Why the Newest LLMs Use a MoE (Mixture of Experts) Architecture
Learn about the Mixture of Experts (MoE) architecture, defined as a mix or blend of different "expert" models working together to complete a specific problem.
Join the DZone community and get the full member experience.
Join For FreeSpecialization Made Necessary
A hospital is overcrowded with experts and doctors each with their own specializations, solving unique problems. Surgeons, cardiologists, pediatricians — experts of all kinds join hands to provide care, often collaborating to get the patients the care they need. We can do the same with AI.
Mixture of Experts (MoE) architecture in artificial intelligence is defined as a mix or blend of different "expert" models working together to deal with or respond to complex data inputs. When it comes to AI, every expert in an MoE model specializes in a much larger problem — just like every doctor specializes in their medical field. This improves efficiency and increases system efficacy and accuracy.
Mistral AI delivers open-source foundational LLMs that rival that of OpenAI. They have formally discussed the use of an MoE architecture in their Mixtral 8x7B model, a revolutionary breakthrough in the form of a cutting-edge Large Language Model (LLM). We’ll deep dive into why Mixtral by Mistral AI stands out among other foundational LLMs and why current LLMs now employ the MoE architecture highlighting its speed, size, and accuracy.
Common Ways to Upgrade Large Language Models (LLMs)
To better understand how the MoE architecture enhances our LLMs, let’s discuss common methods for improving LLM efficiency. AI practitioners and developers enhance models by increasing parameters, adjusting the architecture, or fine-tuning.
- Increasing parameters: By feeding more information and interpreting it, the model's capacity to learn and represent complex patterns increases. However, this can lead to overfitting and hallucinations, necessitating extensive Reinforcement Learning from Human Feedback (RLHF).
- Tweaking architecture: Introducing new layers or modules accommodates the increasing parameter counts and improves performance on specific tasks. However, changes to the underlying architecture are challenging to implement.
- Fine-tuning: Pre-trained models can be fine-tuned on specific data or through transfer learning, allowing existing LLMs to handle new tasks or domains without starting from scratch. This is the easiest method and doesn’t require significant changes to the model.
What Is the MoE Architecture?
The Mixture of Experts (MoE) architecture is a neural network design that improves efficiency and performance by dynamically activating a subset of specialized networks, called experts, for each input. A gating network determines which experts to activate, leading to sparse activation and reduced computational cost. MoE architecture consists of two critical components: the gating network and the experts. Let's break that down:
At its heart, the MoE architecture functions like an efficient traffic system, directing each vehicle – or in this case, data – to the best route based on real-time conditions and the desired destination. Each task is routed to the most suitable expert, or sub-model, specialized in handling that particular task. This dynamic routing ensures that the most capable resources are employed for each task, enhancing the overall efficiency and effectiveness of the model. The MoE architecture takes advantage of all 3 ways how to improve a model’s fidelity.
- By implementing multiple experts, MoE inherently increases the model's parameter size by adding more parameters per expert.
- MoE changes the classic neural network architecture which incorporates a gated network to determine which experts to employ for a designated task.
- Every AI model has some degree of fine-tuning, thus every expert in an MoE is fine-tuned to perform as intended for an added layer of tuning traditional models could not take advantage of.
MoE Gating Network
The gating network acts as the decision-maker or controller within the MoE model. It evaluates incoming tasks and determines which expert is suited to handle them. This decision is typically based on learned weights, which are adjusted over time through training, further improving its ability to match tasks with experts. The gating network can employ various strategies, from probabilistic methods where soft assignments are tasked to multiple experts, to deterministic methods that route each task to a single expert.
MoE Experts
Each expert in the MoE model represents a smaller neural network, machine learning model, or LLM optimized for a specific subset of the problem domain. For example, in Mistral, different experts might specialize in understanding certain languages, dialects, or even types of queries. The specialization ensures each expert is proficient in its niche, which, when combined with the contributions of other experts, will lead to superior performance across a wide array of tasks.
MoE Loss Function
Although not considered a main component of the MoE architecture, the loss function plays a pivotal role in the future performance of the model, as it’s designed to optimize both the individual experts and the gating network.
It typically combines the losses computed for each expert which are weighted by the probability or significance assigned to them by the gating network. This helps to fine-tune the experts for their specific tasks while adjusting the gating network to improve routing accuracy.
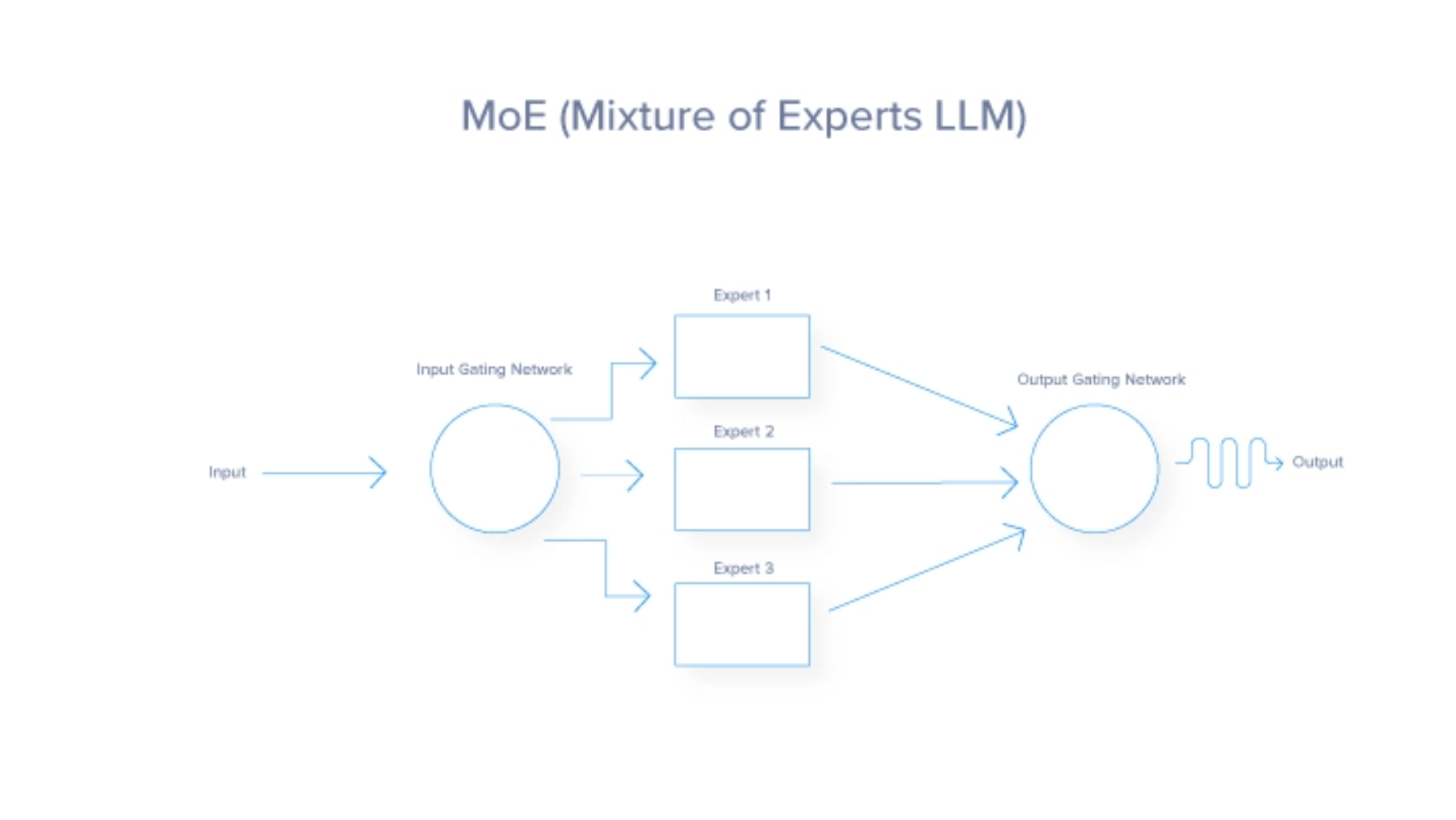
The MoE Process Start to Finish
Now let’s sum up the entire process, adding more details.
Here's a summarized explanation of how the routing process works from start to finish:
- Input processing: Initial handling of incoming data; mainly our prompt in the case of LLMs
- Feature extraction: Transforming raw input for analysis
- Gating network evaluation: Assessing expert suitability via probabilities or weights
- Weighted routing: Allocating input based on computed weights; Here, the process of choosing the most suitable LLM is completed. In some cases, multiple LLMs are chosen to answer a single input.
- Task execution: Processing allocated input by each expert
- Integration of expert outputs: Combining individual expert results for final output
- Feedback and adaptation: Using performance feedback to improve models
- Iterative optimization: Continuous refinement of routing and model parameters
Popular Models that Utilize an MoE Architecture
OpenAI’s GPT-4 and GPT-4o
GPT-4 and GPT4o power the premium version of ChatGPT. These multi-modal models utilize MoE to be able to ingest different source mediums like images, text, and voice. It is rumored and slightly confirmed that GPT-4 has 8 experts each with 220 billion paramters totalling the entire model to over 1.7 trillion parameters.
Mistral AI’s Mixtral 8x7b
Mistral AI delivers very strong AI models open source and has said their Mixtral model is an sMoE model or sparse Mixture of Experts model delivered in a small package. Mixtral 8x7b has a total of 46.7 billion parameters but only uses 12.9B parameters per token, thus processing inputs and outputs at that cost. Their MoE model consistently outperforms Llama2 (70B) and GPT-3.5 (175B) while costing less to run.
The Benefits of MoE and Why It's the Preferred Architecture
Ultimately, the main goal of MoE architecture is to present a paradigm shift in how complex machine learning tasks are approached. It offers unique benefits and demonstrates its superiority over traditional models in several ways.
Enhanced Model Scalability
- Each expert is responsible for a part of a task, therefore scaling by adding experts won't incur a proportional increase in computational demands.
- This modular approach can handle larger and more diverse datasets and facilitates parallel processing, speeding up operations. For instance, adding an image recognition model to a text-based model can integrate an additional LLM expert for interpreting pictures while still being able to output text. Or
- Versatility allows the model to expand its capabilities across different types of data inputs.
Improved Efficiency and Flexibility
- MoE models are extremely efficient, selectively engaging only necessary experts for specific inputs, unlike conventional architectures that use all their parameters regardless.
- The architecture reduces the computational load per inference, allowing the model to adapt to varying data types and specialized tasks.
Specialization and Accuracy
- Each expert in an MoE system can be finely tuned to specific aspects of the overall problem, leading to greater expertise and accuracy in those areas
- Specialization like this is helpful in fields like medical imaging or financial forecasting, where precision is key.
- MoE can generate better results from narrow domains due to its nuanced understanding, detailed knowledge, and the ability to outperform generalist models on specialized tasks.
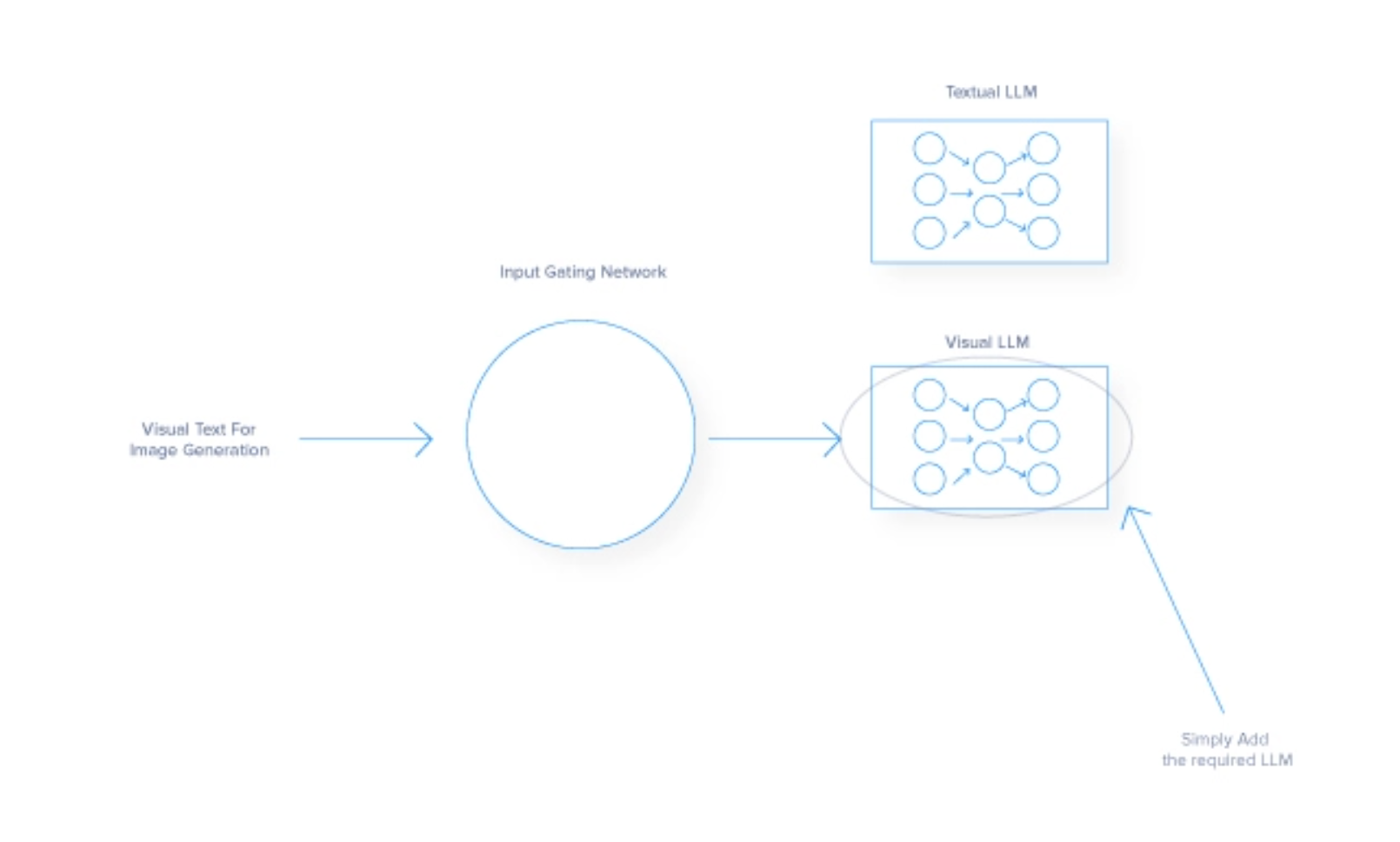
The Downsides of The MoE Architecture
While MoE architecture offers significant advantages, it also comes with challenges that can impact its adoption and effectiveness.
- Model complexity: Managing multiple neural network experts and a gating network for directing traffic makes MoE development and operational costs challenging.
- Training stability: Interaction between the gating network and the experts introduces unpredictable dynamics that hinder achieving uniform learning rates and require extensive hyperparameter tuning.
- Imbalance: Leaving experts idle is poor optimization for the MoE model, spending resources on experts that are not in use or relying on certain experts too much. Balancing the workload distribution and tuning an effective gate is crucial for a high-performing MoE AI.
It should be noted that the above drawbacks usually diminish over time as MoE architecture is improved.
The Future Shaped by Specialization
Reflecting on the MoE approach and its human parallel, we see that just as specialized teams achieve more than a generalized workforce, specialized models outperform their monolithic counterparts in AI models. Prioritizing diversity and expertise turns the complexity of large-scale problems into manageable segments that experts can tackle effectively.
As we look to the future, consider the broader implications of specialized systems in advancing other technologies. The principles of MoE could influence developments in sectors like healthcare, finance, and autonomous systems, promoting more efficient and accurate solutions.
The journey of MoE is just beginning, and its continued evolution promises to drive further innovation in AI and beyond. As high-performance hardware continues to advance, this mixture of expert AIs can reside in our smartphones, capable of delivering even smarter experiences. But first, someone's going to need to train one.
Published at DZone with permission of Kevin Vu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments