential Patterns for Production
- Idempotency requirements: All transforms should have the same output with the same input. Writes should have deterministic IDs, and BigQuery tables should have the right clustering so that we do not create the same insert into a table.
- Event-time lag monitoring: The most significant metric is used to monitor the distance of lagging behind pipeline process activities. In the case of events marked at the moment of creation, but processed a few minutes afterwards, this delay will be actual latency. Pub/Sub lag and Dataflow watermark delay can be effectively monitored with cloud monitoring.
- Error handling strategy: Production systems need to have extensive error management. The invalid events must be identified as early as possible, recorded accordingly, and sent into dead letter queues. Downstream systems should be able to deal with partial failures without stalling the whole pipeline.
Operational Considerations
The process of events is never-ending, and recovery measures must always take into consideration always-on processing. Checkpointing, idempotency, and thorough monitoring are the main pillars and not extravagant features.
It is better to begin with something simple than to attempt to deal with all the edge cases at once. Minimal pipelines and continuous monitoring in the manufacturing process, combined with the complexity added when actual issues arise, appear to create more maintainable systems.
Conclusion
Data pipelines based on events radically change system responsiveness to data. They provide real-time insights, which cannot be matched by batch processing when constructed properly and with the help of BigQuery, Firestore, and Dataflow. The architecture needs discipline in the idempotency, monitoring, and failure management. One use case, demonstrated to be correct, followed by systematic expansion, is the surest way to achieve successful production. The cost of developing these systems properly is paid off whenever businesses require the information now and not tomorrow.
Opinions expressed by DZone contributors are their own.
Comments