Using Spring AI With AI/LLMs to Query Relational Databases
Explore how the AIDocumentLibraryChat project has been extended to support questions for searching relational databases.
Join the DZone community and get the full member experience.
Join For FreeThe AIDocumentLibraryChat project has been extended to support questions for searching relational databases. The user can input a question and then the embeddings search for relevant database tables and columns to answer the question. Then the AI/LLM gets the database schemas of the relevant tables and generates based on the found tables and columns a SQL query to answer the question with a result table.
Dataset and Metadata
The open-source dataset that is used has 6 tables with relations to each other. It contains data about museums and works of art. To get useful queries of the questions, the dataset has to be supplied with metadata and that metadata has to be turned in embeddings.
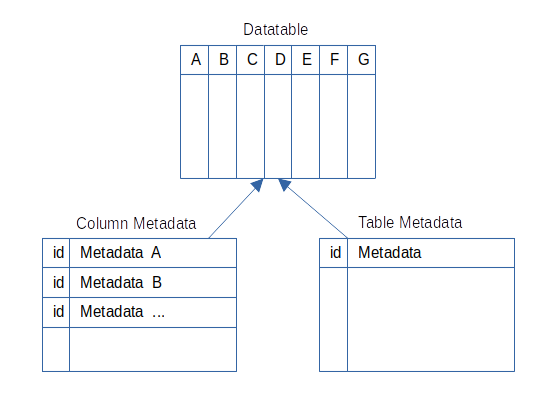
To enable the AI/LLM to find the needed tables and columns, it needs to know their names and descriptions. For all datatables like the museum table, metadata is stored in the column_metadata and table_metadata tables. Their data can be found in the files: column_metadata.csv and table_metadata.csv. They contain a unique ID, the name, the description, etc. of the table or column. That description is used to create the embeddings the question embeddings are compared with. The quality of the description makes a big difference in the results because the embedding is more precise with a better description. Providing synonyms is one option to improve the quality. The Table Metadata contains the schema of the table to add only the relevant table schemas to the AI/LLM prompt.
Embeddings
To store the embeddings in Postgresql, the vector extension is used. The embeddings can be created with the OpenAI endpoint or with the ONNX library that is provided by Spring AI. Three types of embeddings are created:
TabledescriptionembeddingsColumndescriptionembeddingsRowcolumnembeddings
The Tabledescription embeddings have a vector based on the table description and the embedding has the tablename, the datatype = table, and the metadata id in the metadata.
The Columndescription embeddings have a vector based on the column description and the embedding has the tablename, the dataname with the column name, the datatype = column, and the metadata id in the metadata.
The Rowcolumn embeddings have a vector based on the content row column value. That is used for the style or subject of an artwork to be able to use the values in the question. The metadata has the datatype = row, the column name as dataname, the tablename, and the metadata id.
Implement the Search
The search has 3 steps:
- Retrieve the embeddings
- Create the prompt
- Execute query and return result
Retrieve the Embeddings
To read the embeddings from the Postgresql database with the vector extension, Spring AI uses the VectorStore class in the DocumentVSRepositoryBean:
@Override
public List<Document> retrieve(String query, DataType dataType) {
return this.vectorStore.similaritySearch(
SearchRequest.query(query).withFilterExpression(
new Filter.Expression(ExpressionType.EQ,
new Key(MetaData.DATATYPE), new Value(dataType.toString()))));
}The VectorStore provides a similarity search for the query of the user. The query is turned in an embedding and with the FilterExpression for the datatype in the header values, the results are returned.
The TableService class uses the repository in the retrieveEmbeddings method:
private EmbeddingContainer retrieveEmbeddings(SearchDto searchDto) {
var tableDocuments = this.documentVsRepository.retrieve(
searchDto.getSearchString(), MetaData.DataType.TABLE,
searchDto.getResultAmount());
var columnDocuments = this.documentVsRepository.retrieve(
searchDto.getSearchString(), MetaData.DataType.COLUMN,
searchDto.getResultAmount());
List<String> rowSearchStrs = new ArrayList<>();
if(searchDto.getSearchString().split("[ -.;,]").length > 5) {
var tokens = List.of(searchDto.getSearchString()
.split("[ -.;,]"));
for(int i = 0;i<tokens.size();i = i+3) {
rowSearchStrs.add(tokens.size() <= i + 3 ? "" :
tokens.subList(i, tokens.size() >= i +6 ? i+6 :
tokens.size()).stream().collect(Collectors.joining(" ")));
}
}
var rowDocuments = rowSearchStrs.stream().filter(myStr -> !myStr.isBlank())
.flatMap(myStr -> this.documentVsRepository.retrieve(myStr,
MetaData.DataType.ROW, searchDto.getResultAmount()).stream())
.toList();
return new EmbeddingContainer(tableDocuments, columnDocuments,
rowDocuments);
}First, documentVsRepository is used to retrieve the document with the embeddings for the tables/columns based on the search string of the user. Then, the search string is split into chunks of 6 words to search for the documents with the row embeddings. The row embeddings are just one word, and to get a low distance, the query string has to be short; otherwise, the distance grows due to all the other words in the query. Then the chunks are used to retrieve the row documents with the embeddings.
Create the Prompt
The prompt is created in the TableService class with the createPrompt method:
private Prompt createPrompt(SearchDto searchDto,
EmbeddingContainer documentContainer) {
final Float minRowDistance = documentContainer.rowDocuments().stream()
.map(myDoc -> (Float) myDoc.getMetadata().getOrDefault(MetaData.DISTANCE,
1.0f)).sorted().findFirst().orElse(1.0f);
LOGGER.info("MinRowDistance: {}", minRowDistance);
var sortedRowDocs = documentContainer.rowDocuments().stream()
.sorted(this.compareDistance()).toList();
var tableColumnNames = this.createTableColumnNames(documentContainer);
List<TableNameSchema> tableRecords = this.tableMetadataRepository
.findByTableNameIn(tableColumnNames.tableNames()).stream()
.map(tableMetaData -> new TableNameSchema(tableMetaData.getTableName(),
tableMetaData.getTableDdl())).collect(Collectors.toList());
final AtomicReference<String> joinColumn = new AtomicReference<String>("");
final AtomicReference<String> joinTable = new AtomicReference<String>("");
final AtomicReference<String> columnValue =
new AtomicReference<String>("");
sortedRowDocs.stream().filter(myDoc -> minRowDistance <= MAX_ROW_DISTANCE)
.filter(myRowDoc -> tableRecords.stream().filter(myRecord ->
myRecord.name().equals(myRowDoc.getMetadata()
.get(MetaData.TABLE_NAME))).findFirst().isEmpty())
.findFirst().ifPresent(myRowDoc -> {
joinTable.set(((String) myRowDoc.getMetadata()
.get(MetaData.TABLE_NAME)));
joinColumn.set(((String) myRowDoc.getMetadata()
.get(MetaData.DATANAME)));
tableColumnNames.columnNames().add(((String) myRowDoc.getMetadata()
.get(MetaData.DATANAME)));
columnValue.set(myRowDoc.getContent());
this.tableMetadataRepository.findByTableNameIn(
List.of(((String) myRowDoc.getMetadata().get(MetaData.TABLE_NAME))))
.stream().map(myTableMetadata -> new TableNameSchema(
myTableMetadata.getTableName(),
myTableMetadata.getTableDdl())).findFirst()
.ifPresent(myRecord -> tableRecords.add(myRecord));
});
var messages = createMessages(searchDto, minRowDistance, tableColumnNames,
tableRecords, joinColumn, joinTable, columnValue);
Prompt prompt = new Prompt(messages);
return prompt;
}First, the min distance of the rowDocuments is filtered out. Then a list row of documents sorted by distance is created.
The method createTableColumnNames(...) creates the tableColumnNames record that contains a set of column names and a list of table names. The tableColumnNames record is created by first filtering for the 3 tables with the lowest distances. Then the columns of these tables with the lowest distances are filtered out.
Then the tableRecords are created by mapping the table names to the schema DDL strings with the TableMetadataRepository.
Then the sorted row documents are filtered for MAX_ROW_DISTANCE and the values joinColumn, joinTable, and columnValue are set. Then the TableMetadataRepository is used to create a TableNameSchema and add it to the tableRecords.
Now the placeholders in systemPrompt and the optional columnMatch can be set:
private final String systemPrompt = """
...
Include these columns in the query: {columns} \n
Only use the following tables: {schemas};\n
%s \n
""";
private final String columnMatch = """
Join this column: {joinColumn} of this table: {joinTable} where the column has this value: {columnValue}\n
""";The method createMessages(...) gets the set of columns to replace the {columns} placeholder. It gets tableRecords to replace the {schemas} placeholder with the DDLs of the tables. If the row distance was beneath the threshold, the property columnMatch is added at the string placeholder %s. Then the placeholders {joinColumn}, {joinTable}, and {columnValue} are replaced.
With the information about the required columns the schemas of the tables with the columns and the information of the optional join for row matches, the AI/LLM is able to create a sensible SQL query.
Execute Query and Return Result
The query is executed in the createQuery(...) method:
public SqlRowSet searchTables(SearchDto searchDto) {
EmbeddingContainer documentContainer = this.retrieveEmbeddings(searchDto);
Prompt prompt = createPrompt(searchDto, documentContainer);
String sqlQuery = createQuery(prompt);
LOGGER.info("Sql query: {}", sqlQuery);
SqlRowSet rowSet = this.jdbcTemplate.queryForRowSet(sqlQuery);
return rowSet;
}First, the methods to prepare the data and create the SQL query are called and then queryForRowSet(...) is used to execute the query on the database. The SqlRowSet is returned.
The TableMapper class uses the map(...) method to turn the result into the TableSearchDto class:
public TableSearchDto map(SqlRowSet rowSet, String question) {
List<Map<String, String>> result = new ArrayList<>();
while (rowSet.next()) {
final AtomicInteger atomicIndex = new AtomicInteger(1);
Map<String, String> myRow = List.of(rowSet
.getMetaData().getColumnNames()).stream()
.map(myCol -> Map.entry(
this.createPropertyName(myCol, rowSet, atomicIndex),
Optional.ofNullable(rowSet.getObject(
atomicIndex.get()))
.map(myOb -> myOb.toString()).orElse("")))
.peek(x -> atomicIndex.set(atomicIndex.get() + 1))
.collect(Collectors.toMap(myEntry -> myEntry.getKey(),
myEntry -> myEntry.getValue()));
result.add(myRow);
}
return new TableSearchDto(question, result, 100);
}First, the result list for the result maps is created. Then, rowSet is iterated for each row to create a map of the column names as keys and the column values as values. This enables returning a flexible amount of columns with their results. createPropertyName(...) adds the index integer to the map key to support duplicate key names.
Summary
Backend
Spring AI supports creating prompts with a flexible amount of placeholders very well. Creating the embeddings and querying the vector table is also very well supported.
Getting reasonable query results needs the metadata that has to be provided for the columns and tables. Creating good metadata is an effort that scales linearly with the amount of columns and tables. Implementing the embeddings for columns that need them is an additional effort.
The result is that an AI/LLM like OpenAI or Ollama with the "sqlcoder:70b-alpha-q6_K" model can answer questions like: "Show the artwork name and the name of the museum that has the style Realism and the subject of Portraits."
The AI/LLM can within boundaries answer natural language questions that have some fit with the metadata. The amount of embeddings needed is too big for a free OpenAI account and the "sqlcoder:70b-alpha-q6_K" is the smallest model with reasonable results.
AI/LLM offers a new way to interact with relational databases. Before starting a project to provide a natural language interface for a database, the effort and the expected results have to be considered.
The AI/LLM can help with questions of small to middle complexity and the user should have some knowledge about the database.
Frontend
The returned result of the backend is a list of maps with keys as column names and values column values. The amount of returned map entries is unknown, because of that the table to display the result has to support a flexible amount of columns. An example JSON result looks like this:
{"question":"...","resultList":[{"1_name":"Portrait of Margaret in Skating Costume","2_name":"Philadelphia Museum of Art"},{"1_name":"Portrait of Mary Adeline Williams","2_name":"Philadelphia Museum of Art"},{"1_name":"Portrait of a Little Girl","2_name":"Philadelphia Museum of Art"}],"resultAmount":100}The resultList property contains a JavaScript array of objects with property keys and values. To be able to display the column names and values in an Angular Material Table component, these properties are used:
protected columnData: Map<string, string>[] = [];
protected columnNames = new Set<string>();The method getColumnNames(...) of the table-search.component.ts is used to turn the JSON result in the properties:
private getColumnNames(tableSearch: TableSearch): Set<string> {
const result = new Set<string>();
this.columnData = [];
const myList = !tableSearch?.resultList ? [] : tableSearch.resultList;
myList.forEach((value) => {
const myMap = new Map<string, string>();
Object.entries(value).forEach((entry) => {
result.add(entry[0]);
myMap.set(entry[0], entry[1]);
});
this.columnData.push(myMap);
});
return result;
}First, the result set is created and the columnData property is set to an empty array. Then, myList is created and iterated with forEach(...). For each of the objects in the resultList, a new Map is created. For each property of the object, a new entry is created with the property name as the key and the property value as the value. The entry is set on the columnData map and the property name is added to the result set. The completed map is pushed on the columnData array and the result is returned and set to the columnNames property.
Then a set of column names is available in the columnNames set and a map with column name to column value is available in the columnData.
The template table-search.component.html contains the material table:
@if(searchResult && searchResult.resultList?.length) {
<table mat-table [dataSource]="columnData">
<ng-container *ngFor="let disCol of columnNames"
matColumnDef="{{ disCol }}">
<th mat-header-cell *matHeaderCellDef>{{ disCol }}</th>
<td mat-cell *matCellDef="let element">{{ element.get(disCol) }}</td>
</ng-container>
<tr mat-header-row *matHeaderRowDef="columnNames"></tr>
<tr mat-row *matRowDef="let row; columns: columnNames"></tr>
</table>
}First, the searchResult is checked for existence and objects in the resultList. Then, the table is created with the datasource of the columnData map. The table header row is set with <tr mat-header-row *matHeaderRowDef="columnNames"></tr> to contain the columnNames. The table rows and columns are defined with <tr mat-row *matRowDef="let row; columns: columnNames"></tr>.
- The cells are created by iterating the
columnNameslike this:<ng-container *ngFor="let disCol of columnNames" matColumnDef="{{ disCol }}">. - The header cells are created like this:
<th mat-header-cell *matHeaderCellDef>{{ disCol }}</th>. - The table cells are created like this:
<td mat-cell *matCellDef="let element">{{ element.get(disCol) }}</td>. elementis the map of thecolumnDataarray element and the map value is retrieved withelement.get(disCol).
Summary
Frontend
The new Angular syntax makes the templates more readable. The Angular Material table component is more flexible than expected and supports unknown numbers of columns very well.
Conclusion
To question a database with the help of an AI/LLM takes some effort for the metadata and a rough idea of the users what the database contains. AI/LLMs are not a natural fit for query creation because SQL queries require correctness. A pretty large model was needed to get the required query correctness, and GPU acceleration is required for productive use.
A well-designed UI where the user can drag and drop the columns of the tables in the result table might be a good alternative for the requirements. Angular Material Components support drag and drop very well.
Before starting such a project the customer should make an informed decision on what alternative fits the requirements best.
Opinions expressed by DZone contributors are their own.
Comments