Variations With Stable Diffusion Depth2Img: A Step-By-Step Guide
A beginner's guide to preserving shape and depth in AI-Generated art, using Stable Diffusion Depth2Img and Node.js
Join the DZone community and get the full member experience.
Join For FreeLet me introduce you to an AI model that can transform an image while retaining its depth and shape. It's called stable-diffusion-depth2img, and it's a remarkable tool that can help you create breathtaking art and visual effects. In this guide, we'll dive into the details of how this model works and how you can use it to create some fantastic visuals. We'll follow a step-by-step guide to run the model using Node.js.
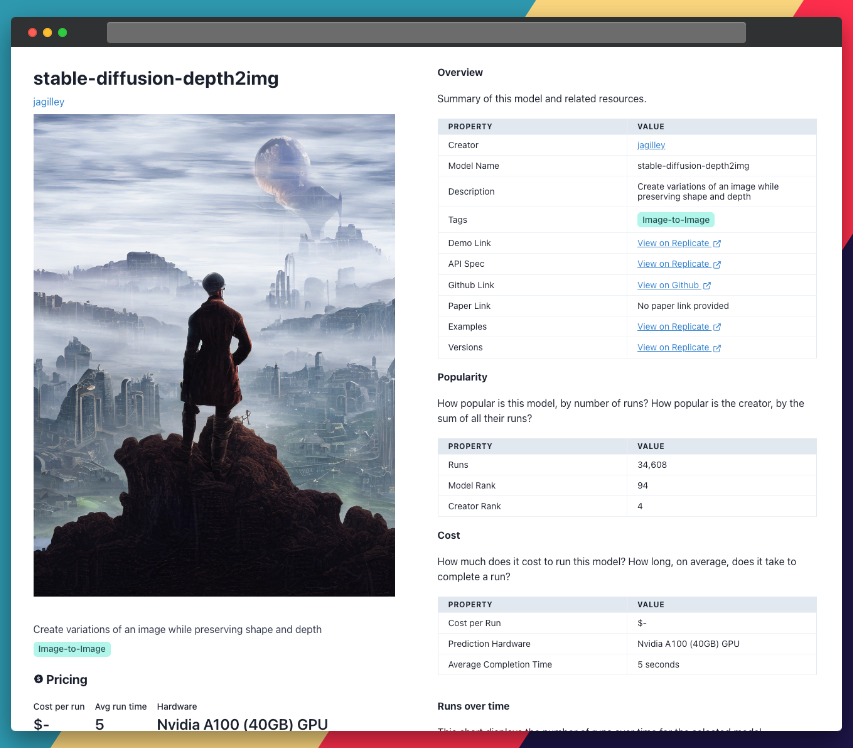
We'll also see how we can use Replicate Codex to find similar models and decide which one we like. Replicate Codex is a free tool that lets you explore and compare AI models, so you can find the one that best fits your needs. Let's begin!
About Stable-Diffusion-Depth2Img
Stable-diffusion-depth2img, created by Jagilley, is an enhanced version of image-to-image AI models. It takes an image and a text prompt as inputs, synthesizing the subject and background separately. In the process, it provides better control over the final output. The model achieves this by estimating the depth map of the input image using MIDAS, an AI model developed in 2019 for monocular depth perception.
A depth map is a grayscale image encoding the depth information of the original image. The more white an object appears the closer it is; the more black, the further away. With this depth map in hand, stable-diffusion-depth2img generates a new image based on three conditions: the text prompt, the original image, and the depth map.

This model's ability to differentiate between the foreground and background allows for better control and customization of the generated image.
Plain English Explanation
Imagine you have an image of a beautiful landscape, and you want to turn it into a futuristic scene. You'd provide stable-diffusion-depth2img with your image and a text prompt like "futuristic landscape." The model will first estimate the depth of objects in the scene and use this information to create an image with a futuristic feel while preserving the shape and depth of the original landscape.
There are some limitations to the model, such as the accuracy of depth estimation, which could impact the final result. Nonetheless, stable-diffusion-depth2img is a fantastic tool for creating AI-generated art, visual effects, and other creative projects.
Understanding the Inputs and Outputs of Stable-Diffusion-Depth2Img
Let's take a look at the model's expected inputs and outputs before we start working with it.
Inputs
prompt: The text prompt to guide the image generation.negative_prompt: Keywords to exclude from the resulting image.input_image: The input image to be used as the starting point.prompt_strength: Prompt strength when providing the image. A higher value corresponds to more destruction of information in the initial image.num_outputs: Number of images to generate.num_inference_steps: The number of denoising steps. More steps usually lead to higher-quality images but slower inference.guidance_scale: Scale for classifier-free guidance. A higher value encourages images closely linked to the text prompt, usually at the expense of lower image quality.scheduler: Choose a scheduler.seed: Random seed. Leave blank to randomize the seed.depth_image: Depth image (optional). Specifies the depth of each pixel in the input image.
Outputs
The model returns a new image based on the provided input and parameters. The output comes in the form of a raw JSON object structured as follows:
{
"type": "array",
"items": {
"type": "string",
"format": "uri"
},
"title": "Output"
}Now that we've learned about the model's inputs and outputs let's dive into a step-by-step guide on how to use it.
A Step-By-Step Guide To Using Stable-Diffusion-Depth2Img
If you're not up for coding, you can interact directly with this model's "demo" on Replicate via their UI. This is a great way to play with the model's parameters and get quick feedback and validation.
If you're more technical and looking to build a cool tool on top of this model, you can follow these simple steps to use the stable-diffusion-depth2img model on Replicate.
Also, be sure to create a Replicate account and grab your API key for this project before you begin. You'll need it for the second step.
1. Install the Node.js Client
This step is pretty easy!
npm install replicate2. Set Up the Environment Variable
Copy your API token and authenticate by setting it as an environment variable:
export REPLICATE_API_TOKEN=[token]3. Run the Model
The great thing about Replicate is that you can do this with just a few lines of code. Substitute your input fields for whatever values you want.
import Replicate from "replicate";
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});
const output = await replicate.run(
"jagilley/stable-diffusion-depth2img:68f699d395bc7c17008283a7cef6d92edc832d8dc59eb41a6cafec7fc70b85bc",
{
input: {
prompt: "Wanderer above the sea of fog, digital art",
negative_prompt: "...",
input_image: "path to image...", //etc.
}
}
);Refer to the section above ("Inputs") for all the possible field values. For example, using the default values and the Replicate demo image can turn Caspar David Friedrich's wanderer into the image below:

Note how much of the structure and style is preserved from the input image:

You can also specify a webhook URL to be called when the prediction is complete. Check the webhook docs for details on setting that up.
Taking It Further: Finding Other Image-To-Image Models With Replicate Codex
Replicate Codex is an excellent resource for discovering AI models catering to various creative needs, including image generation, image-to-image conversion, and more. It's a fully searchable, filterable, tagged database of all the models on Replicate, allowing you to compare models, sort by price, or explore by the creator. It's free, and it also has a digest email that alerts you when new models come out so you can try them.
If you're interested in finding similar models to stable-diffusion-depth2img...
1. Visit Replicate Codex
Head over to Replicate Codex to begin your search for similar models.
2. Use the Search Bar
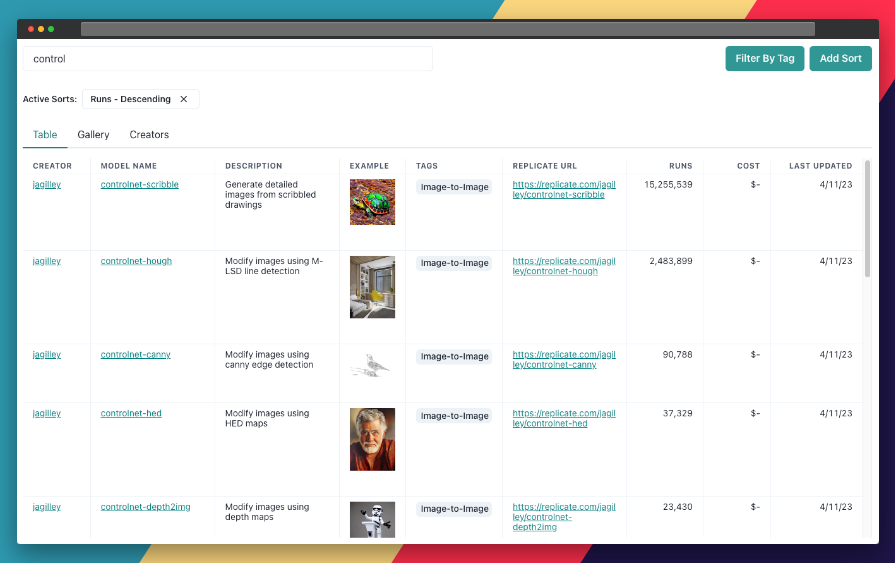
Use the search bar at the top of the page to search for models with specific keywords, such as "stable diffusion," "depth2img," or "controlnet" This will show you a list of models related to your search query.
3. Filter the Results
On the left side of the search results page, you'll find several filters that can help you narrow down the list of models. You can filter and sort models by type (Image-to-Image, Text-to-Image, etc.), cost, popularity, or even specific creators.
By applying these filters, you can find the models that best suit your specific needs and preferences. For example, if you're looking for a model that's the cheapest or most popular, you can search and then sort by the relevant metric.
Conclusion
In this guide, we've explored the creative possibilities of the stable-diffusion-depth2img model, which allows us to generate new images while preserving their shape and depth. We also discussed how to leverage the search and filter features in Replicate Codex to find similar models and compare their outputs, allowing us to broaden our horizons in the world of AI-powered image enhancement and restoration.
I hope this guide has inspired you to explore the creative possibilities of AI and bring your imagination to life.
Published at DZone with permission of mike labs. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments