Building Fault-Tolerant Data Pipelines in GCP
This article provides a practical guide to building a fault-tolerant Google Cloud data pipeline architecture with Firestore, Pub/Sub, Dataflow, and BigQuery.
Join the DZone community and get the full member experience.
Join For FreeAfter years of building data pipelines on Google Cloud Platform, I’ve learned fault tolerance isn’t optional; it’s essential from day one. What sets a production-ready pipeline apart isn’t the architecture diagram but how it handles out-of-order changes, backlog, crashes, and quota limits.
This article distills lessons from real-world challenges: debugging issues at 3 a.m., handling unexpected load, and ensuring pipelines keep running through failures. The advice here is practical, not theoretical.
Why Fault Tolerance and Data Freshness Are Unavoidably Connected
Pipeline reliability isn’t just about uptime. If data is stale by even 20 minutes, the pipeline might as well be down for real-time needs like recommendations or dashboards.
In GCP pipelines that connect Firestore to BigQuery, fault tolerance and latency are two sides of the same coin. If you go overboard with resilience, you can end up with slow, laggy processing. If you only chase speed, you might be caught off guard when things fail. The real skill is in finding that sweet spot where your system stays both fast and sturdy.
So instead of asking whether to prioritize fault tolerance or speed, the real question is: how do you get both at the same time?

The diagram above illustrates this fundamental tension. At one extreme, you can build a pipeline with minimal resilience features — no retries, no error handling, direct writes — and achieve very low latency. But this fragility means that any failure results in data loss. At the other extreme, you can implement every conceivable safety mechanism — multi-region replication, excessive validation, multiple redundant checks — but the added overhead makes your pipeline unacceptably slow.
The sweet spot lies in the middle: implementing exactly-once semantics, dead-letter queues, checkpointing, and error segregation adds only 5-10 seconds of latency while dramatically improving resilience. This is the production-ready zone where most successful pipelines operate.
The Failure Patterns That Actually Occur
Certain failure patterns recur consistently in real-world data pipelines:
- Firestore change events can overwhelm downstream systems, creating processing backlogs or message expiration when flow control is not adequately enforced.
- Dataflow worker failures are inevitable, and pipelines must be designed to recover without losing or duplicating events.
- BigQuery streaming quotas are finite, and sudden traffic spikes can exceed limits, resulting in failed inserts, increased latency, or dropped data.
- Schema mismatches frequently occur when Firestore schema changes are not coordinated with pipeline teams, causing silent write failures or data inconsistencies.
- Network disruptions and regional outages can break pipelines that assume continuous, reliable connectivity.
In practice, these failures rarely occur in isolation. A schema change may coincide with a traffic surge and a transient network issue. True resilience is not about handling individual failures—it is about designing systems that continue to operate correctly when multiple failures occur simultaneously.
Lessons From Production Systems
Google’s SRE workbook highlights the real-world messiness of distributed systems: cascading failures, overloads, and hard trade-offs.
Error budgets for data freshness are essential. Measure data lag — the gap between Firestore event time and BigQuery query time — because it’s your contract with the business.
Resilience doesn’t require perfect parts. Protocols must assume failure is normal and design for graceful continuation when it happens.
Focus on graceful degradation, not total prevention of failures.
Building Resilience Into Each Layer
Certain patterns improve fault tolerance without hurting performance.
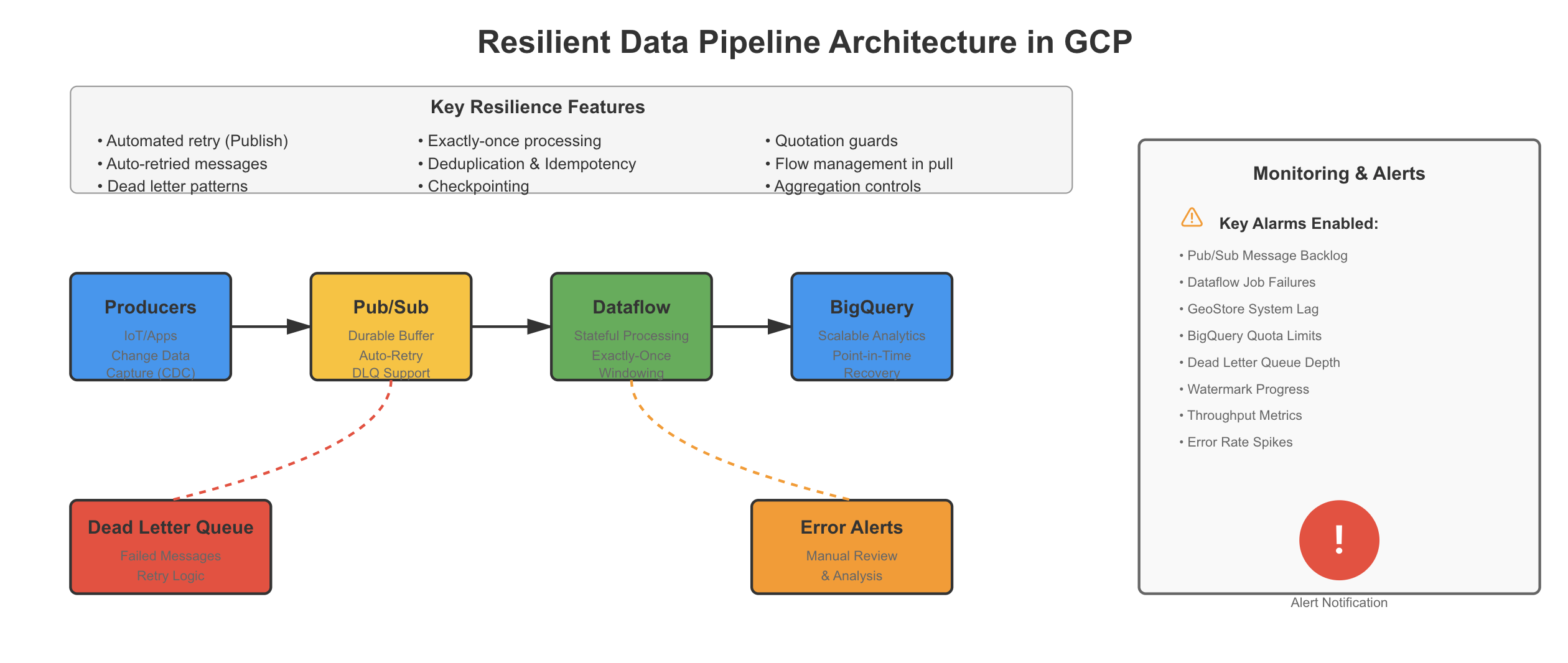
Firestore Change Capture: The Source of Truth
Firestore triggers offer a managed and dependable way to capture data changes. When a document is created, updated, or deleted, an event is automatically published to Pub/Sub, removing the need to build and maintain custom change data capture logic.
That said, triggers are not flawless. Events may fail to reach Pub/Sub if topics are misconfigured or destinations are temporarily unavailable. For this reason, it is essential to monitor trigger delivery and Pub/Sub ingestion closely. Missing events should be detected immediately, rather than discovered later when gaps appear in BigQuery.
Event ordering also deserves attention. Firestore emits changes in sequence, but once events flow through Pub/Sub, ordering depends on how subscriptions are configured. If ordering is important for your use case, Pub/Sub must be set up accordingly, and Dataflow pipelines should process events based on timestamps.
Firestore’s strong consistency, built-in replication, and fully managed triggers make it a reliable source of truth. However, reliability does not happen automatically. Continuous monitoring and alerting are still required to ensure that every change is captured and delivered as expected.
Pub/Sub as a Resilient Buffer
Pub/Sub acts as the buffer between Firestore and Dataflow, allowing each system to operate independently. When Firestore generates bursts of changes, Pub/Sub absorbs them. When Dataflow slows down or restarts, Pub/Sub safely retains messages until processing resumes.
Its resilience comes from durable storage and at-least-once delivery. Messages are replicated across zones, and configurable retention provides a recovery window when downstream systems are disrupted.
This resilience requires discipline. Because duplicates are possible, downstream processing must be idempotent. Processing the same event twice should always produce the same result.
Subscription configuration matters. Dead-letter topics are essential to isolate malformed events, so they do not block the pipeline. Acknowledgment deadlines also need careful tuning. If they are too short, messages are redelivered prematurely. If too long, failures increase lag. In practice, setting the deadline to two to three times the average processing time provides a good balance.
Dataflow: Where Processing Meets Resilience
Dataflow is where Firestore events are validated, enriched, and written to BigQuery, and it is where most failures surface.
The key resilience feature is exactly-once processing. When paired with the BigQuery Storage Write API, Dataflow ensures each event affects the output only once, even during worker restarts or retries. This avoids the trade-off between speed and correctness found in older streaming approaches.
Effective pipelines also separate error handling by type. Parsing errors, validation failures, and write failures should be routed and monitored independently, since each requires a different recovery strategy.
Error Handling by Design
A well-designed pipeline treats different failures differently. Incoming events first go through parsing. If JSON decoding fails or required fields are missing, the event is immediately routed to a dead-letter queue with the raw payload preserved. These failures usually indicate upstream issues, not data quality problems, and need fast visibility rather than retries.
Events that parse successfully move to validation, where business rules are applied. Validation errors reflect bad data, not system failures. These events are logged to an error table for analysis and feedback, while valid data continues flowing without interruption.
Finally, validated events are enriched and written to BigQuery. Write failures vary in nature. Quota issues trigger retries with backoff and alerts. Schema mismatches are routed for investigation. Transient errors are retried automatically. Separating failures this way makes production debugging far easier and avoids turning small issues into outages.
BigQuery: The Analytical Endpoint
BigQuery is resilient by default, but streaming pipelines still require care. The most common failure mode is quota exhaustion during traffic spikes. Micro-batching events instead of writing one at a time significantly reduces quota pressure while keeping latency low.
Schema evolution is another frequent source of issues. New fields in Firestore should be introduced as nullable, with controlled schema updates. Explicit schemas and documented evolution practices are safer than relying on automatic inference.
Partitioning and clustering improve more than performance. They limit the blast radius. When issues occur, affected partitions can be isolated or reprocessed without impacting the entire dataset. Separating real-time and historical query paths further improves stability by prioritizing fresh data where latency matters most.
Monitoring: The Early Warning System
Observability is non-negotiable in streaming pipelines. The most important metric is data lag, the gap between when an event occurs and when it becomes available for analysis. Lag directly reflects whether latency expectations are being met.
In Pub/Sub, monitor backlog size and message age. In Dataflow, track processing lag and watermark progression. In BigQuery, watch streaming insert success rates and quota usage. These signals reveal problems long before users notice missing data.
Alerts should be tiered and contextual. Minor lag increases warrant investigation, SLA breaches require prompt action, and rapidly growing dead-letter queues signal serious degradation. Thoughtful thresholds prevent alert fatigue while ensuring real issues get immediate attention.
Recovery Patterns That Work
Resilient pipelines assume failures will happen and recover cleanly. Checkpointing ensures workers can restart without reprocessing everything. Idempotent operations ensure retries do not create duplicates. Exactly-once semantics, enabled through the BigQuery Storage Write API, make this practical at scale.
Dead-letter queues prevent bad data from blocking good data. Retry policies must be balanced. Too few retries cause unnecessary loss; too many slow the pipeline. Exponential backoff with jitter avoids retry storms and helps systems recover during transient failures.
Canary deployments reduce risk by validating changes on a small slice of traffic before full rollout. Chaos testing exposes weaknesses early by deliberately breaking components in controlled environments. These practices turn resilience from theory into habit.
What Production Teaches You
Resilience is not a one-time design decision. It is built through incidents, postmortems, and continuous improvement. Every failure is a chance to strengthen monitoring, refine recovery paths, and reduce future risk.
Strong resilience is as much cultural as technical. Teams need safety to report issues, discipline to document lessons learned, and time to fix systemic problems. Simple systems with strong operational practices often outperform complex systems without them.
The real success of a pipeline is not elegant diagrams. It is when failures happen quietly, and users never notice.
Conclusion
Distributed systems fail by default. Traffic spikes, schema changes, and outages are normal operating conditions. GCP provides strong building blocks, but resilience comes from how those components are composed, monitored, and operated.
Resilient pipelines are not built to avoid failure. They are built to absorb it, recover quickly, and protect the business when things go wrong.
Key Takeaways
- Design for failure, not perfection
- Separate error handling by failure type
- Measure lag, backlog, and watermarks relentlessly
- Use checkpointing, idempotency, and dead-letter queues by default
- Treat resilience as an operational discipline, not an afterthought
The goal is not zero failures. The goal is graceful degradation, fast recovery, and uninterrupted service when failures inevitably occur.
Opinions expressed by DZone contributors are their own.
Comments