Beyond REST: Architecting High-Density Agentic Microservices With MCP and WASI-NN
REST APIs waste tokens. UMA uses MCP to bridge agents to local Wasm/WASI-NN, slashing costs and latency by replacing raw data with deterministic, executable intent.
Join the DZone community and get the full member experience.
Join For FreeThe bill for the generative AI integration rush has arrived, and it is denominated in egress costs, token bloat, and idle container memory.
For the past two years, engineering teams integrated LLMs via the path of least resistance: layering models on top of existing architectures. For human-facing use cases, this works. Humans provide implicit context, tolerate minor latency, and intuitively course-correct errors.
Agents behave differently. They execute tightly coupled orchestration loops where step $N$ strictly depends on the evaluated context of step $N-1$. When an agent triggers a chain of API calls, interprets the JSON responses, and feeds those results back into its reasoning engine, the system stops behaving like a traditional request-response architecture. It becomes a distributed, fragile reasoning engine.
The underlying infrastructure was never designed for this. Maintaining Run The Engine (RTE) metrics becomes impossible when your orchestrator times out waiting for 15 sequential REST calls to resolve over a network.
Where REST Breaks Under Agent Workloads
REST architectures assume a deterministic client that parses data efficiently. Agents violate this assumption.
Consider a supply chain endpoint returning a raw inventory array. An agent receiving this must compute available stock, estimate depletion rates, and evaluate business constraints. While these tasks are trivial, executing them inside an LLM inference cycle introduces three structural failures:
- Latency amplification: There is no caching at the reasoning level. The LLM re-evaluates the same arithmetic on every invocation.
- The token tax: The model must ingest massive, unrefined data structures rather than a concise summary, burning context windows and budget.
- Probabilistic drift: Arithmetic and threshold evaluations become non-deterministic. A slight prompt change might cause the agent to miscalculate a threshold that a compiled binary would hit with 100% accuracy.
When this pattern repeats, system latency is no longer a function of API performance; it is bottlenecked by the entire reasoning chain.
The Shift: From Data Endpoints to Capability Execution
To break this bottleneck, we must move from data retrieval to capability execution. Instead of returning raw arrays, microservices must return deterministic decisions.
This requires pushing computation to the edge. In a capability-driven model, the agent does not fetch inventory and calculate risk; it invokes a localized capability that already encapsulates that math.
The Execution Engine: MCP Paired With WASI-NN
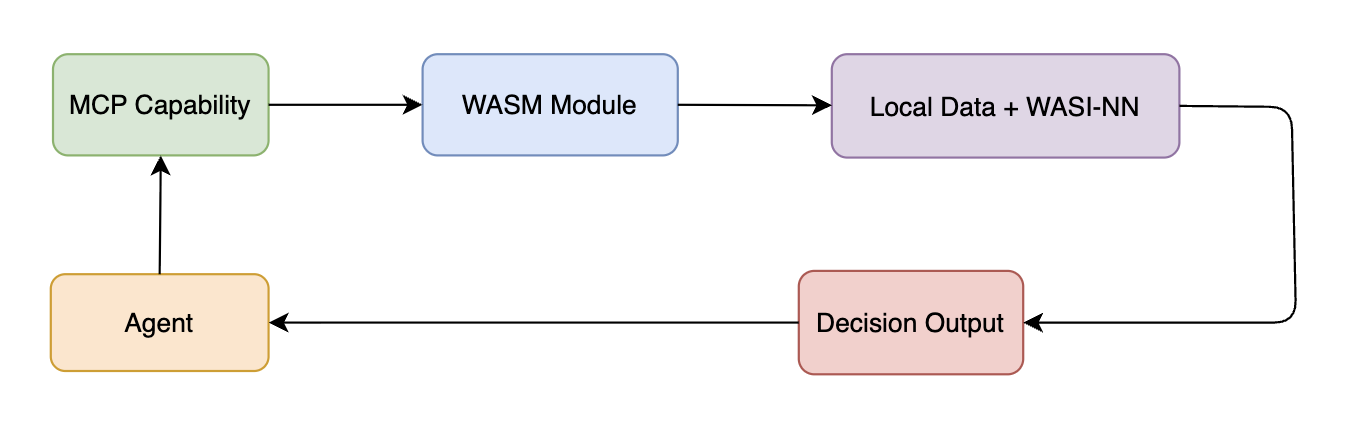
The Model Context Protocol (MCP) provides the discovery layer. Unlike Swagger, which requires an agent to guess routing patterns, MCP enforces a consistent interaction contract that aligns with how agents operate.
WebAssembly (Wasm) provides the runtime. Instead of 500MB Docker containers, logic is compiled into lightweight modules that execute in-process on the same node as the orchestrator. This eliminates the network boundary entirely.
By utilizing WASI-NN (WebAssembly System Interface for Neural Networks), these modules can run localized, small-parameter ML models (e.g., Phi-4-Mini) using the host’s native hardware. This enables sophisticated inference without hitting external model APIs.
The Evidence: Wasm vs. Docker Unit Economics
Transitioning from containerized services to Wasm modules fundamentally changes execution characteristics.
| operational metric | legacy pattern (python/REST) | capability pattern (WASM/MCP) |
|---|---|---|
| Cold Start Latency | 350ms - 800ms | < 6ms |
| Memory Footprint | 300MB - 500MB | ~5MB |
| Network Hops | 1 per tool call | 0 (Local execution) |
| Contextual Overhead | ~600 tokens | ~40 tokens |
The difference comes from eliminating layers:
- No guest OS boot
- No interpreter startup
- No network boundary
Wasm modules are precompiled bytecode. The runtime simply instantiates them. Model weights are loaded once and reused, allowing thousands of executions to share the same memory.
Implementation: A Context-Aware Capability
The difference here is the boundary of responsibility. The Rust example below demonstrates a capability that retrieves data, executes a localized model, and returns a decision-ready assessment.
// Dependencies: mcp-sdk = "1.x", wasi-nn = "0.x"
use mcp_sdk::server::{McpServer, Tool};
use wasi_nn::{self, GraphEncoding, ExecutionTarget, TensorType};
#[mcp_tool]
async fn evaluate_supply_risk(sku: String, buffer_days: u32) -> Result<String, anyhow::Error> {
// 1. Native data retrieval (bypassing HTTP overhead)
let stock_level: u32 = host_bindings::kv_store::get(&sku).await?;
// 2. Localized reasoning via WASI-NN
let graph = wasi_nn::load(
&[include_bytes!("../models/supply_risk_q4.tflite")],
GraphEncoding::TensorflowLite,
ExecutionTarget::CPU
)?;
let mut context = wasi_nn::init_execution_context(graph)?;
let input_tensor = [stock_level as f32, buffer_days as f32];
wasi_nn::set_input(context, 0, TensorType::F32, &[1, 2], &input_tensor)?;
wasi_nn::compute(context)?;
let mut output = [0f32; 1];
wasi_nn::get_output(context, 0, &mut output)?;
// 3. Return Semantic Context, avoiding raw data dumps
Ok(format!(
"SKU {} stock: {}. Analysis: {:.1}% risk of stockout within {} days. Action: Route to secondary.",
sku, stock_level, output[0] * 100.0, buffer_days
))
}
fn main() {
let server = McpServer::new("supply-chain-node")
.add_tool(evaluate_supply_risk)
.build();
server.start_stdio();
}The Architectural Hazard: Semantic Drift
When multiple Wasm capabilities independently encode similar logic, definitions diverge. If a Fraud_Service defines "High Risk" as $>0.8$ while a Payment_Gateway defines it as $>0.6$, the agent will experience logic oscillation, repeatedly looping as it receives contradictory context.
Enforcing Consistency via TypeSpec
We mitigate this by enforcing data invariants at compile-time using TypeSpec. This acts as a central ontology for the system.
@service({ title: "Logistics Context Ontology" })
namespace LogisticsDomain {
@doc("Normalized probability of supply chain failure.")
scalar RiskScore extends float32;
model ContextualRiskAssessment {
sku: string;
@minValue(0) current_stock: int32;
@minValue(0.0) @maxValue(1.0) stockout_probability: RiskScore;
recommended_action: "RouteSecondary" | "Hold" | "Expedite";
}
}This acts as a compile-time guardrail. Any deviation fails during build, ensuring all capabilities operate within the same semantic model.
Where This Architecture Fits
This model works best for:
- high-frequency decision loops
- stateless computations
- bounded inference tasks
It is not suited for:
- large model hosting
- long-running workflows
- complex orchestration logic
Trying to force those into WASM introduces more complexity than benefit.
Final Thoughts: Evolving the Control Plane
This shift is not about replacing REST entirely. It is about recognizing that agents are not traditional consumers. They do not need access to raw systems. They need bounded, deterministic outcomes.
As agent workloads scale, pushing reasoning closer to the data becomes less of an optimization and more of an operational requirement.
When comparing a 5MB Wasm module executing in milliseconds to a 500MB container spinning up over the network, the trade-offs become difficult to ignore, especially in high-frequency agent workflows.
The next phase of backend evolution is not building better APIs. It is building systems that expose executable intent.
Opinions expressed by DZone contributors are their own.
Comments