When and Where to Rate-Limit: Strategies for Hybrid and Legacy Architectures
Learn how rate-limiting at the API gateway helps protect backend systems from traffic spikes, ensuring system stability and preserving revenue during surges.
Join the DZone community and get the full member experience.
Join For FreeToday, backend systems are constantly at risk of being overwhelmed by sudden surges in traffic. These spikes can be triggered by many factors — an influencer sharing a product link, a flash sale announcement, or even a glitch in upstream systems like a web layer or mobile application causing an unexpected flood of requests. Whether it’s an accidental bug or an external promotion, the result is the same: your backend systems must handle the demand or risk collapsing under the load.
How to Protect Your Backend from Traffic Surges
Many assume that auto-scaling and optimizing legacy systems to their maximum capacity will be enough to handle unexpected traffic surges. But the reality is that there are hard limits to what auto-scaling can achieve. Once your systems hit those limits — whether it's your microservices scaling horizontally or your legacy applications reaching their vertical capacity — you're left exposed. Without another layer of defense, the entire system can collapse, leading to a total failure that impacts 100% of your customers. At that point, no one can place an order, complete a payment, or even browse your platform.
This is why rate-limiting is essential. It acts as the final safeguard, ensuring that when traffic spikes, you can still protect your system by selectively throttling requests. Rather than allowing every customer to experience a crash, rate-limiting ensures that you continue serving the majority of users by sacrificing a smaller subset. In doing so, your system stays operational, and critical services remain available to keep revenue flowing.
How Rate-Limiting Minimizes Traffic Impact
In this article, we’ll explore:
- The critical decisions about where rate-limiting should be applied (API gateway, microservices, or legacy components).
- How to determine the extent of rate-limiting for different layers of your architecture.
- The tangible benefits of rate-limiting when implemented correctly, from reducing failure spread to optimizing system performance during traffic surges.
By the end of this discussion, you’ll understand how to use rate-limiting as a targeted defense mechanism to safeguard your backend systems from traffic overload — while continuing to serve the majority of your users and preserving critical business operations.
Understanding the Architectures and Third-Party Systems
Before making strategic decisions about where and how to apply rate-limiting, it’s important to first understand the architecture of your system and the third-party dependencies involved. Different architectures (hybrid, legacy, and microservices) each have their own strengths and weaknesses, influencing where rate-limiting is most effective.
Hybrid Architecture: A Mix of Microservices and Legacy Systems
In a hybrid architecture, modern microservices coexist with legacy systems, creating a complex environment where scalability and flexibility are uneven. Microservices allow horizontal scaling, while legacy systems are more rigid and rely on vertical scaling. The combination of these systems can lead to unique challenges when managing traffic spikes.
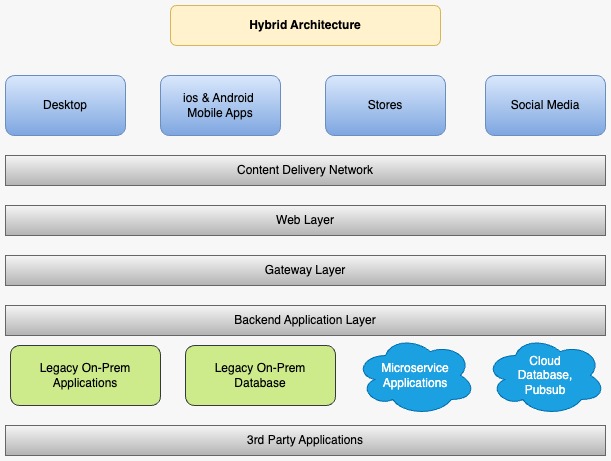
Key Characteristics
- Microservices: Scalable and designed to handle increases in traffic by adding more instances during demand surges.
- Legacy Systems: Limited to vertical scaling, meaning they can only handle so much before they reach their capacity limit.
Third-Party Systems
- External APIs: These include services like payment gateways, shipping providers, or tax calculation systems that both microservices and legacy systems may rely on.
- Social Media Shops: Platforms such as Instagram, TikTok, and Facebook Marketplace can drive huge, sudden traffic spikes that need to be managed.
Pure Legacy Architecture: Scaling Vertically With Limited Flexibility
In a fully legacy system, all components are tightly coupled and often built as part of a monolithic structure. These systems can only scale vertically, which means adding more resources to a single instance instead of spinning up new instances as you would with microservices. This makes legacy systems particularly vulnerable during traffic spikes, as there are hard limits on how much traffic they can handle.
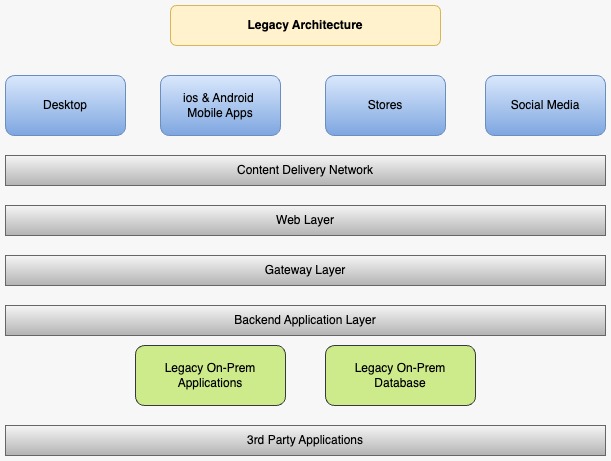
Key Characteristics
- Tight Coupling: A failure in one part of the system can quickly cascade through other components.
- Vertical Scalability: Legacy systems can only handle more traffic by adding more resources to a single instance, limiting overall capacity.
Third-Party Systems
- External Validators: Services such as address validation or tax calculation systems can become bottlenecks if they are overwhelmed by high traffic.
- Payment Services: Legacy systems often rely on external payment providers, which may struggle to keep up during high-demand periods.
Pure Microservices Architecture: Built for Scalability and Resilience
A fully microservices architecture is designed for resilience and horizontal scalability. Each service operates independently, allowing the system to add more instances as needed during peak traffic periods. However, even in a microservices setup, external dependencies and certain resource-heavy services may still need protection from overload.
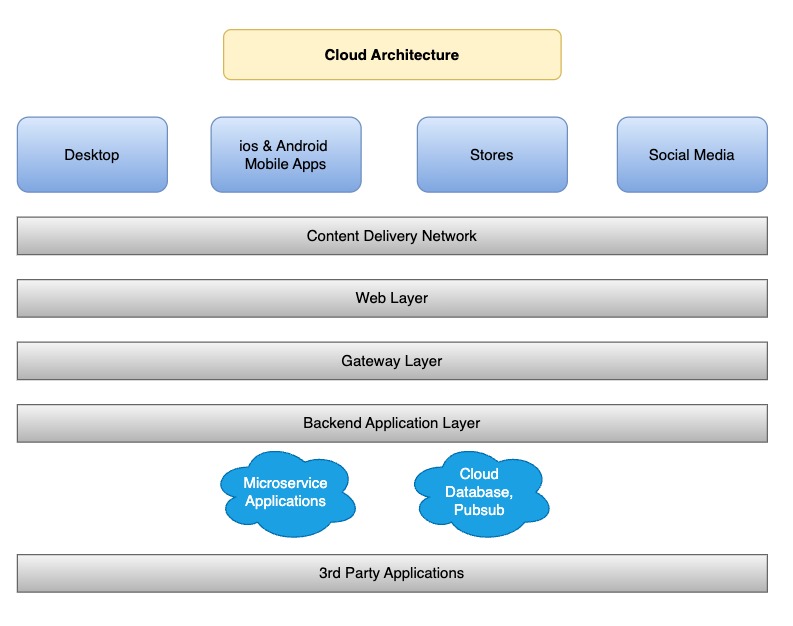
Key Characteristics
- Horizontal Scalability: Each microservice can scale independently, making the system more resilient to traffic spikes.
- Service Isolation: Failures in one service don’t necessarily affect others, but rate-limiting may still be needed for services with external dependencies.
Third-Party Systems
- External APIs: Microservices frequently rely on external services like payment gateways, shipping services, or address validators, which may not scale as efficiently as the microservices themselves.
- Cloud-Based Systems: Systems such as Pub/Sub or RabbitMQ are often used to communicate between microservices. These cloud-native components can help buffer high loads, but they, too, need protection against traffic overload.
Why Rate-Limiting Shouldn’t Be at the Application Layer
While rate-limiting is an essential tool for protecting your system from traffic overloads, applying it directly at the application layer — whether for microservices or legacy applications — is often a suboptimal strategy. Here’s why:
Microservices: The Scalability Mismatch
Microservices are designed to scale horizontally, meaning they can add more instances as demand increases. Applying rate-limiting at the microservice level directly contradicts this principle by artificially constraining the service’s ability to scale. Rate-limiting at this layer can unnecessarily introduce bottlenecks that force a service to reject requests, even when there is enough infrastructure to handle the load.
Additionally, microservices frequently depend on external services, like third-party APIs, which may impose their own rate limits. Adding rate-limiting at the service level only complicates the process and increases the chances of traffic being unnecessarily throttled, resulting in inconsistent user experiences.
Legacy Systems: The Fragility Factor
Legacy systems operate differently. They often rely on vertical scaling and have limited flexibility to handle increased loads. While it might seem logical to apply rate-limiting directly to protect fragile legacy systems, this approach usually falls short.
The main issue with rate-limiting at the legacy application layer is that it’s reactive. By the time rate-limiting kicks in, the system might already be overloaded. Legacy systems, lacking the scalability and elasticity of microservices, are more prone to total failure under high load, and rate-limiting at the application level can’t stop this once the traffic surge has already reached its peak.
Where Should Rate-Limiting Be Applied Instead?
Rate-limiting should be handled further upstream rather than deep in the application layer, where it either conflicts with scalability (in microservices) or arrives too late to prevent failures (in legacy systems).
This leads us to the API gateway, the strategic point in the architecture where traffic control is most effective. The API gateway acts as the entry point for all traffic, allowing you to throttle requests before they even reach the backend services, whether microservices or legacy applications.
Why the API Gateway Is the Right Place to Rate-Limit
The API gateway is the most strategic location for rate-limiting in any architecture. As the central point through which all traffic flows, the API gateway has visibility into incoming requests before they reach any downstream services, making it the ideal layer to apply rate-limiting.
Why the API Gateway Is Ideal for Rate-Limiting
The API gateway serves as the entry point to your entire system. By implementing rate-limiting here, you can control the flow of traffic before it reaches critical backend systems like microservices or legacy applications. This upstream approach allows for:
- Early Throttling: Requests can be filtered or rejected early, preventing a surge of traffic from overwhelming individual services.
- System-Wide Protection: Since all traffic passes through the API gateway, it acts as a single point where global rate-limiting policies can be enforced, providing protection across the entire architecture.
- Centralized Monitoring: Monitoring traffic and adjusting rate limits becomes much easier when it’s done at a single point in the system, providing full visibility into traffic patterns and system health.
Preventing Cascading Failures
Applying rate-limiting at the API gateway also helps to prevent cascading failures. If a service or component (like a legacy system or a third-party API) is struggling to handle load, the API gateway can start throttling requests before they hit the bottleneck, preventing a total system collapse.
Example:
In a hybrid architecture, the checkout system (a legacy component) may become overwhelmed during a flash sale. Instead of letting traffic flow unchecked to this bottleneck, the API gateway can apply rate-limiting to slow down the requests reaching this service, allowing it to handle what it can while preventing a total crash.
Tailored Rate-Limiting Policies
At the API gateway, you can create custom rate-limiting policies based on:
- User Segments: VIP users or paying customers can have higher rate limits than regular users, ensuring a smoother experience for your most valuable traffic.
- Services: Rate limits can be applied based on the specific service or resource being accessed, allowing you to fine-tune limits according to each component’s capacity.
This flexibility allows for better traffic management and prioritization, ensuring that critical actions (like payments or orders) aren’t throttled, while less critical requests (like browsing or search) can be slowed down if necessary.
Sacrificing a Subset of Traffic to Protect the Whole
The key to successfully handling traffic spikes is understanding that it’s often better to sacrifice a small portion of the traffic in a controlled way rather than risk a total system failure. By limiting the impact of sudden surges, your system can continue to serve the majority of users and keep critical services operational.
Why Sacrificing Some Traffic Is Better Than Total Failure
When faced with an unexpected traffic surge, trying to handle 100% of the requests can lead to your system becoming overwhelmed, resulting in a complete outage for all users. Instead of allowing every customer to experience a failure, rate-limiting allows you to selectively throttle or reject a smaller portion of the traffic, ensuring that your critical services remain available for most users.
By sacrificing a portion of the traffic in a controlled manner, your system stays operational, and you continue to generate revenue. This approach is particularly useful when high-value actions, such as completing orders or processing payments, take priority over less important actions like browsing or adding items to a wishlist.
Example:
During a flash sale, an e-commerce platform can prioritize traffic related to order completion and payment processing, while applying stricter rate-limits on product browsing or search queries. This ensures that while some customers may experience delays in browsing, the system remains functional, allowing the majority of transactions to go through and preserving revenue.
Preserving Revenue During Traffic Spikes
The ultimate goal of rate-limiting is not just to keep the system online but also to preserve revenue during periods of high demand. By intelligently throttling lower-priority traffic and protecting the key transactional flows, you ensure critical transactions are processed even when your system is under stress.
Rate-limiting at the API gateway allows you to prioritize high-revenue-generating actions (like payments and checkouts) over less critical actions, ensuring your system doesn’t lose out on potential sales even when traffic spikes.
Controlling the Blast Radius of Failure
Rate-limiting also helps control the blast radius of failures. Without rate-limiting, a bottleneck in one part of your system (e.g., an overwhelmed legacy component) could cause a cascading failure that affects the entire platform. By applying rate-limiting at the gateway, you can isolate the failure to a smaller subset of traffic, ensuring that only a portion of users are affected rather than the entire system going down.
Conclusion
The key to handling traffic surges isn’t attempting to serve 100% of users — it’s about strategically sacrificing a subset of traffic to preserve critical services and continue generating revenue. By applying rate-limiting at the API gateway, monitoring traffic patterns, and adjusting limits dynamically, your system can withstand extreme loads without compromising your most valuable transactions.
Opinions expressed by DZone contributors are their own.
Comments