Streaming ML Pipeline for Sentiment Analysis Using Apache APIs: Kafka, Spark, and Drill (Part 2)
Look at an overview of streaming concepts and learn how to ingest Kafka Events with Spark Structured Streaming and enrich events with a machine learning model.
Join the DZone community and get the full member experience.
Join For FreeText mining and analysis of social media, emails, support tickets, chats, product reviews, and recommendations have become a valuable resource used in almost all industry verticals to study data patterns in order to help businesses to gain insights, understand customers, to predict and enhance the customer experience, tailor marketing campaigns, and aid in decision making.

Sentiment analysis uses machine learning algorithms to determine how positive or negative text content is. Example use cases of sentiment analysis include:
- Quickly understanding the tone from customer reviews:
- To gain insights about what customers like or dislike about a product or service.
- To gain insights about what might influence the buying decisions of new customers.
- To give businesses market awareness.
- To address issues early
- Understanding stock market sentiment to gain insights for financial signal predictions
- Social media monitoring
- Brand/Product/Company popularity/reputation/perception monitoring
- Discontent customer detection monitoring and alerts
- Marketing campaign monitoring/analysis
- Customer service opinion monitoring/analysis
- Brand sentiment attitude analysis
- Customer feedback analytics
- Competition sentiment analytics
- Brand influencers monitoring
Manually analyzing the abundance of text produced by customers or potential customers is time-consuming, machine learning is more efficient and with streaming analysis, insights can be provided in real time.
This is the second in a series of blogs, which discusses the architecture of a data pipeline that combines streaming data with machine learning and fast storage. In the first part, we explored sentiment analysis using Spark Machine learning Data pipelines and saved a sentiment analysis machine learning model. This second post will discuss using the saved sentiment analysis model with streaming data to do real-time analysis of product sentiment, storing the results in MapR Database, and making them rapidly available for Spark and Drill SQL.
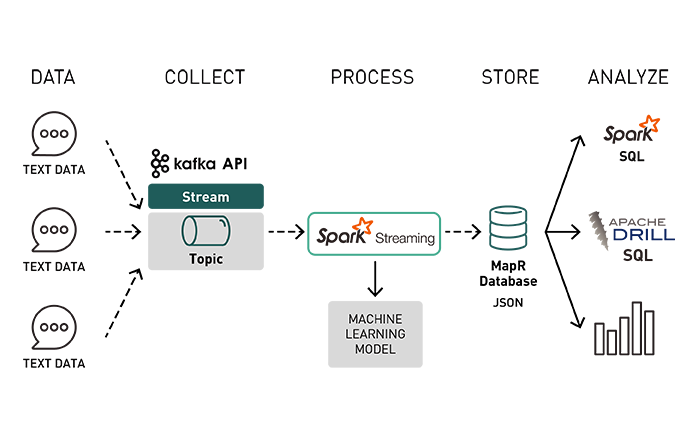
In this post we will go over the following:
- Overview of Streaming concepts
- Ingesting Kafka Events with Spark Structured Streaming
- Enriching events with a machine learning model
- Storing the events in MapR Database
- Querying the rapidly available enriched events in MapR Database with Apache Spark SQL and Apache Drill
Streaming Concepts
Publish-Subscribe Event Streams With MapR Event Store for Apache Kafka
MapR Event Store for Apache Kafka is a distributed publish-subscribe event streaming system that enables producers and consumers to exchange events in real time in a parallel and fault-tolerant manner via the Apache Kafka API.
A stream represents a continuous sequence of events that goes from producers to consumers, where an event is defined as a key-value pair.

Topics are a logical stream of events. Topics organize events into categories and decouple producers from consumers. Topics are partitioned for throughput and scalability. MapR Event Store can scale to very high throughput levels, easily delivering millions of messages per second using very modest hardware.

You can think of a partition like an event log: new events are appended to the end and are assigned a sequential ID number called the offset.
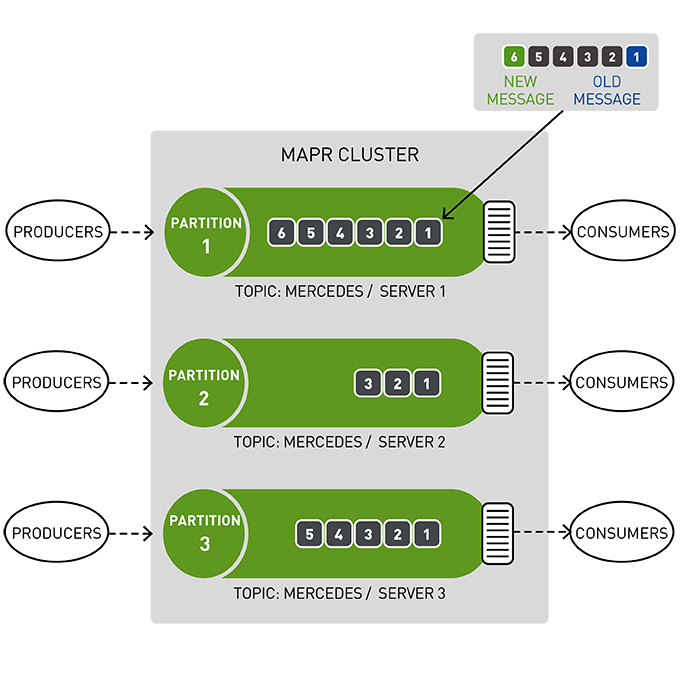
Like a queue, events are delivered in the order they are received.
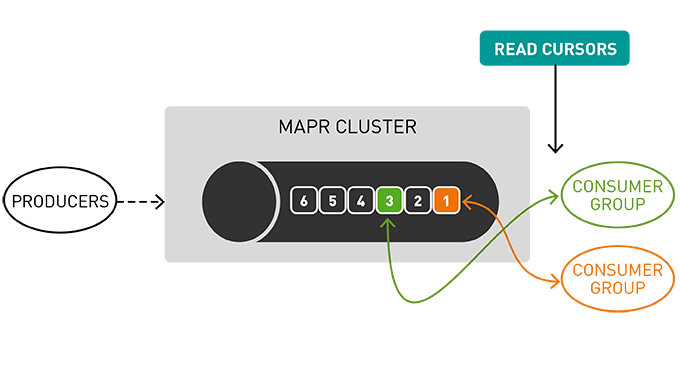
Unlike a queue, however, messages are not deleted when read. They remain on the partition available to other consumers. Messages, once published, are immutable and can be retained forever.
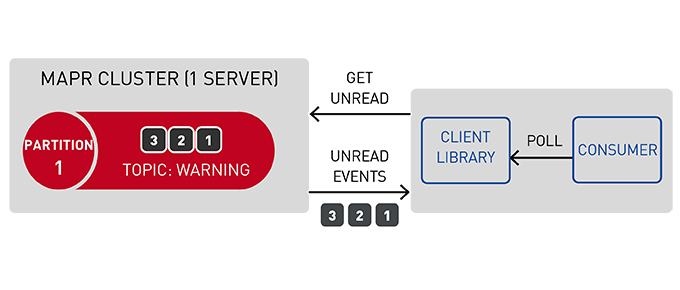
Not deleting messages when they are read allows for high performance at scale and also for processing of the same messages by different consumers for different purposes such as multiple views with polyglot persistence.

Spark Dataset, DataFrame, SQL
A Spark Dataset is a distributed collection of typed objects partitioned across multiple nodes in a cluster. A Dataset can be manipulated using functional transformations (map, flatMap, filter, etc.) and/or Spark SQL. A DataFrame is a Dataset of Row objects and represents a table of data with rows and columns.

Spark Structured Streaming
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. Structured Streaming enables you to view data published to Kafka as an unbounded DataFrame and process this data with the same DataFrame, Dataset, and SQL APIs used for batch processing.

As streaming data continues to arrive, the Spark SQL engine incrementally and continuously processes it and updates the final result.

Stream processing of events is useful for real-time ETL, filtering, transforming, creating counters and aggregations, correlating values, enriching with other data sources or machine learning, persisting to files or Database, and publishing to a different topic for pipelines.

Spark Structured Streaming Use Case Example Code
Below is the data processing pipeline for this use case of sentiment analysis of Amazon product review data to detect positive and negative reviews.
- Amazon product review JSON formatted events are published to a MapR Event Store topic using the Kafka API.
- A Spark Streaming application subscribed to the topic:
- Ingests a stream of product review events
- Uses a deployed machine learning model to enrich the review event with a positive or negative sentiment prediction
- Stores the transformed and enriched data in MapR Database in JSON format.

Example Use Case Data
The example data set is Amazon product reviews data from the previous blog in this series (insert link). The incoming data is in JSON format; an example is shown below:
{"reviewerID": "A3V52OTJHKIJZX", "asin": "2094869245","reviewText": "Light just installed on bike, seems to be well built.", "overall": 5.0, "summary": "Be seen", "unixReviewTime": 1369612800}We enrich this data with the sentiment prediction, drop some columns, then transform it into the following JSON object:
{"reviewerID": "A3V52OTJHKIJZX", "_id":"2094869245_1369612800", "reviewText": "Light just installed on bike, seems to be well built.", "overall": 5.0, "summary": "Be seen", "label":"1", "prediction":"1"}Loading the Spark Pipeline Model
The Spark PipelineModel class is used to load the pipeline model, which was fitted on the historical product review data (insert link to part 1 ) and then saved to the MapR-XD file system.
// Directory to read the saved ML model from
var modeldirectory ="/user/mapr/sentmodel/"
// load the saved model from the distributed file system
val model = PipelineModel.load(modeldirectory)
Reading Data from Kafka Topics
In order to read from Kafka, we must first specify the stream format, topic, and offset options. For more information on the configuration parameters, see the MapR Streams documentation.
var topic: String = "/user/mapr/stream:reviews"
val df1 = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", "maprdemo:9092")
.option("subscribe", topic)
.option("group.id", "testgroup")
.option("startingOffsets", "earliest")
.option("failOnDataLoss", false)
.option("maxOffsetsPerTrigger", 1000)
.load()This returns a DataFrame with the following schema:
df1.printSchema()
result:
root
|-- key: binary (nullable = true)
|-- value: binary (nullable = true)
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)Parsing the Message Values Into a DataFrame
The next step is to parse and transform the binary values column into a DataFrame with the product review schema. We will use Spark from_json to extract the JSON data from the Kafka DataFrame value field seen above. The Spark SQL from_json() function turns an input JSON string column into a Spark struct, with the specified input schema.
First, we use a Spark Structype to define the schema corresponding to the incoming JSON message value.
val schema = StructType(Array(
StructField("asin", StringType, true),
StructField("helpful", ArrayType(StringType), true),
StructField("overall", DoubleType, true),
StructField("reviewText", StringType, true),
StructField("reviewTime", StringType, true),
StructField("reviewerID", StringType, true),
StructField("reviewerName", StringType, true),
StructField("summary", StringType, true),
StructField("unixReviewTime", LongType, true)
)) In the code below, we use the from_json() Spark SQL function, in a select expression with a string cast of the df1 column value, which returns a DataFrame of the specified schema.
import spark.implicits._
val df2 = df1.select($"value" cast "string" as "json")
.select(from_json($"json", schema) as "data")
.select("data.*") This returns a DataFrame with the following schema:
df2.printSchema()
result:
root
|-- asin: string (nullable = true)
|-- helpful: array (nullable = true)
| |-- element: string (containsNull = true)
|-- overall: double (nullable = true)
|-- reviewText: string (nullable = true)
|-- reviewTime: string (nullable = true)
|-- reviewerID: string (nullable = true)
|-- reviewerName: string (nullable = true)
|-- summary: string (nullable = true)
|-- unixReviewTime: long (nullable = true)In the code below:
- we use the withColumn method to add a column combining the review summary with the review text .
- we filter to remove neutral ratings (=3)
- a Spark Bucketizer is used to add a label 0/1 column to the dataset for Positive (overall rating >=4) and not positive (overall rating <4) reviews. (Note the label is for testing the predictions)
// combine summary reviewText into one column
val df3 = df2.withColumn("reviewTS",
concat($"summary",lit(" "),$"reviewText" ))
// remove neutral ratings
val df4 = df3.filter("overall !=3")
// add label column
val bucketizer = new Bucketizer()
.setInputCol("overall")
.setOutputCol("label")
.setSplits(Array(Double.NegativeInfinity,3.0,Double.PositiveInfinity))
val df5= bucketizer.transform(df4)Enriching the DataFrame of Reviews With Sentiment Predictions
Next, we transform the DataFrame with the model pipeline, which will transform the features according to the pipeline, estimate and then return the predictions in a column of a new DateFrame.
// transform the DataFrame with the model pipeline
val predictions = model.transform(df5)This returns a DataFrame with the following schema:
predictions.printSchema()
result:
root
|-- asin: string (nullable = true)
|-- helpful: array (nullable = true)
| |-- element: string (containsNull = true)
|-- overall: double (nullable = true)
|-- reviewText: string (nullable = true)
|-- reviewTime: string (nullable = true)
|-- reviewerID: string (nullable = true)
|-- reviewerName: string (nullable = true)
|-- summary: string (nullable = true)
|-- unixReviewTime: long (nullable = true)
|-- reviewTS: string (nullable = true)
|-- label: double (nullable = true)
|-- reviewTokensUf: array (nullable = true)
| |-- element: string (containsNull = true)
|-- reviewTokens: array (nullable = true)
| |-- element: string (containsNull = true)
|-- cv: vector (nullable = true)
|-- features: vector (nullable = true)
|-- rawPrediction: vector (nullable = true)
|-- probability: vector (nullable = true)
|-- prediction: double (nullable = false)Adding a Unique Id for MapR Database
In the code below we:
- drop the columns that we do not want to store
- create a unique id “_id” composed of the product id and review timestamp, to us as the row key for storing in MapR Database.
// drop the columns that we do not want to store
val df6 = predictions.drop("cv","probability", "features", "reviewTokens", "helpful", "reviewTokensUf", "rawPrediction")
// create column with unique id for MapR Database
val df7 = df6.withColumn("_id", concat($"asin",lit("_"), $"unixReviewTime"))This returns a DataFrame with the following schema:
df7.printSchema()
Result:
root
|-- asin: string (nullable = true)
|-- overall: double (nullable = true)
|-- reviewText: string (nullable = true)
|-- reviewTime: string (nullable = true)
|-- reviewerID: string (nullable = true)
|-- reviewerName: string (nullable = true)
|-- summary: string (nullable = true)
|-- unixReviewTime: long (nullable = true)
|-- label: double (nullable = true)
|-- reviewTokens: array (nullable = true)
| |-- element: string (containsNull = true)
|-- prediction: double (nullable = false)
|-- _id: string (nullable = true)Spark Streaming Writing to MapR Database
The MapR Database Connector for Apache Spark enables you to use MapR Database as a sink for Spark Structured Streaming or Spark Streaming.
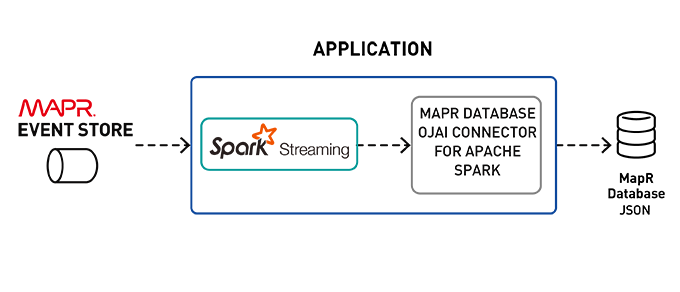
One of the challenges, when you are processing lots of streaming data, is: where do you want to store it? For this application, MapR Database, a high-performance NoSQL database, was chosen for its scalability and flexible ease of use with JSON.
JSON Schema Flexibility
MapR Database supports JSON documents as a native data store. MapR Database makes it easy to store, query, and build applications with JSON documents. The Spark connector makes it easy to build real-time or batch pipelines between your JSON data and MapR Database and leverage Spark within the pipeline.

With MapR Database, a table is automatically partitioned into tablets across a cluster by key range, providing for scalable and fast reads and writes by row key. In this use case, the row key, the _id, consists of the cluster ID and reverse timestamp, so the table is automatically partitioned and sorted by cluster ID with the most recent first.

The Spark MapR Database Connector architecture has a connection object in every Spark Executor, allowing for distributed parallel writes, reads, or scans with MapR Database tablets (partitions).

Writing to a MapR Database Sink
To write a Spark Stream to MapR Database, specify the format with the tablePath, idFieldPath, createTable, bulkMode, and sampleSize parameters. The following example writes out the df7 DataFrame to MapR Database and starts the stream.
import com.mapr.db.spark.impl._
import com.mapr.db.spark.streaming._
import com.mapr.db.spark.sql._
import com.mapr.db.spark.streaming.MapRDBSourceConfig
var tableName: String = "/user/mapr/reviewtable"
val writedb = df7.writeStream
.format(MapRDBSourceConfig.Format)
.option(MapRDBSourceConfig.TablePathOption, tableName)
.option(MapRDBSourceConfig.IdFieldPathOption, "_id")
.option(MapRDBSourceConfig.CreateTableOption, false)
.option("checkpointLocation", "/tmp/reviewdb")
.option(MapRDBSourceConfig.BulkModeOption, true)
.option(MapRDBSourceConfig.SampleSizeOption, 1000)
writedb.start()
Querying MapR Database JSON With Spark SQL
The Spark MapR Database Connector enables users to perform complex SQL queries and updates on top of MapR Database using a Spark Dataset while applying critical techniques such as projection and filter pushdown, custom partitioning, and data locality.
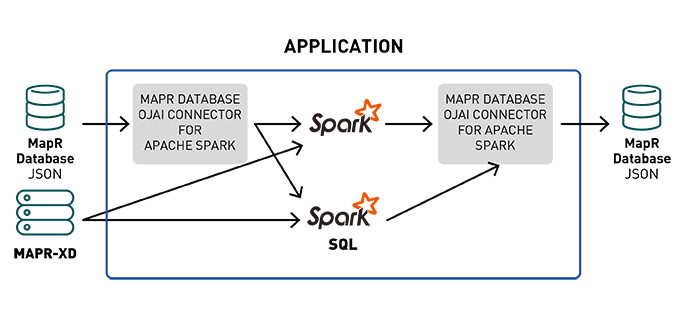
Loading Data From MapR Database Into a Spark Dataset
To load data from a MapR Database JSON table into an Apache Spark Dataset, we invoke the loadFromMapRDB method on a SparkSession object, providing the tableName, schema, and case class. This returns a Dataset with the product review schema:
val schema = StructType(Array(
StructField("_id", StringType, true),
StructField("asin", StringType, true),
StructField("overall", DoubleType, true),
StructField("reviewText", StringType, true),
StructField("reviewTime", StringType, true),
StructField("reviewerID", StringType, true),
StructField("reviewerName", StringType, true),
StructField("summary", StringType, true),
StructField("label", StringType, true),
StructField("prediction", StringType, true),
StructField("unixReviewTime", LongType, true)
))
var tableName: String = "/user/mapr/reviewtable"
val df = spark
.loadFromMapRDB(tableName, schema)
df.createOrReplaceTempView("reviews")Explore and Query the Product Review Data With Spark SQL
Now we can query the data that is continuously streaming into MapR Database to ask questions with the Spark DataFrames domain-specific language or with Spark SQL.
Below, we use the DataFrames select and show methods to display the first 5 rows review summary, overall rating, label, and prediction in tabular format:
df.select("summary","overall","label","prediction").show(5)
result:
+--------------------+-------+-----+----------+
| summary|overall|label|prediction|
+--------------------+-------+-----+----------+
| Excellent Ammo Can| 5.0| 1.0| 1.0|
| Glad I bought it| 5.0| 1.0| 1.0|
|WILL BUY FROM AGA...| 5.0| 1.0| 1.0|
|looked brand new ...| 5.0| 1.0| 1.0|
| I LOVE THIS THING| 5.0| 1.0| 1.0|
+--------------------+-------+-----+----------+What are the products with the highest ratings?
df.filter($"overall" === 5.0)
.groupBy("overall","asin")
.count
.orderBy(desc("count")).show(2)
result:
+-------+----------+-----+
|overall| asin|count|
+-------+----------+-----+
| 5.0|B004TNWD40| 242|
| 5.0|B004U8CP88| 201|
+-------+----------+-----+Or in SQL What are the products with the highest ratings?
%sql
SELECT asin,overall, count(overall)
FROM reviews where overall=5.0
GROUP BY asin, overall
order by count(overall) desc limit 2Display the best-rated product reviews text
df.select("summary","reviewText","overall","label","prediction").filter("asin='B004TNWD40'").show(5)
result:
+--------------------+--------------------+-------+-----+----------+
| summary| reviewText|overall|label|prediction|
+--------------------+--------------------+-------+-----+----------+
| Awesome|This is the perfe...| 5.0| 1.0| 1.0|
|for the price you...|Great first knife...| 5.0| 1.0| 1.0|
|Great Mora qualit...|I have extensive ...| 4.0| 1.0| 1.0|
| Amazing knife|All I can say is ...| 5.0| 1.0| 1.0|
|Swedish Mil. Mora...|Overall a nice kn...| 4.0| 1.0| 1.0|
+--------------------+--------------------+-------+-----+----------+Or in SQL:
%sql
select summary, label, prediction, overall
from reviews
where asin='B004TNWD40'
order by overall desc
What are the products with the highest count of low ratings?
df.filter($"overall" === 1.0)
.groupBy("overall","asin")
.count.orderBy(desc("count")).show(2)
result:
+-------+----------+-----+
|overall| asin|count|
+-------+----------+-----+
| 1.0|B00A17I99Q| 18|
| 1.0|B00BGO0Q9O| 17|
+-------+----------+-----+Display the product reviews text for Product with the highest count of low ratings
df.select("summary","reviewText","overall","label","prediction")
.filter("asin='B00A17I99Q'")
.orderBy("overall").show(8)
result:
+--------------------+--------------------+-------+-----+----------+
| summary| reviewText|overall|label|prediction|
+--------------------+--------------------+-------+-----+----------+
| DO NOT BUY!|Do your research ...| 1.0| 0.0| 0.0|
| Returned it|I could not get t...| 1.0| 0.0| 0.0|
| didn't do it for me|didn't like it. ...| 1.0| 0.0| 0.0|
|Fragile, just lik...|Update My second....| 1.0| 0.0| 0.0|Below, we calculate some prediction evaluation metrics for the streaming data continuously stored in MapR Database. The number of false/true positives:
- True positives are how often the model correctly positive sentiment
- False positives are how often the model incorrectly positive sentiment
- True negatives indicate how often the model correctly negative sentiment
- False negatives indicate how often the model incorrectly negative sentiment
val lp = predictions.select("label", "prediction")
val counttotal = predictions.count()
val correct = lp.filter($"label" === $"prediction").count()
val wrong = lp.filter(not($"label" === $"prediction")).count()
val ratioWrong = wrong.toDouble / counttotal.toDouble
val lp = predictions.select( "prediction","label")
val counttotal = predictions.count().toDouble
val correct = lp.filter($"label" === $"prediction")
.count()
val wrong = lp.filter("label != prediction")
.count()
val ratioWrong=wrong/counttotal
val ratioCorrect=correct/counttotal
val truen =( lp.filter($"label" === 0.0)
.filter($"label" === $"prediction")
.count()) /counttotal
val truep = (lp.filter($"label" === 1.0)
.filter($"label" === $"prediction")
.count())/counttotal
val falsen = (lp.filter($"label" === 0.0)
.filter(not($"label" === $"prediction"))
.count())/counttotal
val falsep = (lp.filter($"label" === 1.0)
.filter(not($"label" === $"prediction"))
.count())/counttotal
val precision= truep / (truep + falsep)
val recall= truep / (truep + falsen)
val fmeasure= 2 * precision * recall / (precision + recall)
val accuracy=(truep + truen) / (truep + truen + falsep + falsen)
results:
counttotal: Double = 84160.0
correct: Double = 76925.0
wrong: Double = 7235.0
truep: Double = 0.8582461977186312
truen: Double = 0.05578659695817491
falsep: Double = 0.014543726235741445
falsen: Double = 0.07142347908745247
ratioWrong: Double = 0.08596720532319392
ratioCorrect: Double = 0.9140327946768061Projection and Filter Push Down Into MapR Database
You can see the physical plan for a DataFrame query by calling the explain method shown below. Here in red, we see projection and filter push down, which means that the scanning of the overall and summary columns and the filter on the overall column are pushed down into MapR Database, which means that the scanning and filtering will take place in MapR Database before returning the data to Spark.
Projection pushdown minimizes data transfer between MapR Database and the Spark engine by omitting unnecessary fields from table scans. It is especially beneficial when a table contains many columns. Filter pushdown improves performance by reducing the amount of data passed between MapR Database and the Spark engine when filtering data.
// notice projection of selected fields [summary]
// notice PushedFilters: overall
df.filter("overall > 3").select("summary").explain
result:
== Physical Plan ==
*(1) Project [summary#7]
+- *(1) Filter (isnotnull(overall#2) && (overall#2 > 3.0))
+- *(1) Scan MapRDBRelation MapRDBTableScanRDD [summary#7,overall#2]
PushedFilters: [IsNotNull(overall), GreaterThan(overall,3.0)],
ReadSchema: struct<summary:string,overall:double>Querying the Data With Apache Drill
Apache Drill is an open-source, low-latency query engine for big data that delivers interactive SQL analytics at petabyte scale. Drill provides a massively parallel processing execution engine, built to perform distributed query processing across the various nodes in a cluster.

With Drill, you can use SQL to interactively query and join data from files in JSON, Parquet, or CSV format, Hive, and NoSQL stores, including HBase, MapR-DB, and Mongo, without defining schemas. MapR provides a Drill JDBC driver that you can use to connect Java applications, BI tools, such as SquirreL and Spotfire, to Drill.
Below are some example SQL queries using the Drill shell:
Start the Drill shell with:
sqlline -u jdbc:drill:zk=localhost:5181 -n mapr -p mapr
How many streaming product reviews were stored in MapR Database?
select count(_id) as totalreviews from dfs.`/user/mapr/reviewtable`;
result:
+---------------+
| totalreviews |
+---------------+
| 84160 |
+---------------+How many reviews are there for each rating?
select overall, count(overall) as countoverall from dfs.`/user/mapr/reviewtable` group by overall order by overall desc;
result:
+----------+---------------+
| overall | countoverall |
+----------+---------------+
| 5.0 | 57827 |
| 4.0 | 20414 |
| 2.0 | 3166 |
| 1.0 | 2753 |
+----------+---------------+What are the products with the highest review ratings?
select overall, asin, count(*) as ratingcount, sum(overall) as ratingsum
from dfs.`/user/mapr/reviewtable`
group by overall, asin
order by sum(overall) desc limit 5;
result:
+----------+-------------+--------------+------------+
| overall | asin | ratingcount | ratingsum |
+----------+-------------+--------------+------------+
| 5.0 | B004TNWD40 | 242 | 1210.0 |
| 5.0 | B004U8CP88 | 201 | 1005.0 |
| 5.0 | B006QF3TW4 | 186 | 930.0 |
| 5.0 | B006X9DLQM | 183 | 915.0 |
| 5.0 | B004RR0N8Q | 165 | 825.0 |
+----------+-------------+--------------+------------+What are the products with the most positive review predictions?
select prediction, asin, count(*) as predictioncount, sum(prediction) as predictionsum
from dfs.`/user/mapr/reviewtable`
group by prediction, asin
order by sum(prediction) desc limit 5;
result:
+-------------+-------------+------------------+----------------+
| prediction | asin | predictioncount | predictionsum |
+-------------+-------------+------------------+----------------+
| 1.0 | B004TNWD40 | 263 | 263.0 |
| 1.0 | B004U8CP88 | 252 | 252.0 |
| 1.0 | B006X9DLQM | 218 | 218.0 |
| 1.0 | B006QF3TW4 | 217 | 217.0 |
| 1.0 | B004RR0N8Q | 193 | 193.0 |
+-------------+-------------+------------------+----------------+Show the review summaries for the product with the highest review ratings
select summary, prediction
from dfs.`/user/mapr/reviewtable`
where asin='B004TNWD40' limit 5;
result:
+---------------------------------------------------+-------------+
| summary | prediction |
+---------------------------------------------------+-------------+
| Awesome | 1.0 |
| for the price you cant go wrong with this knife | 1.0 |
| Great Mora quality and economy | 1.0 |
| Amazing knife | 1.0 |
| Swedish Mil. Mora Knife | 1.0 |
+---------------------------------------------------+-------------+Show the review tokens for the product with the most positive reviews
select reviewTokens from dfs.`/user/mapr/reviewtable` where asin='B004TNWD40' limit 1;
[ "awesome", "perfect", "belt/pocket/neck", "knife",
"carbon", "steel", "blade", "last", "life", "time!", "handle", "sheath",
"plastic", "cheap", "kind", "plastic", "durable", "also", "last", "life",
"time", "everyone", "loves", "doors", "this!", "yes", "ones", "bone",
"handles", "leather", "sheaths", "$100+" ] What are the products with the lowest review ratings?
SELECT asin,overall, count(overall) as rcount
FROM dfs.`/user/mapr/reviewtable`
where overall=1.0
GROUP BY asin, overall
order by count(overall) desc limit 2
result:
+-------------+----------+---------+
| asin | overall | rcount |
+-------------+----------+---------+
| B00A17I99Q | 1.0 | 18 |
| B008VS8M58 | 1.0 | 17 |
+-------------+----------+---------+What are the products with the most negative review predictions?
select prediction, asin, count(*) as predictioncount, sum(prediction) as predictionsum from dfs.`/user/mapr/reviewtable` group by prediction, asin order by sum(prediction) limit 2;
result:
+-------------+-------------+------------------+----------------+
| prediction | asin | predictioncount | predictionsum |
+-------------+-------------+------------------+----------------+
| 0.0 | B007QEUWSI | 4 | 0.0 |
| 0.0 | B007QTHPX8 | 4 | 0.0 |
+-------------+-------------+------------------+---------------+Show the review summaries for the product with the lowest review ratings
select summary
from dfs.`/user/mapr/reviewtable`
where asin='B00A17I99Q' and prediction=0.0 limit 5;
result:
+---------------------------------------------------------+
| summary |
+---------------------------------------------------------+
| A comparison to Fitbit One -- The Holistic Wrist |
| Fragile, just like the first Jawbone UP! Overpriced |
| Great concept, STILL horrible for daily use |
| Excellent idea, bad ergonomics, worse manufacturing... |
| get size larger |
+---------------------------------------------------------+Querying the Data With the MapR Database Shell
The mapr dbshell is a tool that enables you to create and perform basic manipulation of JSON tables and documents. You run dbshell by typing mapr dbshell on the command line after logging into a node in a MapR cluster.
Below are some example queries using the MapR dbshell:
Show the review summary, id, prediction for the product with the highest review ratings (_id starts with B004TNWD40).
find /user/mapr/reviewtable --where '{"$and":[{"$eq":{"overall":5.0}}, { "$like" : {"_id":"%B004TNWD40%"} }]}' --f _id,prediction,summary --limit 5
result:
{"_id":"B004TNWD40_1256083200","prediction":1,"summary":"Awesome"}
{"_id":"B004TNWD40_1257120000","prediction":1,"summary":"for the price you cant go wrong with this knife"}
{"_id":"B004TNWD40_1279065600","prediction":1,"summary":"Amazing knife"}
{"_id":"B004TNWD40_1302393600","prediction":1,"summary":"Great little knife"}
{"_id":"B004TNWD40_1303257600","prediction":1,"summary":"AWESOME KNIFE"}Show the review summary, id, for 10 products with negative sentiment prediction and label.
find /user/mapr/reviewtable --where '{"$and":[{"$eq":{"prediction":0.0}},{"$eq":{"label":0.0}} ]}' --f _id,summary --limit 10
result:
{"_id":"B003Y64RBA_1312243200","summary":"A $3.55 rubber band!"}
{"_id":"B003Y64RBA_1399334400","summary":"cheap not worthy"}
{"_id":"B003Y71V2C_1359244800","summary":"Couple of Problems"}
{"_id":"B003Y73EPY_1349740800","summary":"Short Term Pedals - Eggbeaters 1"}
{"_id":"B003Y9CMGY_1306886400","summary":"Expensive batteries."}
{"_id":"B003YCWFRM_1336089600","summary":"Poor design"}
{"_id":"B003YCWFRM_1377043200","summary":"Great while it lasted"}
{"_id":"B003YD0KZU_1321920000","summary":"No belt clip!!! Just like the other reviewer..."}
{"_id":"B003YD0KZU_1338768000","summary":"Useless"}
{"_id":"B003YD1M5M_1354665600","summary":"Can't recomend this knife."}Summary
In this post, you learned how to use the following:
- A Spark machine learning model in a Spark Structured Streaming application
- Spark Structured Streaming with MapR Event Store to ingest messages using the Kafka API
- Spark Structured Streaming to persist to MapR Database for continuously rapidly available SQL analysis
All of the components of the use case architecture we just discussed can run on the same cluster with the MapR Data Platform. The MapR Data Platform integrates global event streaming, real-time database capabilities, and scalable enterprise storage with Spark, Drill, and machine learning libraries to power the development of next-generation intelligent applications, which take advantage of modern computational paradigms powered by modern computational infrastructure.

Code
All of the data and code to train the models and make your own conclusions, using Apache Spark, are located on GitHub. Refer to GitHub readme for more information about running the code.
Published at DZone with permission of Carol McDonald. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments