Streaming Solution for Better Transparency
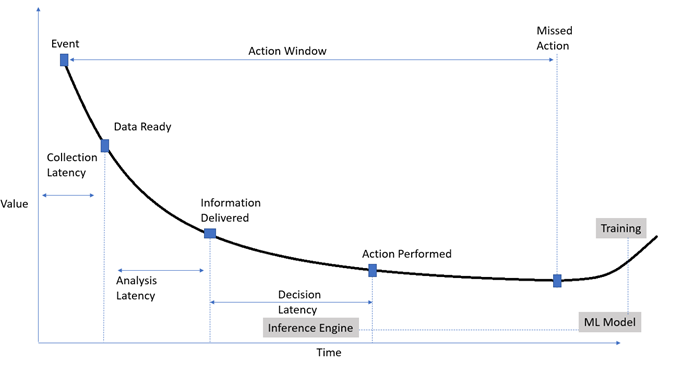
For streaming analytics, there is a bounded timeline during which action must be taken to control process or asset parameters.
Join the DZone community and get the full member experience.
Join For FreeWhat do you do when you have million-dollar equipment in your manufacturing pipeline giving you sleepless nights? To mitigate risk, you might create a digital counterpart of your physical asset, popularly known as the Digital twin, and leverage augmented intelligence derived from data streams. IoT makes the solution affordable and big data enables analytics at scale. For streaming analytics, there is a bounded timeline during which action needs to be taken to control process or asset parameters. Digital twin and stream analytics can help improve the availability of assets, improve quality in the manufacturing process and help in finding RCAs for failures.
For similar analytics use cases, I see Spark streaming best suited as part of the solution due to its open-source and easy-to-program APIs.
We will discuss the flawless design with respect to scalability, latency, and fault tolerance by leveraging the latest features of Spark, and Kafka.
Spark Framework
Spark currently offers two frameworks for spark stream processing -
- Spark streaming framework- This framework is based on Resilient Distributed Datasets [RDD], which process events in micro-batches.
kafkaDStream = KafkaUtils.createDirectStream(spark_streaming,[topic],{"metadata.broker.list": brokers})
def handler(message):
records = message.collect()
for record in records:
print(json.loads(record[1]))
payload = json.loads(record[1])
print(payload["temp_number"])
kafkaDStream.foreachRDD(lambda rdd: handler(rdd))2. Structural Streaming-based Spark framework - This framework is based on a data frame that is optimized for performance, and provides support for both micro-batches with latency(~100ms at best) and continuous stream processing with millisecond latency(~1ms). Continuous processing is a new, experimental streaming execution mode
df = (
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "region.azure.confluent.cloud:9092")
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.jaas.config", "kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{}' password='{}';".format(CLUSTER_API_KEY, CLUSTER_API_SECRET))
.option("kafka.ssl.endpoint.identification.algorithm", "https")
.option("kafka.sasl.mechanism", "PLAIN")
.option("subscribe", kafka_topic_name)
.option("startingOffsets", "earliest")
.option("failOnDataLoss", "false")
.load()
.withColumn('fixedValue', fn.expr("substring(value, 6, length(value)-5)"))
.select('topic', 'partition', 'offset', 'timestamp', 'fixedValue')
)
display(df)
Kafka Streaming Platform
To provide data buffering layer between data producer IoT devices, and backend spark consumers, the streaming platform plays a vital role with message reliable processing guarantees, message replay, and retention capability. The streaming platform enables a query mechanism for Spark consumers to poll events at regular intervals. These events are then added to the unbounded input table in the Spark structural streaming framework.
Fault Tolerance
Before structural streaming, it was the developer's nightmare to avoid duplicate writes for incoming messages. Structural Streaming makes the development model easy as "exactly-once" is enabled by using transactional data sources and checkpointing sinks for micro-batch trigger intervals.
Kafka Event streaming platform serves as the data source for Spark streaming with offset-based commits. This offset capability enables Spark Structural Streaming applications the ability to restart and replay messages from any point in time. Structured Streaming can ensure exactly-once message processing semantics under any failure using replayable sources and idempotent sinks like a key-value store.
The streaming query can be configured with a checkpoint location, and the query will save all the offset progress information and the running aggregates to the checkpoint location.
These checkpointing and write-ahead logs help recover the previous good state in case of failure for re-generating RDDs.
How to Scale Stream Processing?
By default, the number of executors required on the Spark cluster will be equal to the number of partitions. Increasing Kafka partition to Spark executor partition ratio will improve Spark Structural Stream throughput for consumption of messages while adding to processing cost.
If the data in the Kafka partition is needed to be further split for Spark processing, the Spark partition limit can be increased by the “minPartitions” configuration. For 10 partitions of Kafka stream, 20 partitions can be specified as “minPartitions” in Spark job configuration.
Event Timestamp Processing
Spark Structural Streaming processes events based on incoming event timestamp, thus enabling handling of late-arriving data and watermarking threshold for such events. Former Spark streaming framework can process events only based on system or processing timestamp. Thus Structural Streaming makes possible aggregations on Windows over Event-Time, say, last 5 minutes. Tumbling window[window duration is the same as sliding duration] and overlapping window[window duration is greater than sliding duration] aggregation are possible using event time. This feature is useful in case there is network latency for incoming IoT data.
Hybrid joins between streaming data, and static dataset has simpler data frame-based API with structural streaming. Join API can be leveraged to enrich incoming streaming data with static master data to ensure completeness of report data or for validation.
Platform and Service Offerings
Below are service offerings from leading cloud-based platforms. Based on the use case and service suitability, a services can be selected for the streaming solution.
Platform brings in advantage for ease in management, monitoring and version updates for Spark and Kafka based services. I see certain advantages of opting Databricks for spark engine and Confluent for Kafka-
- Databricks Spark engine is 50 times optimized as compared to Apache Spark and platform provides collaborative environment for Data Engineers, Data Scientists to work together
- For structural data sources like databases, Confluent offers CDC connectors which can be useful for real time streaming use cases
Platform offerings for Spark and Kafka-
|
Platform
|
|||||
|
Azure
|
AWS
|
Cloudera
|
GCP | ||
| Services | Spark | Azure Databricks, HDInsight, Synapse Spark Engine | EMR, Glue, Databricks | Data Engineering | Dataproc, Databricks |
| Kafka | Event Hub, HDInsight, Confluent | MSK, Confluent | CDP Streams Messaging | Confluent | |
Spark Structural Streaming and Kafka streaming platform together can be leveraged to deliver a true event-based, fault-tolerant, and highly scalable stream processing framework for real-time Digital twin streaming analytics use cases.
Opinions expressed by DZone contributors are their own.
Comments