What Do You Mean By a “Distributed Database?”
An overview of concepts, terms, and definitions, plus a survey of some of the most important players in both SQL and NoSQL distributed databases.
Join the DZone community and get the full member experience.
Join For FreeThe earthly landscape we walk upon usually changes very slowly. It’s measurable in centimeters or inches per year. But the digital landscape, and specifically the distributed database landscape, is changing at a massive rate. You can read more about the tremendous changes currently occurring in the industry in our recent blog on this next tech cycle.
Before we can look at the way these changes are impacting the distributed database landscape, we have to define what we mean by the term “distributed database.” That’s the purpose of this article.
Defining Distributed Databases
Just as there’s no ANSI or ISO or IETF or W3C definition of what a NoSQL database is, there’s no standard or protocol or consensus on what a “distributed database” is.
Thus, I took some time to write up my own definition of a distributed database, based on what I’ve experienced during my time at a couple of database developers in the industry. I am sure your own experiences might lead you to define such an ontology in a completely orthogonal manner. Plus, I’ll freely admit this is more of a layman’s pragmatic view tailored for a blog than a computer science professor’s proposal for an academic paper. With that disclaimer and caveat, let’s get into it.

Clustering and Distribution
First, let’s just vaguely accept the concept of “database” as a given — even though it can mean many things to many people — and focus instead on the word “distributed.”
To be distributed, I would argue, requires a database server running in more than one system on a network.
Now, if you’ve listened to ScyllaDB's CTO Avi Kivity, he will argue that a single modern multi-core, multi-CPU node already constitutes its own network, but we won’t explore that path today.
When the industry began, you had one giant node, often a mainframe, running your database. Or, by the 1980s, it could be running in your desktop computer. But it was considered “one thing.”
For the sake of this argument, we’ll define a node as a single computational whole — whether that node is a virtual instance carved out of a larger physical server as you might often find in the public cloud, or a complete physical server running your database, as you might find typically on-premises.
And we’ll define a cluster as comprising one or more nodes.
And thus, a distributed database needs to be running on a cluster of N nodes where N > 1.
But now that you have the database engine running across these multiple nodes, what do you do with your data? Do you split it as evenly as possible between them? That’s known as sharding. Or do you keep full copies on each of the nodes? That’s called replication and fully replicated at that.
There’s also the issue of physical distance between your servers because, as far as I know, databases need to obey the speed of light. And so if you need to keep your database in sync quickly, you need to make your cluster localized — in the same datacenter. It is a type of distributed database, but it’s just the beginning.
If you want to serve data close to users spread over a geographic area, you may be able to have multiple local clusters — one in the U.S., one in Europe, one in Asia. That keeps local user latencies low.
But now you may have your disparate local clusters intercommunicate through some sort of synchronization or update mechanism. For example, this is how DNS or Active Directory work. Each system works on its own, and there’s a propagation delay between updates across the different systems.
That might not be good enough for some production use cases, though. So if you are more tolerant to “speed of light” propagation delays and use what’s known as eventual consistency, you may be able to spread the cluster itself around the world. Some servers may be in the U.S., others in Europe or Asia. Yet, it’s all considered the same logical cluster.
Node Roles, High Availability, and Failover Strategies
Next, you have the role of the nodes in your database. Are they all peers, each capable of full writes, or are any of them designated as leaders or primaries with others designated as read-only replicas?
Back in the day, it was common to have a replica set aside as a “hot standby” only used in case the primary server went down — and that’s still a successful model for many systems. But that hot standby is not taking on any of the load. It’s sitting there idly humming just in case of emergency.
That’s why many people prefer peer-to-peer leaderless topologies, where everyone gets to share the load. And there’s no single point of failure, and no need to spend time hiccupping during failover.
In these so-called active-active scenarios, how to keep systems in sync is more complicated — it’s a tougher thing to do — but if you can solve for it, you’ve eliminated any single point of failure in your database.
Also, even if you have a distributed database, that doesn’t mean that your clients are aware of the topology. So people can either implement load balancers to front-end your distributed database, or they can implement client-side load balancing by making intelligent clients that know how your database is sharded and route queries to the right nodes.
Data Replication and Sharding
Now let’s look at these replication and sharding strategies. Like I said, you can make each node a full replica of the entire database. You could have, say, three full sets of data on three different servers, or you can distribute different pieces across multiple servers, sharded somewhat differently on each server, so that it’s more difficult to lose any one piece of data even if two or more servers in a cluster dies.
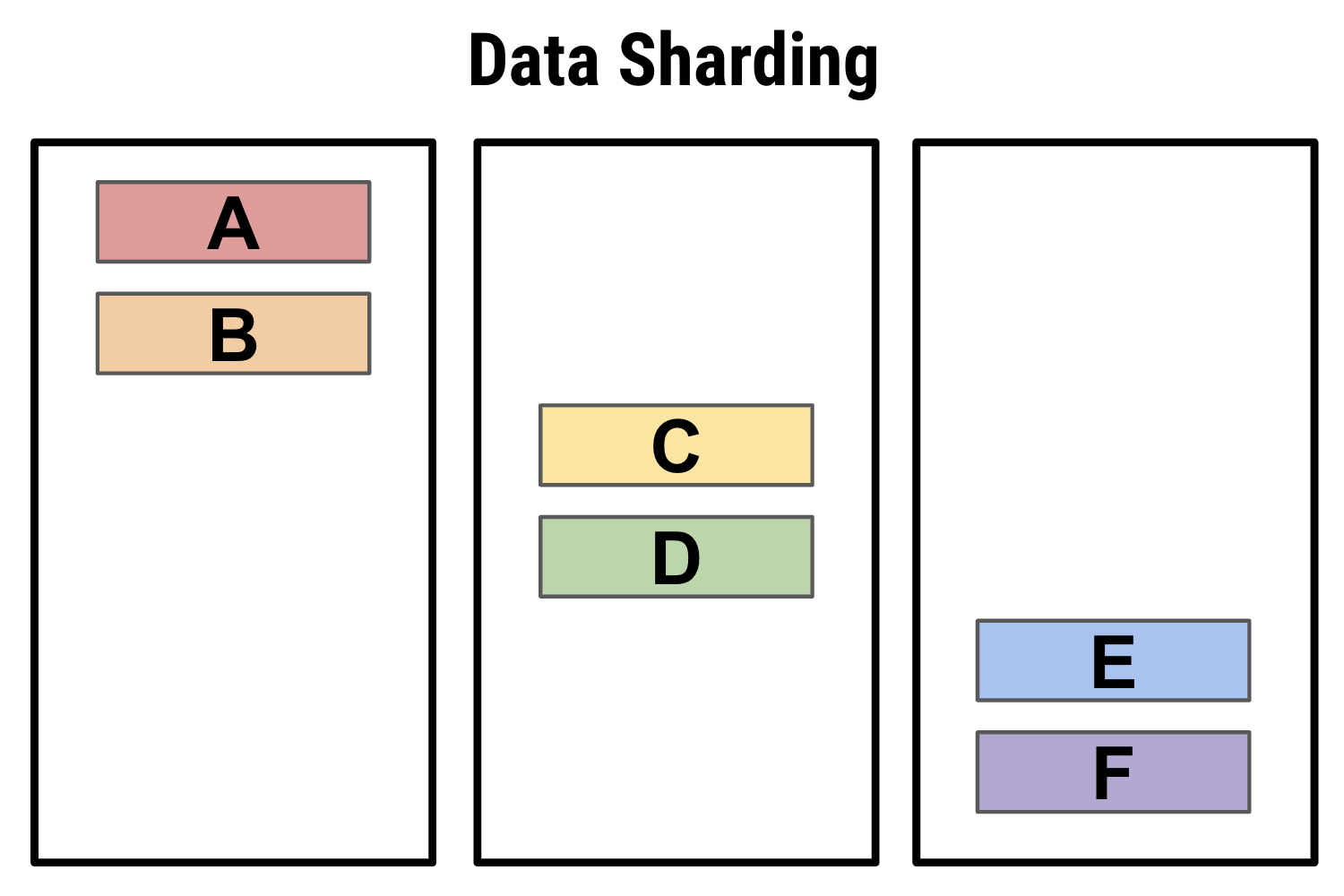 Example 1: Basic data sharding. Note that in this case, while data is sharded for load balancing across the different nodes, it does not provide high availability because none of the shards are replicated.
Example 1: Basic data sharding. Note that in this case, while data is sharded for load balancing across the different nodes, it does not provide high availability because none of the shards are replicated.
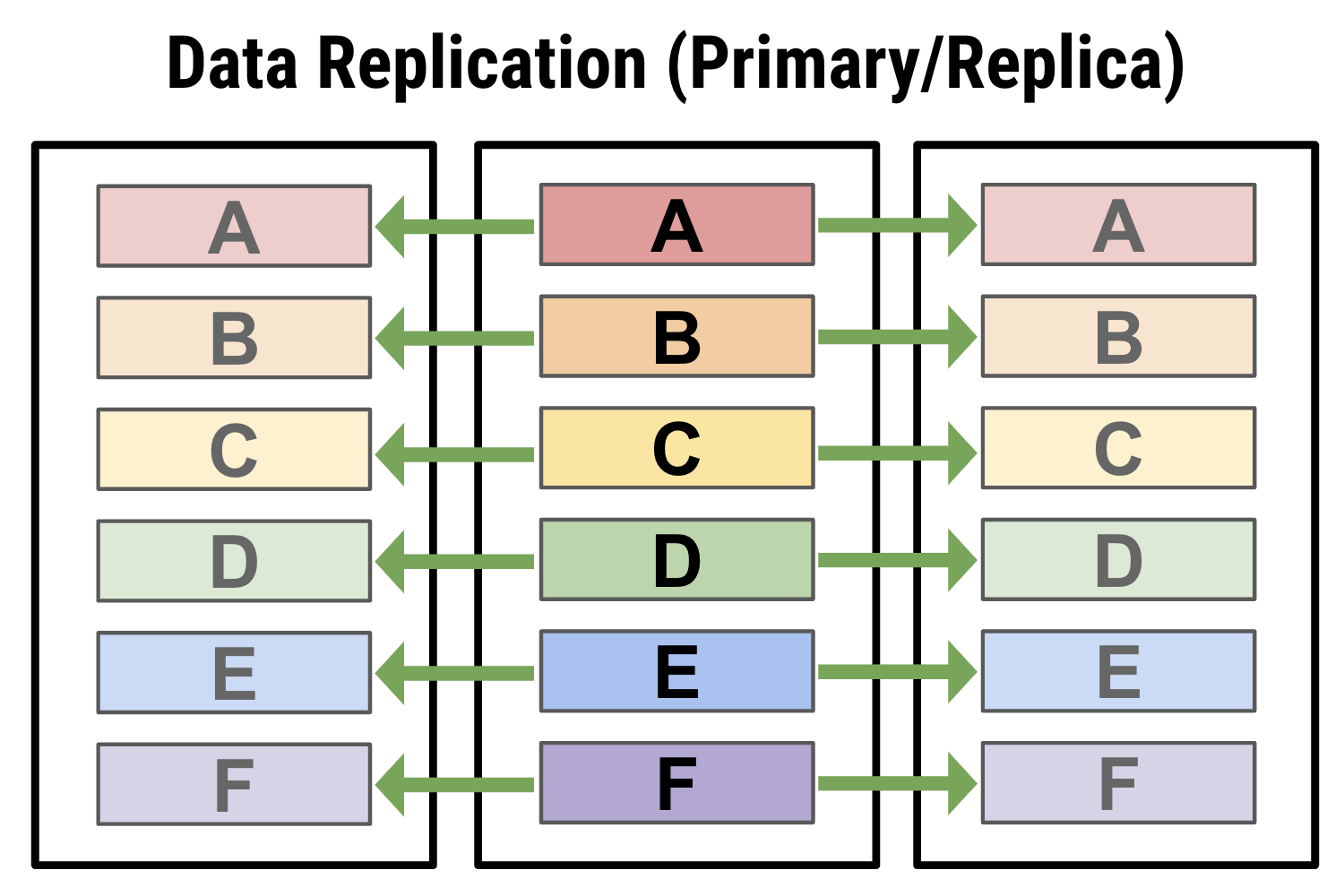
Example 2: A primary-replica method of data replication, where one node is used to write data, which then can be propagated out to other read-only nodes. This provides some levels of high availability, with a replica being able to take over the cluster in case the primary goes offline. However, it does not properly load balance your workload, because all writes have to be handled at the primary, so it may be impractical for write-heavy workloads.
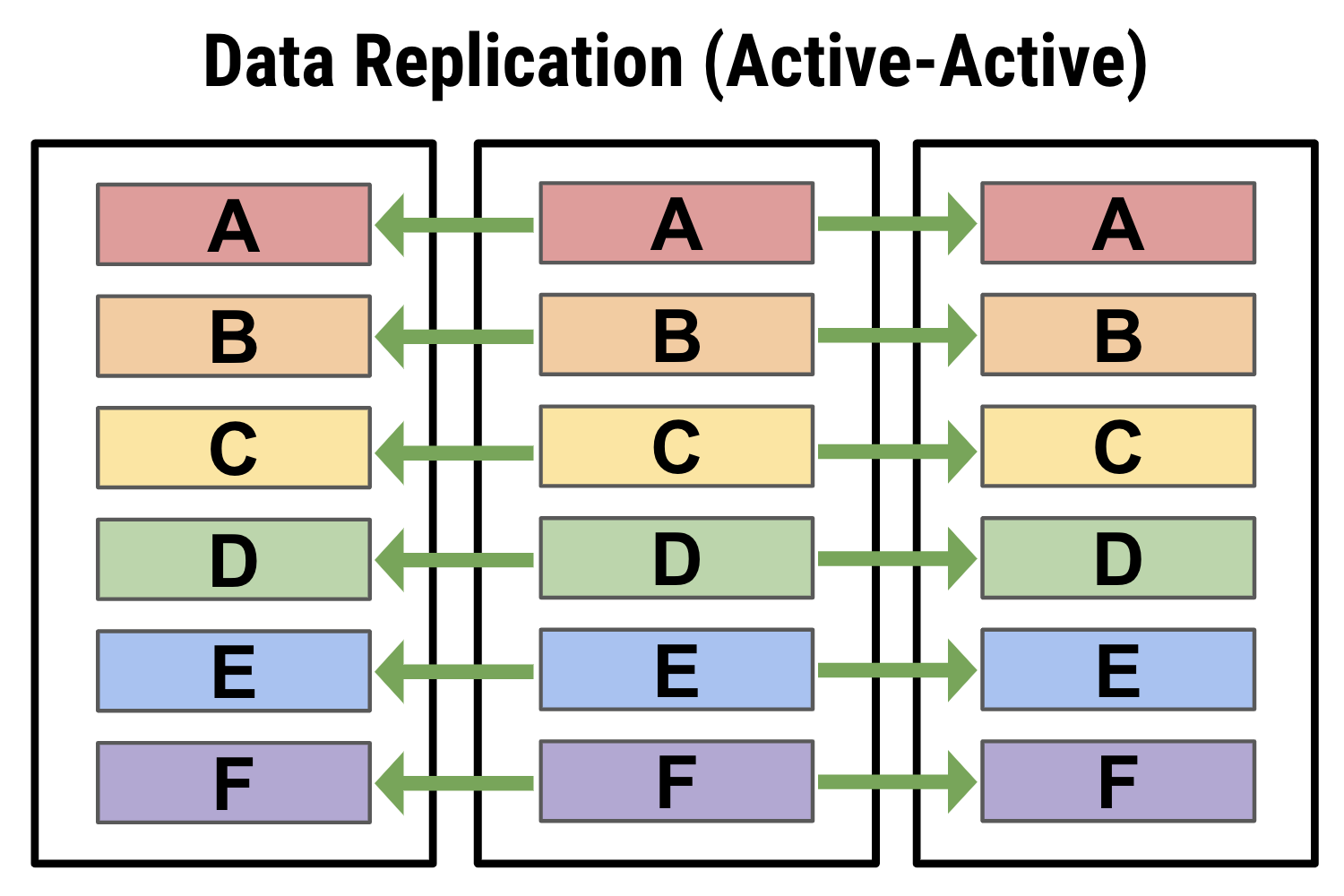
Example 3: Here, all data is sharded and replicated in an active-active leaderless topology. Every node can accept read and write operations, so all are peers in managing workload. As well, because of replication any loss to part of the cluster will not result in lost data.
Consistency Levels
Consistency levels determine how much you need each of those replicas to be in sync before you allow a read or write to complete. Let’s say that your data is replicated three ways, and you want to make sure that all three are fully in sync at all times. You want a fully transactional strong consistency guarantee. These are common in SQL RDBMS, where you use strong consistency with ACID guarantees.
That’s totally different than if you want to make sure that one node got an update and, trust him, he’ll tell two buddies about this update in the background. You can go on with your day. That is called eventual consistency. It means that the database can play more fast and loose with queries and, under certain conditions, you may find your data may become inconsistent.
You can even set it up so that each transaction can have its own tunable consistency, allowing you to tailor your consistency guarantees to your specific use case.
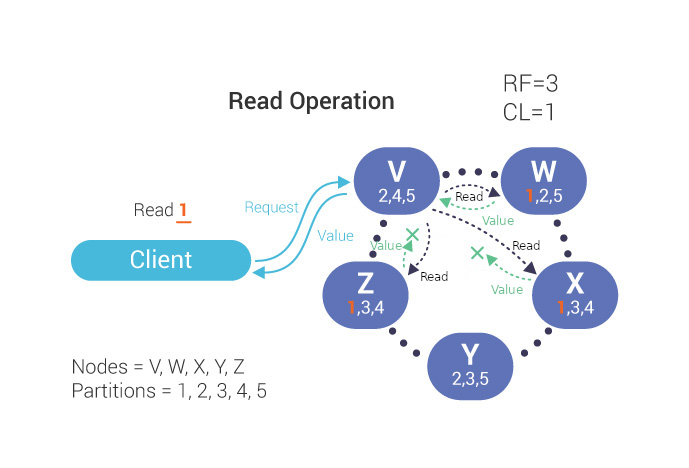
Example 4: In this example of ScyllaDB, you can have a replication factor of 3 (RF=3), but set a read operation with a consistency level of 1 (CL=1). That means that all you need to get is a response from the first node (W) where the data is stored for the client to be satisfied; it does not need to wait for all three replicas (W, X and Z) to report back. However, if you wanted to make sure that all three replicas had the same stored result, you could change your query to CL=3; this would allow you to discover potential data inconsistencies which can be fixed by running an anti-entropy repair operation.
Manual Sharding vs. Auto-Sharding
Next, for horizontal scalability, how does your system decide how to shard data across nodes? At first that was always a manual process, difficult and problematic to manage. So distributed databases implemented algorithms to automagically shard your data across your nodes. While that is far more prevalent these days, there’s still some distributed databases that haven’t solved for how, specifically, to auto-shard or make auto-sharding an advanced feature you don’t get out of the box.
Topology Awareness
Finally — and this is important for high availability — distributed databases need to understand their own physical deployments. Let’s say you have a local cluster, but it’s all on the same rack in the datacenter. Then, somehow, power is knocked out to it. Whoops! Your whole system is down.
So rack-awareness means that your database can try to make sure that each server in the cluster is on its own rack — or that, at least, they are spread around across the available racks as evenly as possible.
It’s the same with datacenter awareness across availability zones or regions. You want to make sure that no single datacenter disaster means you’ve lost part or all of your database.
Learn More About Distributed Databases
Now that we’ve set out a baseline to understand what a distributed database is, watch the full webinar (below) to see how this definition applies to various distributed databases, both popular SQL and NoSQL systems, and how they each implement these concepts.
I cover different database and database-adjacent technologies as well as describe their appropriate use cases, patterns, and antipatterns with a focus on:
- Distributed SQL, NewSQL, and NoSQL
- In-memory datastores and caches
- Streaming technologies with persistent data storage
Published at DZone with permission of Peter Corless. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments