Tools for Building Deterministic LLM Systems
LLMs are never deterministic, but with sufficient testing, you can push LLM-driven workflows close to the reliability bar of traditional software.
Join the DZone community and get the full member experience.
Join For FreeIt’s hard to imagine a world without LLMs nowadays. I rarely reach for Google when ChatGPT can provide me a much more curated answer with almost all the context it could need. However, these daily use cases often lean in creative directions.
In the context of B2B systems, that same creativity that provides so much usefulness in day-to-day is not acceptable.
This became clear when I first pitched the idea of using LLM-powered browser agents to fill out job application forms on behalf of job boards and agencies. A “small” mistake or hallucination, like choosing the wrong answer in a screening question, skipping a mandatory field, or hallucinating a value, means:
- The candidate never reaches the employer’s ATS
- Attribution breaks
- The impression of your system instantly becomes “creates spam”
Our product is nowadays pushing tens of thousands of applications through enterprise workflows, and “usually works” is not good enough. We need deterministic outcomes: for a given input, your system should produce the same, valid, structurally correct output nearly all the time.
This article will cover some tools and patterns we’ve used to make the LLM-driven systems behave much more like deterministic software. The following examples are currently deployed to power an otherwise non-deterministic technology for enterprise customers, and they allow us to both harness the flexibility of LLMs while building software our users can trust.
Determinism Can Be Viewed Across a Spectrum
LLMs are never deterministic in the strict “same output every time” sense. Even with temperature=0. In practice, you can treat determinism as a spectrum:
- Hard constraints: “The output must be valid JSON matching this schema.”
- Soft constraints: “The extracted field must match one of these 12 allowed options.”
- Behavior consistency: “Given this distribution of inputs, how often does the system produce the correct, structurally valid result?”
You will never get 100% reliability everywhere. But you can get close enough, know where the risk lives, and design the surrounding system so the rare failures are caught and handled.
The techniques below describe how to build a system with different guardrails that allow you to trust the output to be what you need it to be.
Structured Output: The Most Obvious and Biggest Win
The simplest and most powerful tool is to force structure.
OpenAI had it for a long time, and Anthropic has now followed suit. Instead of asking the model to please follow some JSON output format, APIs allow you to specify a JSON schema within the generation, forcing the LLM to generate tokens matching your schema:
This is non-negotiable. To attempt to build a deterministic system, you need to know what the LLM will give you.
For example, we use this to:
- Turn arbitrary job forms into a consistent representation of fields
- Let the LLM pick a field’s question type between a set of enum options.
With structured output, your downstream logic can be regular code that expects clear types.
Testing With Iterations: Measuring Your Determinism
Once you have structured output and validation, you can start testing and measuring determinism instead of guessing.
The core idea: run the same task many times and see how often it behaves correctly.
If you’re lucky, you can test for concrete values and write standard test assertions. If you’re generating more abstract outputs, you may need to use another LLM as a ‘judge’ to test your output.
For example, we:
- Created a fixture of a job posting, asking the LLM to return the fields it can find in the form
- Ran this test over 50 iterations
- Asserted that for each iteration, we get the correct number of fields with matching labels
If 49 out of 50 runs are valid and correct, you know your success rate is 98%.
That doesn’t mean 98% in production (as your input data will differ), but it gives you a baseline and lets you compare prompts, models, or schemas objectively. This is also crucial for building a reliable system that does not have regressions.
In practice, this is how we iterate:
- Add fixture that caused problems.
- Change the prompt or schema to fix the problem.
- Re-run the test harness for 50–100 iterations on the new fixture set.
- Ship if you can validate a core improvement
This is also where people underestimate the importance of writing good tests. You want:
- A simple CLI/test framework with which you can run your tests many times.
- Outputs that are easy to compare (“95% valid JSON, 90% fully correct vs. 98% / 95% after change”).
For browser automation, I can highly recommend testing via Playwright’s own UI. For browser automation tasks, it’s often very feasible to let the LLM decide on one operation and make a Playwright assertion on that output.

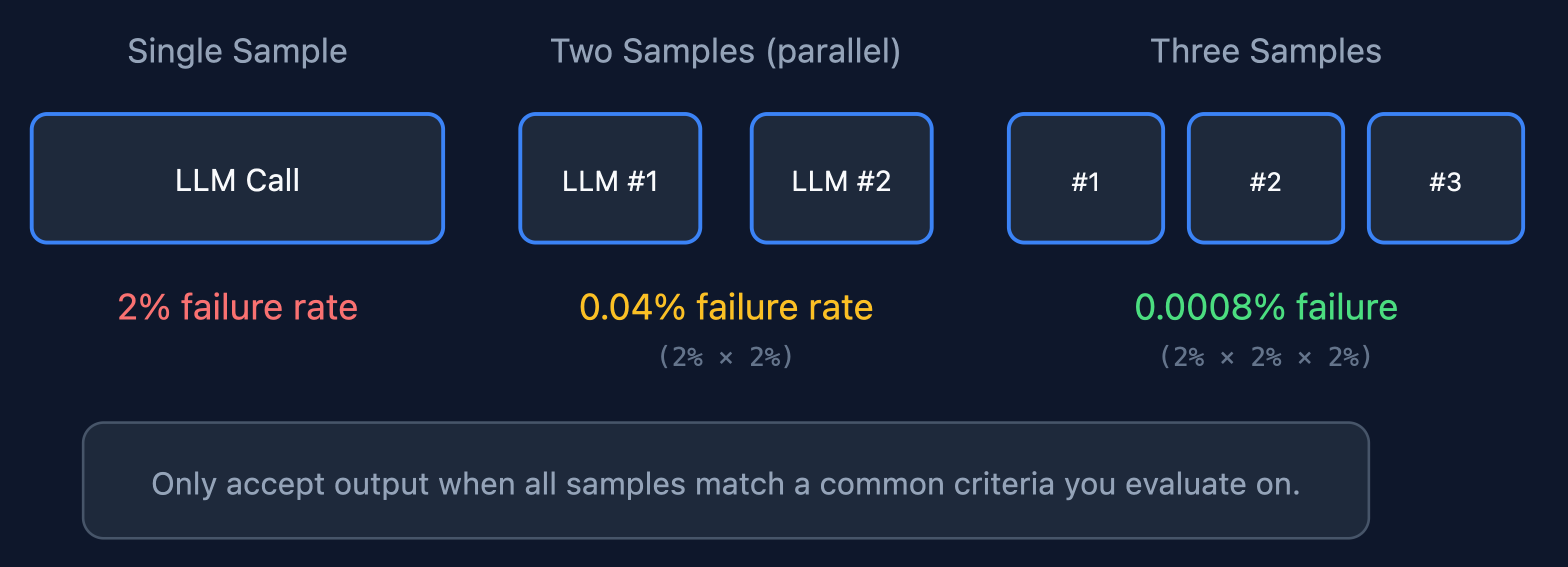
Taking Multiple Samples: Compounding Probabilities
Say your workflow, as measured above, has a ~2% failure rate on structure or correctness.
If you run the pipeline twice on the same input, and only accept the result if both outputs agree, then the probability that both runs fail in the same way is dramatically smaller.
Assuming a 2% failure rate, we’ve now decreased the failure rate to 0.04% (2% * 2%).
You can extend the idea while keeping in mind the cost implications. Latency should not change, as this is easily done in parallel.
In practice, while you may not want to take multiple samples for every operation, this is a priceless method to reduce uncertainty when it comes to critical operations for your agent.
Resolving Inconsistencies via an LLM
Once you’re taking multiple samples to reduce the failure rate, you’ll notice that your agent sometimes fails too easily. For example, your output consistency check may be too strict, or it may simply be hard to resolve if two outputs are the same.
Throwing them away is expensive. Instead, you can ask another LLM to act as a judge during runtime. A prompt like the following can be used, usually passing the same system prompt as the original generation, so that the judge has all the context necessary:
“You are a strict judge. You receive two candidate generations of the same input and the original input text. Your job is to select the index of the correct generation, or return -1 if none are suited”.
This gives you two wins:
- You can salvage cases where one sample is clearly wrong, and the other is fine.
- You have a principled way to admit uncertainty and fall back to a slower path (manual review, different model, etc.) with -1.
Verification Loops: Letting LLMs Check Their Own Work
The final layer is to think of your LLM pipeline as a loop, not a single shot.
This is what is also often described as a true “agent” architecture: letting an LLM-based system decide its own path and decide when it is done.
In practice, you’d be surprised how well a second LLM, even the same model, is able to judge if the previous generation was correct or not.
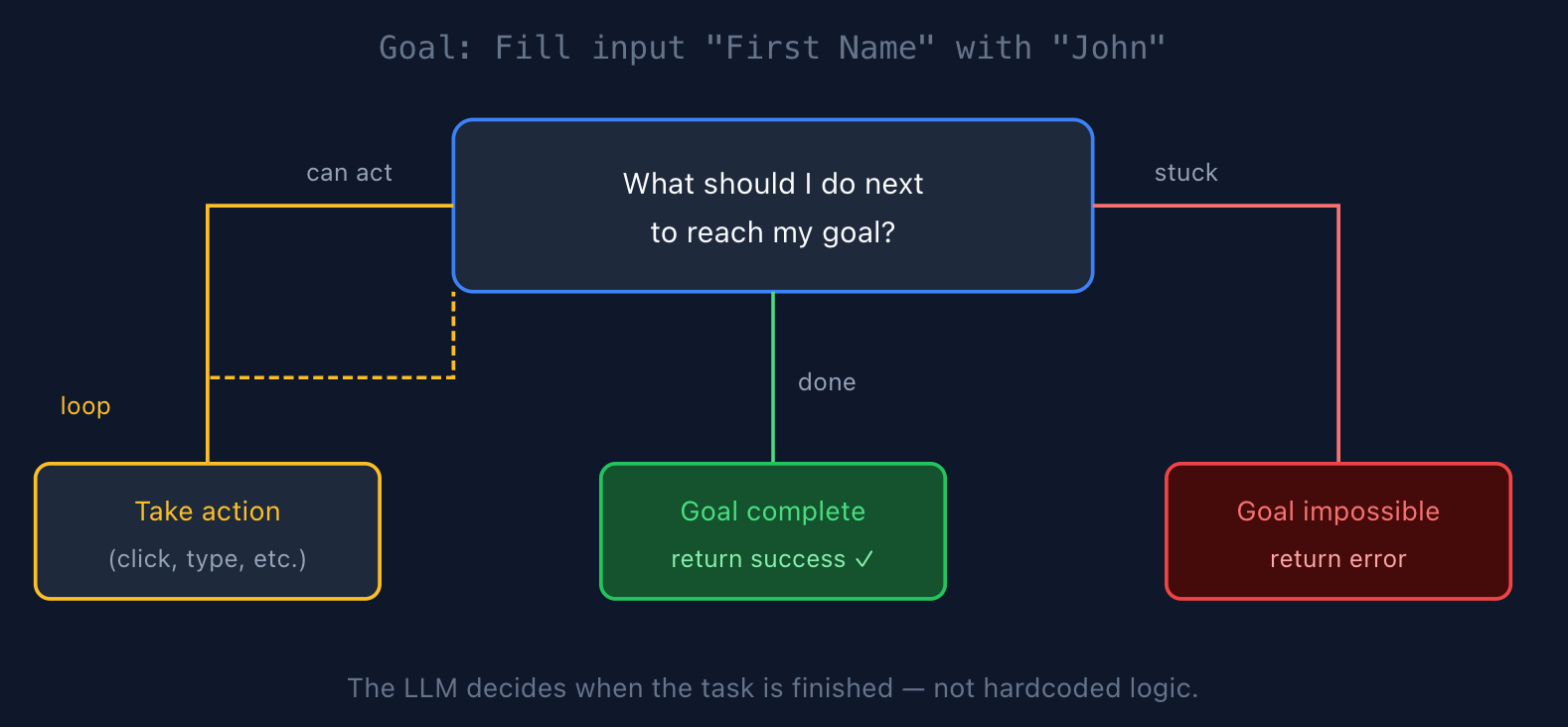
You can build a system where your task always runs in a loop of asking the LLM:
- What should I do next to reach my goal?
- If I can’t take the next step, is my goal complete?
- If I can’t take the next step and the goal is not complete, is my goal impossible?
Doing so will let the LLM decide for itself once enough uncertainty is resolved. And you can, of course, combine this with another technique, running two of these loops in parallel, etc.
Putting It All Together
LLMs are inherently never deterministic, but there are a surprising number of tricks you can use to build a system where you can fully trust the output to be what you expect.
By combining the above ideas, you can push LLM-driven workflows close to the reliability bar of traditional software — high enough that enterprise customers are willing to put real money and processes on top of it.
For our agentic job applications, that means letting job boards and agencies trust an LLM-powered agent to submit large volumes of applications into ATS systems they don’t have API access to. It’s inherently high-risk, as you can’t afford to hallucinate candidate input, but by sufficient testing, you can build a system you can trust.
Opinions expressed by DZone contributors are their own.
Comments