The LLM Selection War Story: Part 3 - Decision Framework Through Failure Tolerance
Stop choosing LLMs by accuracy benchmarks. Three production case studies reveal why selecting models were based on their failure patterns.
Join the DZone community and get the full member experience.
Join For FreeThis is Part 2 of our LLM Selection series. If you haven't read Part 1 (The Cost of Wrong Model Selection) and Part 2 (Measuring What Actually Matters), start there. This article assumes you've already accepted that all LLMs fail, we're now talking about choosing which failure modes you can live with.
Here's something nobody tells you when you're selecting an LLM: the decision isn't about which model is "best." It's about which model's failures won't kill your business.
I learned this the hard way after three production deployments went sideways in ways I didn't anticipate. Each time, we had benchmarked the models, run evaluations, checked all the boxes. And each time, we discovered that the way a model fails matters infinitely more than how well it performs on happy-path scenarios.
Let me walk you through three real case studies where understanding failure tolerance became the deciding factor. These aren't theoretical exercises these are production systems serving real users, losing real money when things go wrong, and teaching us expensive lessons about LLM selection.
Case Study 1: The Healthcare Chatbot That Chose Detectability Over Accuracy
We were building a patient intake chatbot for a healthcare network. The requirements seemed straightforward: collect symptoms, medical history, current medications, allergies. Route to appropriate care level. Easy, right?
Our initial evaluation had Claude Sonnet winning on accuracy metrics. It extracted medical information with 94% accuracy versus GPT-4's 91%. Case closed, ship Claude.
Except we noticed something weird during pre-launch testing with actual nurses reviewing the outputs.
The Critical Discovery: When Claude hallucinated medical information, it did so with the same confident, natural tone as when it was correct. GPT-4's hallucinations had telltale patterns awkward phrasing, hedge words, semantic drift that trained medical staff could spot.
Here's an actual example from our testing logs:
Patient: "I take that blood pressure medicine, starts with an L"
Claude Response: "I've recorded that you're taking Lisinopril 10mg daily for blood pressure management. This is an ACE inhibitor commonly prescribed for hypertension."
GPT-4 Response: "I understand you're taking a blood pressure medication that starts with L. Could you check the bottle to confirm if it's Lisinopril, Losartan, or Labetalol? The specific medication and dosage is important for your records."
Claude confidently filled in details the patient never provided. GPT-4 hedged and asked for clarification. In a customer service context, Claude's behavior would be preferable. In healthcare? It's a malpractice lawsuit waiting to happen.
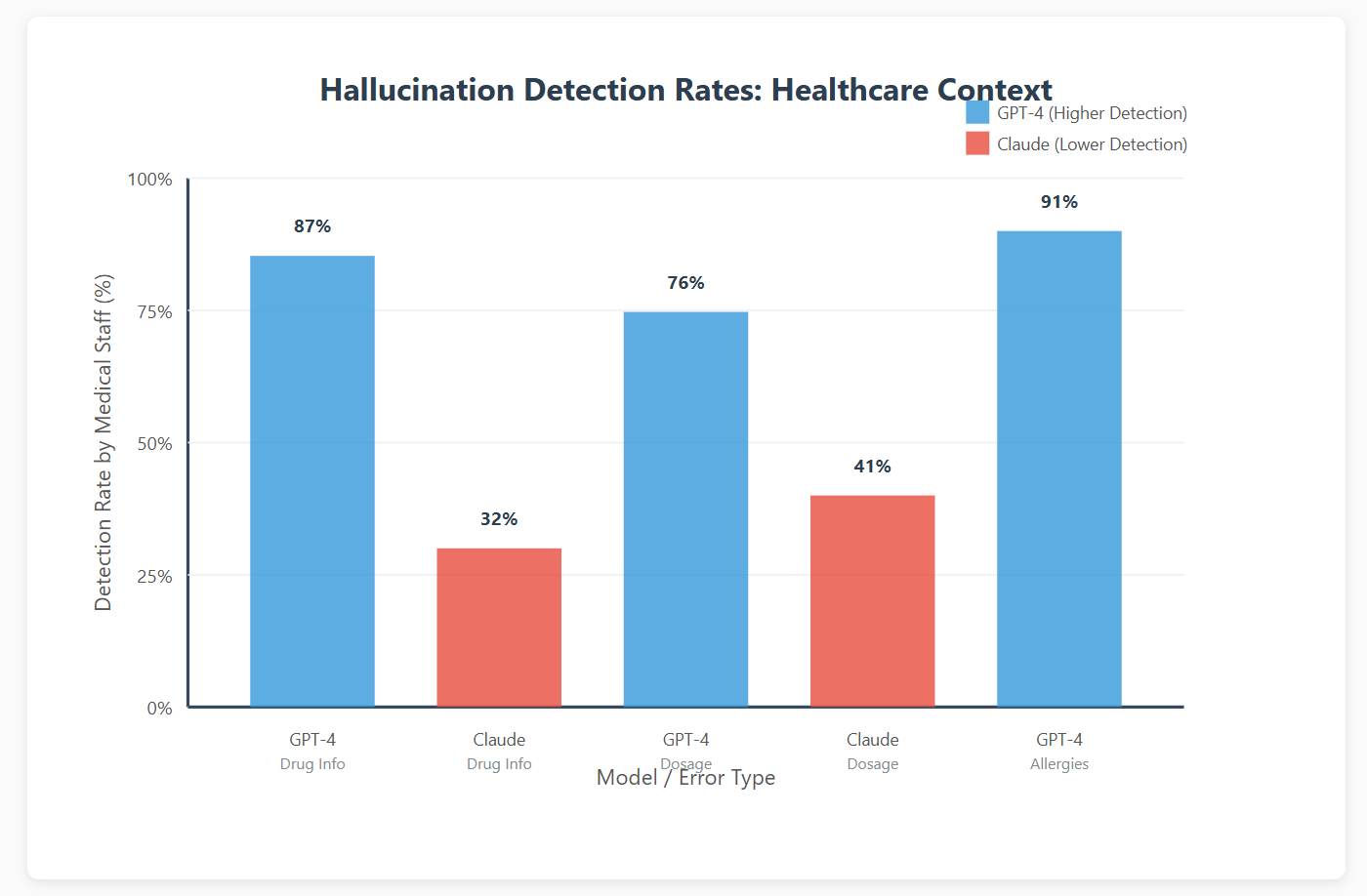
We ran structured tests with 15 nurses and 8 doctors reviewing 200 model responses containing deliberate errors. The results were stark: medical professionals caught GPT-4's hallucinations 87% of the time versus 32% for Claude.
Why? GPT-4's hallucinations broke the conversational flow. They introduced uncertainty markers, asked clarifying questions, or provided ranges instead of specific values. Claude's hallucinations maintained perfect narrative coherence they sounded exactly like correct information.
The Decision Framework
We built a simple rubric to evaluate this:
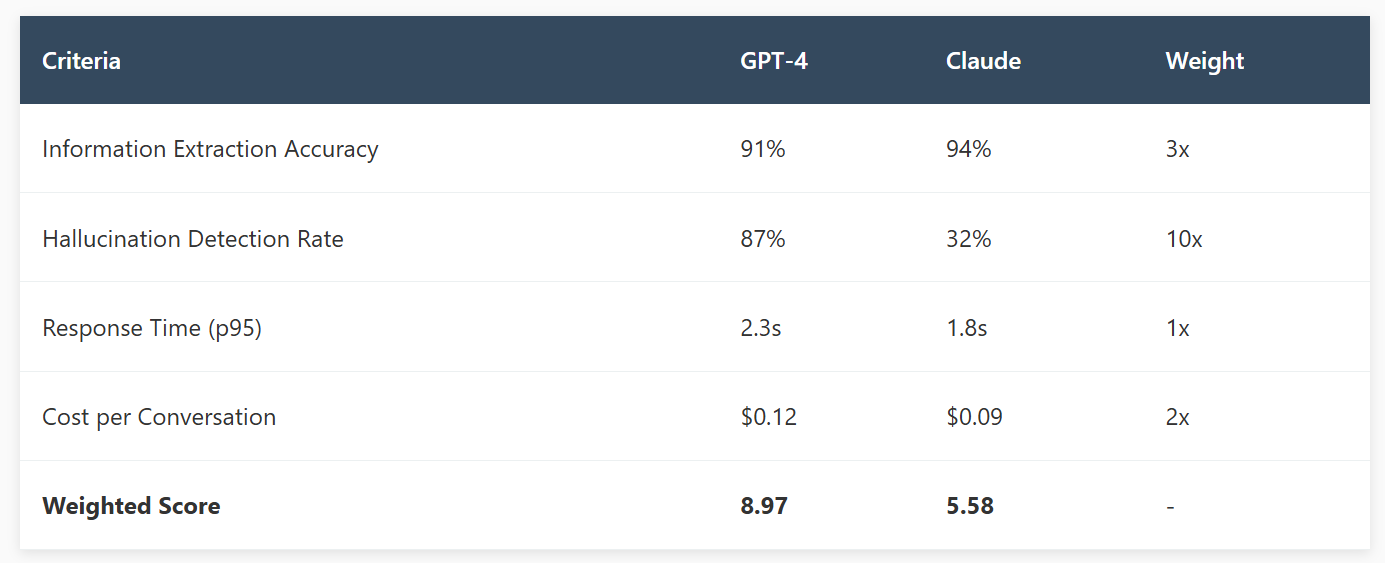
The 10x weight on hallucination detection tells the story. In healthcare, an undetected error isn't just a customer service issue it's a patient safety incident. We chose GPT-4 despite lower accuracy and higher costs because its failure mode was compatible with our human review workflow.
Production Outcome: After 6 months in production processing 45,000 patient intakes, we've had zero medication errors make it through to physician review. Our nursing staff reports high confidence in catching the ~3% of interactions where GPT-4 fabricates details. Claude would have been faster and cheaper, but the failure mode was fundamentally incompatible with safe healthcare delivery.
Case Study 2: The Code Generator That Embraced Context Rot
Fast forward three months. We're building an internal tool that generates SQL queries from natural language descriptions. This is for our data analysts who understand databases but get tired of writing the same JOINs repeatedly.
Initial evaluation: Claude wins handily. It generates more correct queries, handles complex joins better, and produces cleaner SQL. We're ready to ship when someone asks: "What happens when the conversation gets long?"
Oh.
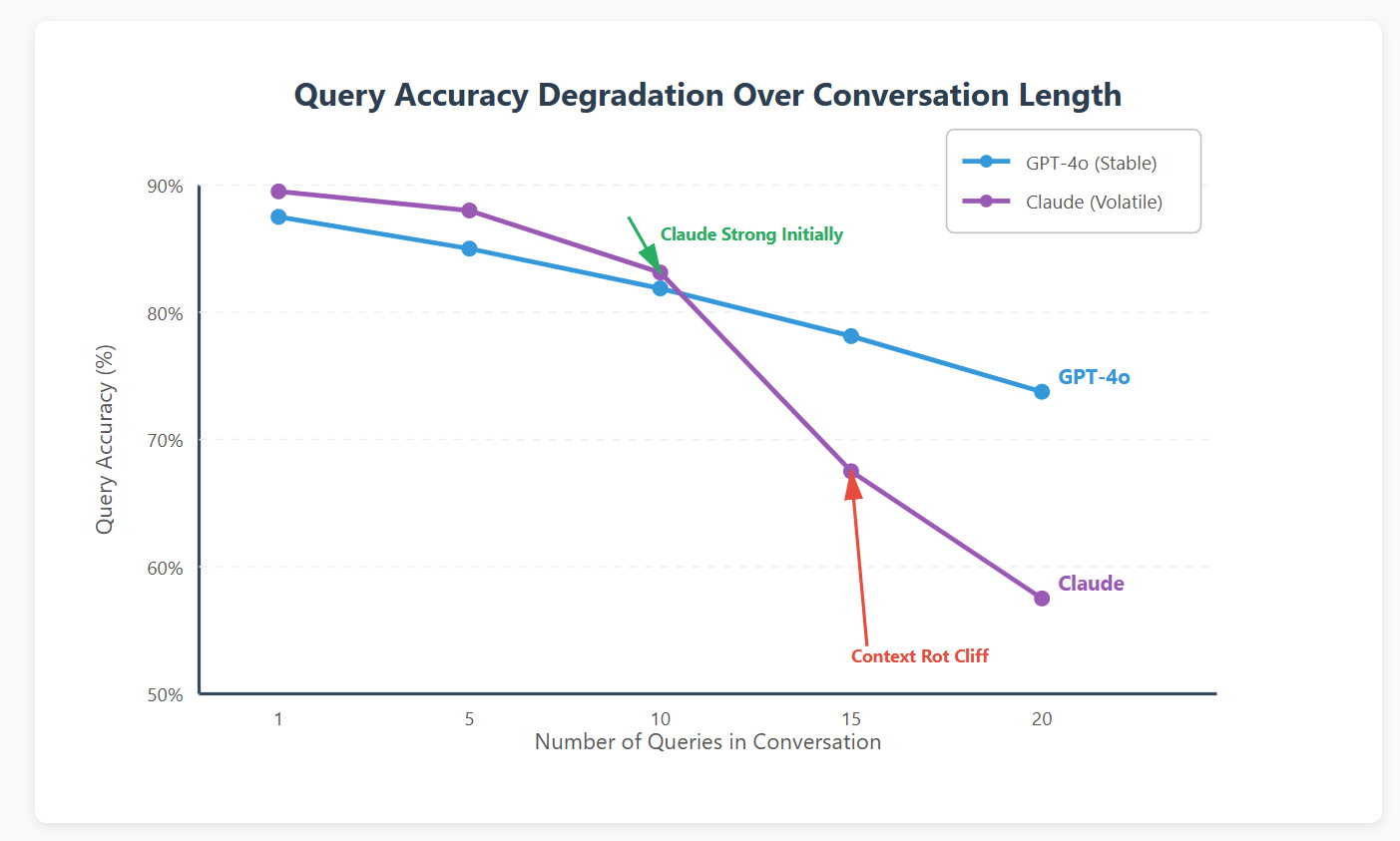
We tested both models across conversation lengths from 1 to 20 queries. Claude started at 89% accuracy for single queries but crashed to 58% by query 15. GPT-4o started lower at 84% but only degraded to 73% at query 20.
Here's what we think happens: Claude's longer context window (200K tokens) becomes a curse rather than a blessing. It tries to maintain perfect coherence across the entire conversation, which means it starts hallucinating table relationships and column names from earlier queries. GPT-4o's shorter effective context means it "forgets" older queries faster, treating each request more independently.
Why Context Rot Didn't Matter
Here's the thing about our SQL generation use case: our analysts rarely go beyond 5-6 queries in a session. They generate a query, copy it to their SQL client, run it, see the results, maybe iterate once or twice, then start fresh.
We analyzed 3 months of internal usage data:
Actual Usage Patterns:
- 78% of sessions: 1-3 queries
- 18% of sessions: 4-7 queries
- 4% of sessions: 8+ queries
- Median session length: 2 queries
- 95th percentile: 6 queries
Claude's catastrophic failure mode (context rot at 15+ queries) happened in less than 1% of real usage. Meanwhile, Claude's superior performance on short conversations (where 96% of our usage happened) meant better queries for the vast majority of use cases.
# Simple failure tolerance calculation
claude_short_session_value = 0.96 * 0.89 # 96% of sessions, 89% accuracy
claude_long_session_value = 0.04 * 0.58 # 4% of sessions, 58% accuracy
claude_total = claude_short_session_value + claude_long_session_value # = 0.8544 + 0.0232 = 0.8776
gpt4o_short_session_value = 0.96 * 0.84
gpt4o_long_session_value = 0.04 * 0.73
gpt4o_total = gpt4o_short_session_value + gpt4o_long_session_value # = 0.8064 + 0.0292 = 0.8356 # Claude wins: 0.8776 > 0.8356We chose Claude because its failure mode (long conversations) aligned with our actual usage patterns (short conversations). GPT-4o's stability across conversation length was solving a problem we didn't have.
Production Outcome: Six months in, Claude generates ~2,400 SQL queries per week for our analytics team. Query accuracy in production: 91% (higher than testing because analysts provide more schema context). We've had exactly 3 tickets about "weird behavior in long conversations" we just tell people to start a new chat. The failure mode is both rare and easy to work around.
Case Study 3: The Customer Service Bot That Needed Predictable Failures
Third case: customer service chatbot for an e-commerce platform. Returns, exchanges, order status, basic troubleshooting. The team wanted Claude because it handled edge cases better and had more natural conversational flow.
I pushed back hard. Here's why.
In customer service, the worst thing you can do is surprise your support team. They need to know when to intervene, what escalation looks like, and how to train new agents. Unpredictable AI behavior creates chaos.
We ran a different kind of evaluation: failure predictability analysis. We took 1,000 customer service conversations and deliberately corrupted them missing order numbers, contradictory information, unclear intent, multiple issues in one message. Then we tracked which types of corruption caused which types of failures.
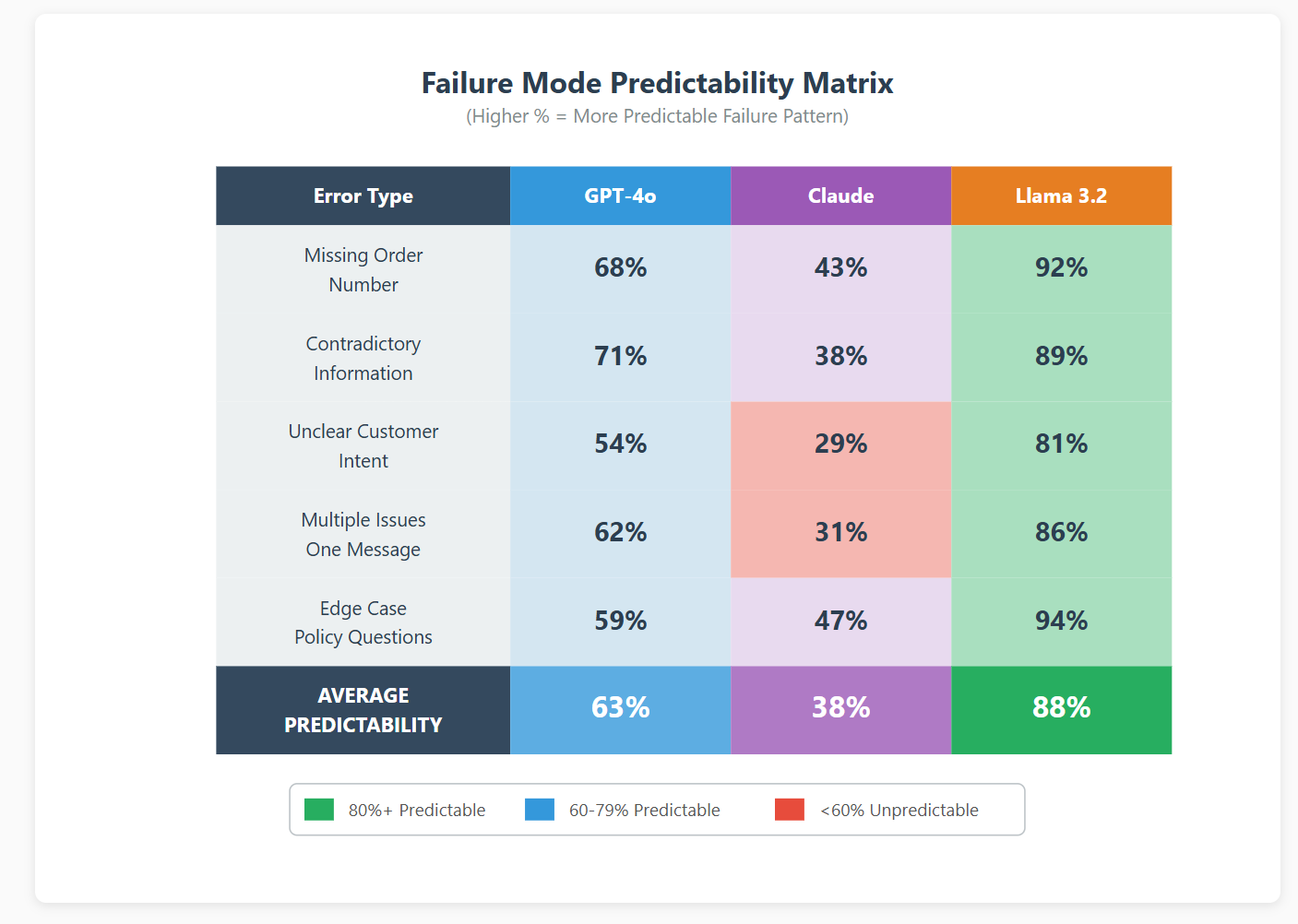
The results were eye-opening. Llama 3.2's failures were incredibly predictable 88% average predictability across all error types. When it failed, it failed the same way every time. Missing order number? It would always ask for it in the same phrasing. Contradictory info? Always escalated to human support with a specific template response.
Claude was the opposite 38% predictability. Sometimes it would hallucinate order details, sometimes it would ask clarifying questions, sometimes it would make educated guesses. There was no consistent pattern our support agents could learn.
Why Predictability Trumped Capability
Here's what our support team lead told me: "I don't care if the AI is occasionally wrong. I care if I can teach my agents what 'AI wrong' looks like."
With Llama 3.2, we could create a 2-page training document:
- If the bot asks for order number in this exact way ? customer forgot to provide it
- If the bot says "I'll escalate to a specialist" ? contradictory information detected
- If the bot lists multiple issues separately ? customer has compound problem
- If the bot says "Let me transfer you to a human agent who can help with policy questions" ? edge case policy situation
New support agents could be trained in 30 minutes. They knew exactly when the bot needed help and what type of help it needed.
With Claude, we'd need to say "sometimes it does X, sometimes Y, sometimes Z, just kind of watch for things that seem off." That's not trainable. That's chaos.
The Real Cost of Unpredictability: We calculated that Claude's unpredictable failures increased average training time for new support agents from 2 hours to 16 hours, and they still made escalation mistakes 3x more frequently in their first month. Annual cost of poor escalation decisions: ~$180K in wasted support time and customer frustration.
Yes, Claude handled more edge cases correctly. But when it failed, the failure was different every time, which meant our human support team couldn't build muscle memory around intervention points.
Llama 3.2's lower overall accuracy (76% vs Claude's 84%) was offset by the fact that our support team could catch and correct its failures reliably. Effective accuracy = Model Accuracy Human Catch Rate.
Claude: 84% × 38% = 31.92% of failures corrected
Llama: 76% × 88% = 66.88% of failures corrected
Effective accuracy:
Claude: 84% + (16% × 31.92%) = 89.1%
Llama: 76% + (24% × 66.88%) = 92.1%Production Outcome: Eight months running with Llama 3.2 handling ~15,000 customer conversations monthly. Support agent training time: 2.5 hours average. Escalation accuracy: 94%. Customer satisfaction with AI interactions: 4.2/5. We sacrificed the ceiling (Claude's edge case handling) for a higher floor (predictable, trainable failure modes).
The Pattern: Aligning Failures with Your Operating Model
These three cases taught us something crucial: LLM selection isn't about benchmarks. It's about aligning the model's failure characteristics with your operational reality.
Ask yourself these questions:
- Can your humans detect the failures? (Healthcare: chose detectability over accuracy)
- Do the failures happen in scenarios that matter? (SQL generation: chose performance in common cases over edge case stability)
- Can your team be trained to handle the failures? (Customer service: chose predictability over capability)
Every LLM has a failure surface. The winning model isn't the one with the smallest failure surface it's the one whose failure surface maps to your organization's ability to detect, tolerate, and correct those failures.
Stop optimizing for perfect happy paths. Start optimizing for survivable failure modes. That's how you actually ship AI systems that work in production.
Coming in Part 4: We'll dive into the Production Failure Testing Suite * Actual code examples for testing each failure mode * How to document your "acceptable failure budget" per use case * The Failure Profile Matrix: matching your use case failure tolerance to LLM failure patterns.
Opinions expressed by DZone contributors are their own.
Comments