Beyond Sharper Images: How LLM-Guided Super-Resolution Transforms Geo-Spatial Analysis
LLM-guided SR approach converts natural-language intent into controllable SR settings, producing outputs optimized for mapping, agriculture, and disaster response.
Join the DZone community and get the full member experience.
Join For FreeThe shift from generic image enhancement to intelligent, task-sensitive processing of satellite imagery represents a major methodological change in geospatial analysis. High-resolution satellite images form a core data source in modern urban planning, precision agriculture, and disaster resilience strategies. However, despite cumulative advances in super-resolution (SR) approaches, the fundamental analytical needs of most spatial science systems remain unmet.
Traditional SR methods are designed to enhance visual appeal, but geospatial analysts require images that support specific tasks. For example, a building segmentation model requires precise building edges — not merely a sharper image. Similarly, a crop monitoring system depends on accurate spectral information, not photorealistic textures, to calculate reliable vegetation indices.
To address this gap, our research laboratory developed an LLM-directed super-resolution architecture that uses natural language descriptions to guide image enhancement toward discrete analytical objectives. Instead of generic upsampling, analysts can specify requirements such as “Enhance building outlines for urban mapping” or “Preserve crop structure for NDVI analysis.”
The Core Problem: When More Pixels Don’t Mean More Insight
The Sensor Trade-Off Triangle
Satellite imaging involves a fundamental trade-off between spatial resolution, temporal frequency, and cost. This constraint means that much of the available imagery — both archival and near real-time — lacks the resolution required for detailed analysis. Important features such as narrow irrigation channels, individual crop rows, or small building footprints often fall below the sensor’s effective resolution limit.
The Perceptual Quality Trap
Standard super-resolution (SR) algorithms optimize perceptual metrics such as Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM). While these metrics correlate with human visual preference, they do not guarantee analytical usefulness. We encountered several real-world failures:
- An SR model smoothed building edges for visual appeal, reducing building footprint extraction accuracy from 78% to 65%.
- Enhanced agricultural imagery with realistic-looking textures lowered NDVI correlation from 0.89 to 0.73.
- Road networks appeared sharper but contained artifacts that confused transportation mapping algorithms.
The One-Size-Fits-None Challenge
Generic SR models apply the same enhancement strategy across geographically diverse areas — for example, congested streets in Singapore, rainforest canopies in Brazil, or coastal wetlands in India. Each environment has unique visual characteristics and analytical requirements, demanding task-specific processing strategies.
Our Solution: Natural Language as the Enhancement Guide
The key insight behind our framework is simple: domain experts know exactly which features matter for their specific tasks. By allowing them to express this knowledge in natural language, we can generate SR outputs that are not only higher in resolution but also analytically superior.
Architecture Overview
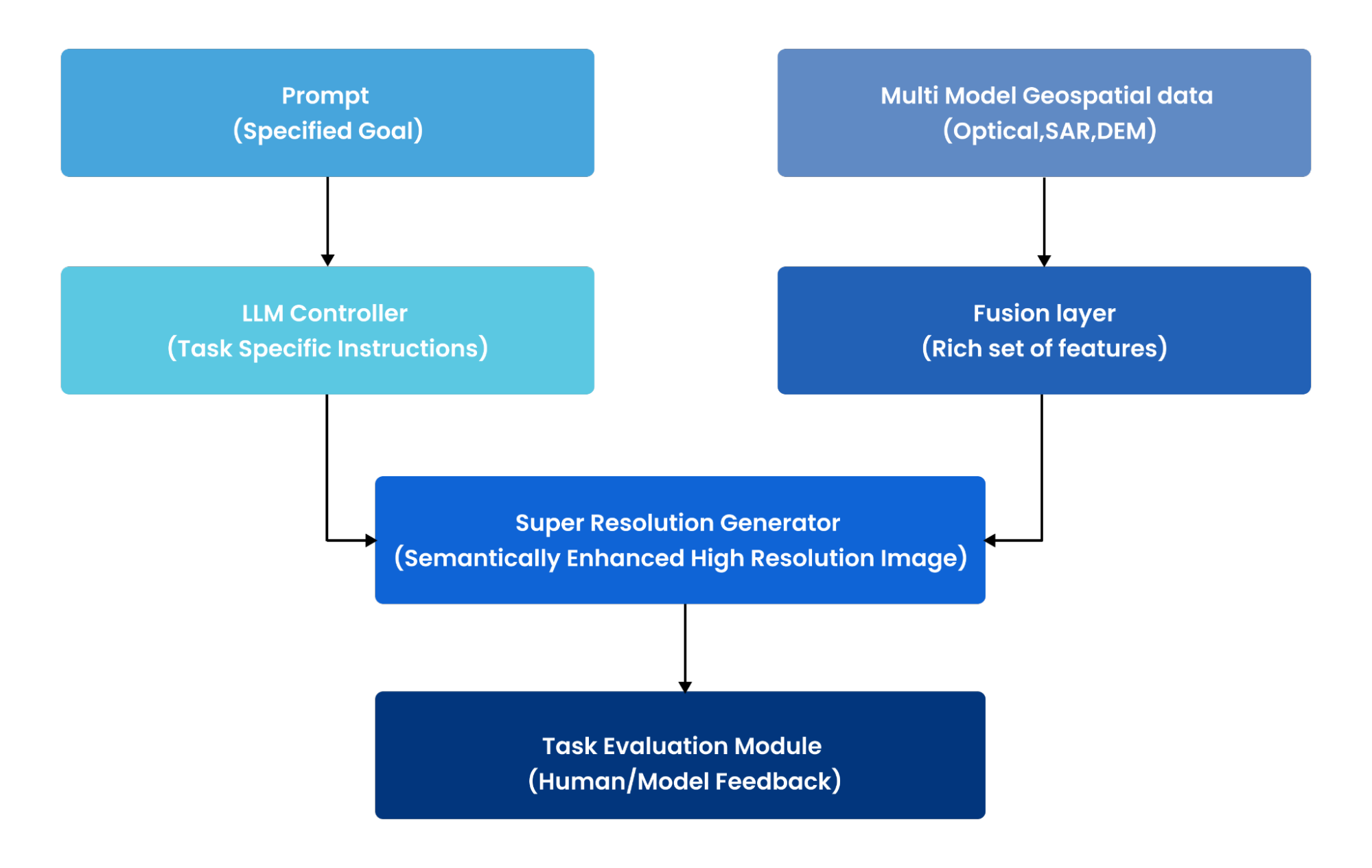
Our system consists of four components:
- Input Layer: Accepts low-resolution satellite imagery (optical, SAR, or multispectral) along with natural language prompts describing the analytical objective.
- LLM Controller: A multimodal large language model that interprets the prompt and translates high-level intent into technical configuration parameters.
- Conditional SR Generator: A diffusion-based model that performs super-resolution while following guidance derived from the LLM output.
- Task Evaluation Module: Evaluates results using both traditional image quality metrics and task-specific performance measures.
The LLM as Enhancement Orchestrator
Our LLM controller is built on the Llama-3 architecture. It serves as an intelligent bridge between human intent and machine execution. When given a prompt such as:
“Enhance road centerlines and building edges for cartographic updates,”
it generates a structured JSON configuration detailing:
- Loss function weights prioritizing edge preservation over texture generation
- Attention mask parameters focusing on linear and geometric features
- Data augmentation strategies to prevent overfitting to specific urban layouts
- Hyperparameter adjustments balancing detail enhancement and noise reduction
This approach transforms the traditionally opaque SR process into one that is transparent and controllable.
Technical Deep Dive
Data Pipeline and Preprocessing
Our system relies on a carefully curated dataset that includes:
- Public sources: Sentinel-1 (SAR) and Sentinel-2 (multispectral) imagery for global coverage
- Commercial data: High-resolution WorldView and Planet imagery for ground truth
- Auxiliary data: Digital Elevation Models, land-use classifications, and temporal image series
Our standardized preprocessing pipeline ensures consistent results across diverse geographic regions.
# Simplified preprocessing workflow
def preprocess_imagery(image_path, target_resolution=10):
# Georeferencing to common coordinate system (WGS84/UTM)
image = reproject_image(image_path, target_crs=’EPSG:4326′)
# Atmospheric and radiometric corrections
corrected = apply_atmospheric_correction(image)
# Cloud masking and quality filtering
masked = apply_cloud_mask(corrected, cloud_threshold=0.1)
# Extract aligned patch pairs for training
patches = extract_patch_pairs(masked, patch_size=512)
return patchesHybrid Loss Function Strategy
Traditional SR models rely on simple pixel-wise losses. Our task-aware approach requires a more sophisticated objective function combining:
- Pixel Fidelity: L1/L2 loss for baseline image quality
- Perceptual Quality: VGG-based perceptual loss for visual coherence
- Task-Specific Loss: Dynamically weighted based on analytical objectives
For urban mapping, we emphasize edge preservation:
edge_loss = sobel_edge_loss(enhanced_image, ground_truth)
total_loss = 0.3 * l1_loss + 0.3 * perceptual_loss + 0.4 *
edge_loss
For vegetation analysis, we prioritize spectral consistency:
ndvi_loss = ndvi_consistency_loss(enhanced_image, ground_truth)
total_loss = 0.4 * l1_loss + 0.2 * perceptual_loss + 0.4 *
ndvi_lossConditional Diffusion Architecture
Our SR generator uses conditional diffusion models capable of generating realistic high-frequency details while maintaining control. The model conditions on:
- Low-resolution visual input
- Task embedding derived from the LLM interpretation
- Auxiliary data such as DEMs, land cover maps, or temporal context
The diffusion process iteratively refines noise into high-resolution imagery, guided at each step by task-specific conditioning signals.
Real-World Validation
Urban Infrastructure Mapping
Challenge: Updating the city maps from 30m resolution Landsat imagery to support 5m precision requirements for infrastructure planning.
Prompt: “Enhance road centerlines and building edges for cartographic updates.”
Results:
- Road segmentation IoU improved from 0.63 to 0.78.
- Building footprint accuracy increased from 72% to 85%.
- Processing time: 15 seconds per 1024×1024 tile on NVIDIA A10G.
Impact: Enabled automated map updates for a 500 sq km metropolitan area, reducing manual digitization time from 3 weeks to 2 days.
Precision Agriculture Monitoring
Challenge: Assessing crop health from 10m Sentinel-2 imagery with sufficient detail to guide variable-rate fertilizer application.
Prompt: “Preserve crop row structure and maintain spectral integrity for NDVI analysis”
Results:
- NDVI correlation with ground truth improved from 0.82 to 0.91.
- Crop row detection accuracy increased from 68% to 81%.
- False positive rate for stress detection reduced by 23%.
Impact: Optimized fertilizer application across 10,000 hectares, reducing input costs by 18% while maintaining yield levels.
Disaster Response Coordination
Challenge: Rapid flood extent mapping from SAR imagery for emergency response planning.
Prompt: “Enhance water boundaries and preserve flood extent accuracy for disaster mapping”
Results:
- Flood boundary delineation accuracy improved from 0.74 to 0.88 IoU.
- False alarm rate reduced from 12% to 6%.
- Processing latency: Under 30 seconds for 100 sq km coverage.
Impact: Provided actionable flood maps within 2 hours of satellite overpass, enabling timely evacuation decisions for affected communities.
Production Deployment: Scaling Intelligence
Infrastructure Requirements
Development: A Single NVIDIA RTX 3090 is sufficient for prototyping and small-scale experiments.
Training: Multi-GPU cluster (4-8 NVIDIA A100s) is required for diffusion model training on large datasets.
Production Inference: NVIDIA A10G or L4 clusters provide optimal price-performance for real-time processing.
Operational Considerations
Our deployment leverages containerized microservices for scalability and reliability:
- API Layer: FastAPI handles request routing and response formatting
- Model Serving: TorchServe manages the model lifecycle and GPU resource allocation
- Orchestration: Kubernetes enables auto-scaling based on demand
- Monitoring: Custom metrics track both system performance and task-specific accuracy
A typical production deployment processes 1,000+ image tiles per hour while maintaining sub-minute response times for interactive use cases.
Technology Stack
This technology stack uses the latest open-source tools and frameworks to make AI-driven workflows easier, from model orchestration and training to geospatial analysis, computer vision tasks, and scalable deployment.
| Component | Technology | Purpose |
|---|---|---|
| LLM Orchestration | LangChain, Hugging Face Transformers | Prompt processing and model coordination |
| Deep Learning | PyTorch, diffusers, timm | Model training and inference |
| Geospatial Processing | GDAL, Rasterio, Shapely, Fiona | Imagery handling and geographic operations |
| Computer Vision | Kornia, MONAI | Image transformations and medical imaging utilities |
| Deployment | FastAPI, TorchServe, Docker, Kubernetes | Production serving and orchestration |
Challenges and Future
Current Limitations
- Synthetic Data Dependency: Training on paired low/high resolution imagery can create domain gaps when applied to real-world data with different characteristics.
- LLM Hallucinations: The LLM controller occasionally generates configurations that sound plausible but perform poorly, requiring human oversight for critical applications.
- Computational Costs: Diffusion models demand significant computational resources, making real-time processing expensive for large-scale operations.
Mitigation Strategies
We address these challenges through:
- Strict validation on varied holdout datasets representing different geographic regions and sensor types.
- Human-in-the-loop verification for high-stakes applications like disaster response.
- Progressive model optimization starting with smaller, targeted prototypes before scaling.
Research Roadmap
Our next development phase focuses on:
- Multi-objective optimization: To handle complex prompts like “Enhance buildings for mapping while preserving vegetation spectral properties”.
- Cross-sensor adaptation: Enabling easy improvement across different satellite platforms and imaging modes.
- Temporal integration: Using image time series for improved enhancement quality.
- Edge deployment: Building models to process satellites or drones
Conclusion and Looking Forward
LLM-Guided Super-Resolution marks a key change from basic image improvement to smart, targeted image creation. By incorporating specific knowledge right into the process, we do more than produce clearer images; we generate data that leads to better analysis.
This approach goes beyond remote sensing. Using natural language to guide AI model behavior provides a way to make complicated technical systems easier for experts in various fields to understand. As we keep improving this framework, our goal is straightforward: turning satellite images from simple pixels into useful intelligence that helps with important decisions regarding our planet’s biggest challenges.
Published at DZone with permission of Pon Sudhir Sajan Siva Sankaran. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments