Disabling UseNUMA Flag When CPU and Memory Node Misalign in JDK
In this blog, I share why we should disable UseNUMA flag in JDK in case both CPU and memory node misalign. Please go through the blog for details.
Join the DZone community and get the full member experience.
Join For FreeToday, Java is still one of the widely used languages to build and run applications, and for the same reason, organizations prioritize measuring its performance.
When running a Java application on a multi-NUMA (Non-Uniform Memory Access) memory node, we need to pay attention to the remote accesses, if any, otherwise, that can result in increased latencies and hence result in reduced performance. The libnuma kernel library provides several policies, including localalloc, preferred, membind, and interleave, which enable users to affinitize their applications and run them with optimal utilization of the server nodes as per their requirements.
Before understanding the issue, we must have an idea about these policies:
- Localalloc is the policy that allows the user to run an application in such a way that memory is allowed to allocate on nodes that are bound through cpunodebind, and in case these NUMA nodes fall short for memory allocation, the application can consume the memory from other NUMA nodes, which means that this policy does not restrict the memory allocation to only a single NUMA node.
- Preferred is the policy that allows users to specify the node for allocation, but again does not restrict the allocation to the same node.
- Membind policy is more restrictive for memory allocation, which allows the application to allocate memory on only the nodes that are specified.
- Interleave policy allows the application to span across the specified nodes equally.
Along with the policy, there are kernel calls to set the mode for memory allocation; further details can be found here.
What Is the Problem With the Current Scenario?
We identified an issue in the memory allocation in JDK with the above policies, as when the application’s affinity is set to a single NUMA node using localalloc, the memory gets interleaved and causes performance degradation, which we observed with all types of GC, such as ParallelGC, G1GC, and ZGC.
We observed the performance issues related to the flag UseNUMA, as when the flag is enabled, the JVM decides to interleave memory among all NUMA nodes, and the CPU threads' access is remote, which causes the performance degradation.
With the figure below, you can understand the binding scenario of CPU and memory. Here, CPU node 0 threads are using memory node 0, and there is a remote access to memory nodes 1, 2, and 3, which is detrimental to performance.
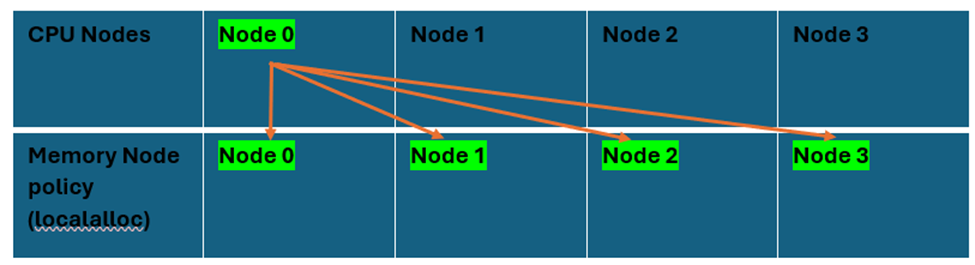
With the GC logs, the issue becomes clear:
Test Case
Bind CPU nodes, and set --localalloc.
numactl -N 0 --localalloc java -Xlog:gc*=info -XX:+UseParallelGC -XX:+UseNUMA -version Here, we observe that the failed output shows half of Eden being wasted for threads from a node that will never allocate:
[0.230s][info][gc,heap,exit ] eden space 524800K, 4% used [0x0000000580100000,0x0000000581580260,0x00000005a0180000)
[0.230s][info][gc,heap,exit ] lgrp 0 space 262400K, 8% used [0x0000000580100000,0x0000000581580260,0x0000000590140000)
[0.230s][info][gc,heap,exit ] lgrp 1 space 262400K, 0% used [0x0000000590140000,0x0000000590140000,0x00000005a0180000) Before the fix, we observed that, as per the above GC logs, the Eden space gets further divided into lgroups based on the total number of NUMA nodes configured on the system, and ignoring the user bindings.
The Proposed Solution
We proposed a solution to disable the UseNUMA flag when the process gets invoked with incorrect node alignment. We check the NUMA node misalignment through the method numa_equal_bitmask, which returns true if there is a CPU and memory node misalignment with the user-specified binding.
We check the cpunodebind and membind (or Interleave for interleave policy) bitmask equality and disable UseNUMA when they are not equal.
Node Number 0123
1100 cpunodebind
1111 membind Disable UseNUMA as CPU and memory bitmask are not equal.
The figure below shows that there is remote access to other NUMA nodes.
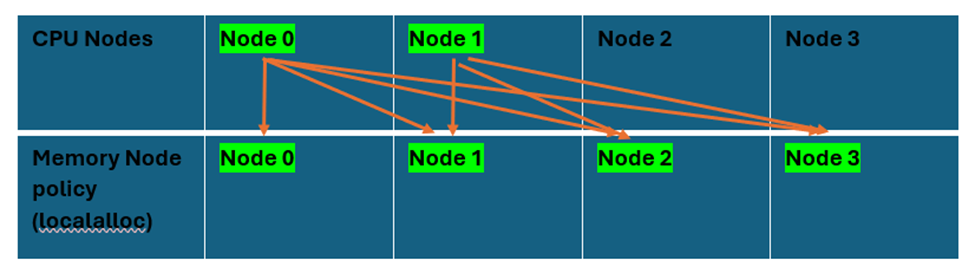
Node Number 0123
1100 cpunodebind
1100 membind Enable UseNUMA as CPU and memory bitmask are equal.
The figure below shows a cleaner approach when there is no remote access.
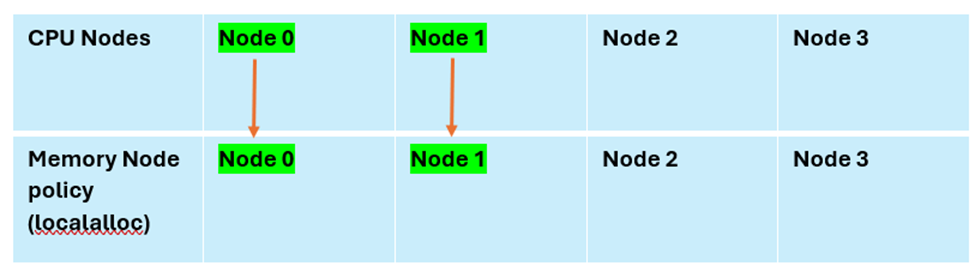
This covers all the cases with all policies, and we have tested with below command:
numactl --cpunodebind=0 --localalloc java -Xlog:gc*=info -XX:+UseParallelGC -XX:+UseNUMA -version For Localalloc and Preferred policies the membind bitmask returns true for all nodes, hence if cpunodebind is not bound to all nodes the UseNUMA will get disabled.
Bug-ID: Poor performance with UseNUMA when CPU and memory nodes are misaligned.
PR link: (https://github.com/openjdk/jdk/pull/22395)
With profiling data this is evident that remote access exists, also the CPU utilization drops by 20% before applying the patch.
After fix we observed that no lgroups are created as UseNUMA gets disabled when bound to a single node, here good output is not listing any lgrp in the output:
[0.231s][info][gc,heap,exit ] eden space 524800K, 8% used [0x0000000580100000,0x0000000582a00260,0x00000005a0180000)
... (no lgrps)As a solution, a warning was printed when the UseNUMA flag was disabled, but this caused a few tests to fail, so another fix removed the log warning for a single NUMA node.
Bug-ID: https://bugs.openjdk.org/browse/JDK-8346834
PR link: https://github.com/openjdk/jdk/pull/22948
How You Can Test
Both flags UseNUMA and UseNUMAInterleave are disabled or enabled based on the numa binding and configuration.
| test cases | |||||
|---|---|---|---|---|---|
|
CPU Binding |
Memory Binding |
Node Binding |
Before Patch |
After Patch |
Expected Outcome |
|
cpunodebind=0 |
Membind=0 |
single node |
Disabled |
Disabled |
Disable NUMA |
|
cpunodebind=0 |
Membind=0,1 |
node mismatch |
Enabled |
Disabled |
Disable NUMA |
|
cpunodebind=0,1 |
Membind=0,1 |
multi node with node match |
Enabled |
Enabled |
Enable NUMA |
|
N/A |
N/A |
- |
Enabled |
Enabled |
Enable NUMA |
|
|
|
||||
|
cpunodebind |
interleave |
single node |
Enabled |
Disabled |
Disable NUMA |
|
cpunodebind |
interleave |
node mismatch |
Enabled |
Disabled |
Disable NUMA |
|
cpunodebind |
interleave |
multi node |
Enabled |
Enabled |
Enable NUMA |
|
|
|
|
|
|
|
|
cpunodebind |
localalloc |
single node |
Enabled |
Disabled |
Disable NUMA |
|
cpunodebind |
localalloc |
node mismatch |
Enabled |
Disabled |
Disable NUMA |
|
cpunodebind |
localalloc |
multi node |
Enabled |
Enabled |
Enable NUMA |
|
|
|
|
|
|
|
|
cpunodebind |
preferred=0 |
single node |
Enabled |
Disabled |
Disable NUMA |
|
cpunodebind |
preferred=0 |
node mismatch |
Enabled |
Disabled |
Disable NUMA |
|
cpunodebind |
preferred |
multi node |
Enabled |
Enabled |
Enable NUMA |
|
N/A |
preferred |
multi node |
Enabled |
Enabled |
Enable NUMA |
With the cases above, you can test by running with previous JDK (JDK 24 and older) versus JDK 25 to verify the effect. The command below is sample to test with different policies and with GC algorithms:
numactl --cpunodebind=0 --localalloc java -Xlog:gc*=info -XX:+UseParallelGC -XX:+UseNUMA -version What Is the Impact?
We observed the below performance improvement in both server-side Java throughput and server-side Java throughput under SLA after applying the patch on a 2 NUMA node system with, the similar impact can be observed on a higher (more than 2) NUMA node system.
The performance improvement we observed after applying the fix:
Server-side Java Application |
Performance Improvement % | |
|---|---|---|
|
GC Type |
Server-side Java throughput (in %) |
Server-side Java throughput under SLA (in %) |
|
Parallel GC |
8.41 |
7.19 |
|
G1GC |
24.39 |
25.59 |
|
ZGC |
18.43 |
21.58 |
Conclusion
JDK25 and onwards UseNUMA flag will be disabled in case the memory and CPU are not aligned. The perception generally developers have is that localalloc is same as membind but that’s not the scenario as localalloc allows memory allocation on other NUMA nodes in case the current node is out of memory whereas membind restricts the allocation to the bound node.
References:
- https://man7.org/linux/man-pages/man2/set_mempolicy.2.html
- https://man7.org/linux/man-pages/man8/numactl.8.html
Note: I would like to thank Derek White and Sourav Paul from Intel for their guidance and a thorough technical review of this blog.
Disclaimer: The views, information or opinions expressed in this technical blog are my personal views/opinions and not of my employer Intel Technology India Pvt Ltd.
Opinions expressed by DZone contributors are their own.
Comments