Is TOON the Next Lightweight Hero in Event Stream Processing With Apache Kafka?
Majorly beneficial for LLM-specific pipelines, we can use TOON to ingest stream data into an Apache Kafka topic, as it's a compact, token-efficient serialization format.
Join the DZone community and get the full member experience.
Join For FreeThe data serialization format is a key factor when dealing with stream processing, as it decides how efficiently the data is forwarded on the wire and optimized internally in order to be stored, understood, and processed by a distributed system. The data serialization format is core to stream processing in that it directly influences the speed, reliability, scalability, and maintainability of the entire pipeline. Choosing the right one can eliminate expensive lock-ins and ensure that our streaming infrastructure remains stable as data volume and intricacy evolve.
In a stream-processing platform where millions of events per second must be handled with low latency by ingestion systems such as Apache Kafka and processing engines like Flink or Spark, reducing CPU usage is important, as it depends on efficient data formats.
Exploring TOON as a Data Format
Early in the new millennium, Douglas Crockford popularized JSON, which was designed with humans in mind. For APIs to consume data or return responses, it is ubiquitous, readable, and accessible. However, one drawback of JSON has been apparent in the current AI era: it is rather verbose. Additionally, real-time data streaming has started having an important impact on modern AI models for applications that need quick decisions.
TOON stands for Token-Oriented Object Notation, a lightweight, line-oriented data format. It is too human-readable (more than binary formats), like JSON, but more compact and structured than raw text. TOON is built to be very simple to parse, where each line or “entry” begins with a token header (uppercase letters or digits), then uses pipe separators (|) for fields.
Given the importance of streaming environments, it is optimized to be line-oriented, and we do not need to build a full in-memory parse tree (unlike JSON), which makes it suitable for low-memory contexts, embedded systems, or logs. Here is a simple example of JSON with a shoes array that contains information about two shoes (two objects):
{
"shoes": [
{ "id": 1, "name": "Nike", "type": "running" },
{ "id": 2, "name": "Adidas", "type": "walking" }
]
}Now, let’s convert the same data above into TOON, the it will be like below.
shoes[2]{id,name,type}:
1, Nike, running
2, Adidas, walkingSimple, right? Because in TOON, we don’t need quotes, braces, or colons. The lines are simply the data rows and shoes[2]{id,name,type}: declares an array of two objects with the fields id, name, and type. Now we can see how TOON visibly reduced the token usage by 30–50%, depending on the data shape
Is TOON Better Than JSON?
As we know, real-time data streaming plays a key role for AI models as it allows them to handle and respond to data as it comes in, instead of just using old fixed datasets. To build or develop such a platform or architecture where processed streaming data eventually feeds into AI systems like TensorFlow, etc, TOON provides several key advantages over JSON, especially for large language models (LLMs), where JSON is considered to be heavyweight for data exchange because of thousands of tokens in quotes, braces, colons, and repeated keys.
Using TOON, we can reduce token usage by 30-50% for uniform data sets, and it has less syntactic clutter, which makes it easier for LLMs. Besides, TOON can be nested, similar to JSON. Similar to JSON, TOON can have a simple object, an array of values, an array of objects, and an array of objects with nested fields. In the case of an array of objects with nested fields, TOON can be much more understandable and much smaller than JSON. TOON is a token-efficient serialization format that is primarily designed for streaming, low-memory environments, and LLM contexts.
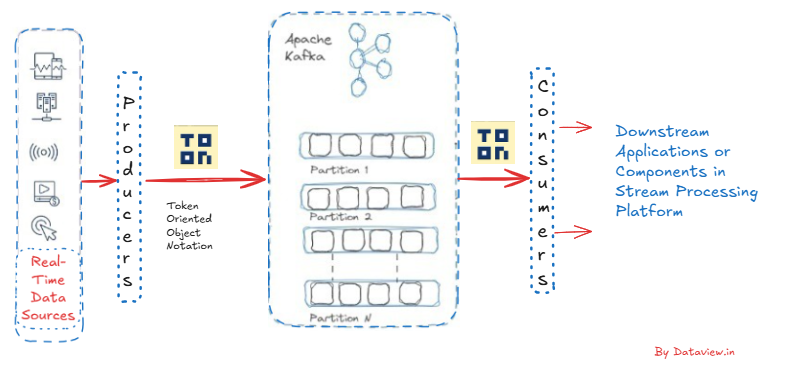
What More for Apache Kafka
Before ingesting data streams from various real-time sources via producers into the multi-node Apache Kafka cluster, we first require a TOON parser that can translate its unique structural markers into a common internal representation like JSON, as TOON is usually a hierarchically annotated, nested format. Secondly, there should be an implementation of a schema-extraction layer for the TOON data format to normalize fields such as rich metadata and embedded annotations. To enforce consistent types before producing messages to Kafka’s topic, the former step is necessary.
On top of that, we need to have data validation rules so that malformed frames or unsupported TOON constructs can be handled. Besides, if the input stream data format carries large embedded objects from the producers to Kafka's topic, then pre-serialization compression is essential. And we should design a proper Kafka message key mechanism that is specific to TOON identifiers in order to preserve ordering and enable efficient deserialization for the consumers in downstream applications. The community-driven Java implementation of TOON has been released under the MIT license on GitHub and can be useful if message producers are to be developed using Java.
Takeaway
TOON is a new data serialization format designed to reduce the number of tokens when exchanging structured data, primarily with language models. Although majorly beneficial in LLM-specific pipelines, we can use it to ingest stream data into Apache Kafka's topic, as it's a compact and token-efficient serialization format. TOON is not Kafka-native and still relatively young compared to JSON, Avro, or Protobuf. JSON or binary formats might be better for deeply nested structures or highly heterogeneous data for incoming messages to Kafka's topic.
As TOON is not widely supported yet, we may need to write custom serializers/deserializers while integrating with existing message producers and consumers for downstream applications/components across the entire stream processing platform. If we are especially concerned with efficient parsing and minimizing overhead, then TOON could be a very well-suited message payload format for Apache Kafka.
Thank you for reading! If you found this article valuable, please consider liking and sharing it.
Published at DZone with permission of Gautam Goswami. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments