Data Lakehouse vs. Data Mesh: Rethinking Scalable Data Architectures in 2026
Organizations are blending Data Lakehouse and Data Mesh paradigms — together forming a hybrid, future-ready data architecture.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Over the last decade, the data ecosystem has changed immensely. Data warehouses, the core of analytics, faced issues with unstructured data and scaling. Meanwhile, early data lakes offered some level of flexibility, but poorly governed data and schema drift led to numerous problems.
Now, there are two new contenders to the data paradigm: the Data Lakehouse and the Data Mesh. Both are futuristic scalable data architectures, but each has a different approach to the core problem. In 2026, enterprises will continue to face the question of whether to modernize with a centralized Lakehouse or a decentralized Mesh.
The following sections of this article will examine these two paradigms in detail. It will explore their architectures, the trade-offs involved, and the trends each is following in relation to each other.
Understanding the Data Lakehouse Paradigm
The Origins
The Data Lakehouse was designed to combine the scalability of data lakes with the dependability of data warehouses. Although data lakes provided cheap and adaptable storage, there were no ACID transactions, no schema governance, and little oversight in the data lakes. Creating systems like Delta Lake, Apache Iceberg, and Apache Hudi provided metadata management and introduced transactional interfaces over open systems file storage and Parquet files. These innovations closed the gaps between data lakes and warehouses.
Key Characteristics
The standard characteristics of a Lakehouse encompass:
• Unified Storage: Centralized data stored in open formats like Parquet.
• Transactional Integrity: ACID guarantees through Delta or Iceberg tables.
• Compute-Storage Separation: Multiple engines like Spark, Presto, or Trino can read data simultaneously.
• Integrated Governance: Systems like Databricks Unity Catalog or AWS Glue manage lineage and permissions.
The Lakehouse serves as a single source of truth, combining streaming, batch, and machine learning (ML) workloads. It is particularly beneficial for organizations that require centralized governance over large, complex datasets.
The Rise of Data Mesh
Rethinking Centralization
Although Lakehouse addresses technical inefficiencies, organizational bottlenecks remain. Central data teams in charge of monolithic platforms can become overstretched, which hinders delivery to the various business domains.
Data Mesh, a concept introduced by Zhamak Dehghani, aims to break this centralization. It encourages assigning data ownership to business realms and treating data as a product, rather than a byproduct of everyday operations.
Core Principles
Data Mesh is built on four key pillars:
-
Domain-Oriented Ownership: Each domain is responsible for its data pipelines and publishing usable “data products.”
-
Data as a Product: Datasets are versioned, discoverable, and documented for reuse.
-
Self-Service Infrastructure: Creating self-serve capabilities such as building data quality checks and CI/CD pipelines.
-
Federated Governance: Global policies are implemented with local variations — autonomy vs. compliance.
The Mesh focuses on organizational scalability rather than purely on technical consolidation.
Lakehouse vs. Mesh: Comparative Analysis
| Dimension | Data Lakehouse | Data Mesh |
|---|---|---|
| Design Focus | Centralized storage and governance | Decentralized domain autonomy |
| Ownership Model | Managed by a central data platform team | Owned by business domains |
| Governance | Unified catalog and metadata | Federated policy enforcement |
| Scaling Focus | Technical (compute, storage, concurrency) | Organizational (ownership, agility) |
The Lakehouse emphasizes efficiency and consistency, while the Mesh emphasizes autonomy and adaptability. Both can coexist when designed with shared governance and interoperability.
Scalability and Performance
The Lakehouse is designed for throughput and consistency to support large analytical workloads by distributed compute and storage [3]. It is best for use cases requiring global optimization like company-wide dashboards, data science models, or real-time analytics.
The Mesh, on the other hand, scales organizationally. It lacks platform support if domain owners are empowered to independently deploy and experiment, as performance tuning in the inter-domain and cross-domain Mesh is likely to be uneven.
Governance and Compliance
A single-body governance system is a notable benefit of a Lakehouse. With unified catalogs, enterprises can execute schema validation, access control, and lineage tracking. This makes it perfect for industries that are highly regulated such as healthcare and finance [2].
Cost Efficiency
From an infrastructure point of view:
• Lakehouse: Optimizes the utilization of compute and storage at the same time through centralization.
• Mesh: It is possible to reduce operational friction through the distribution of human ownership.
Smaller organizations are those that tend to adopt a Lakehouse strategy first, especially if they are trying to reduce costs. Larger organizations with complicated data ecosystems tend to Mesh as their model once their platform is stable [5].
Implementation Complexity
A Lakehouse can be described as a technical challenge of implementation where table formats, compute engines, and catalogs are integrated. In contrast, a Mesh implementation represents a socio-technical transformation where people and culture are the core of the change.
The success of a Lakehouse depends on its data engineers; the success of a Mesh relies on the cooperation of disparate sectors, particularly the technical side and the commercial side [1].
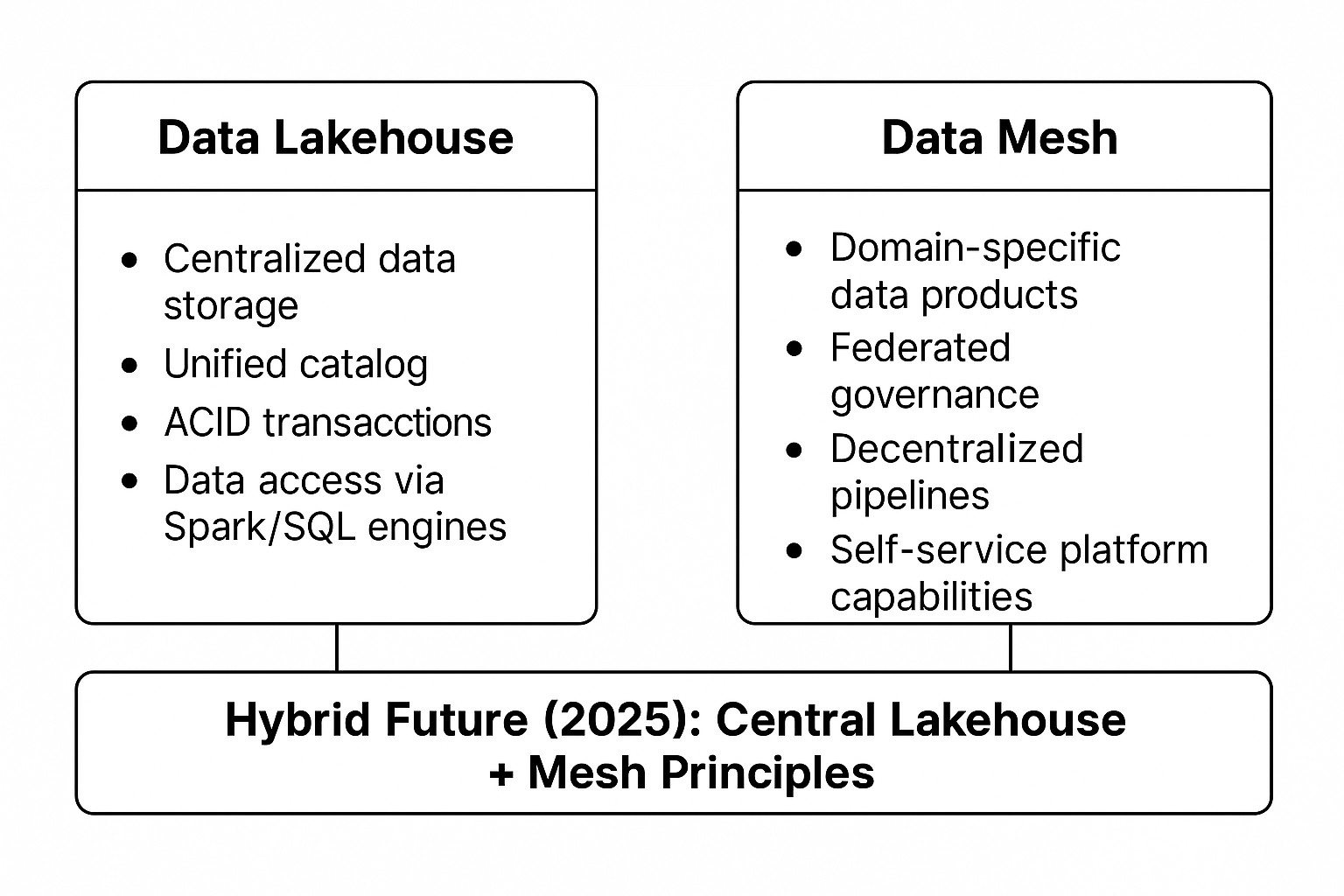
Real-World Trends in 2025 and Beyond
The Hybrid Adoption Curve
Beyond 2025, the difference between Lakehouse and Mesh will continue to fade. Most organizations are adopting hybrid frameworks, with Lakehouses providing the central infrastructure and Mesh principles controlling the publishing and consumption of data [3][5].
Consider the following:
- The platform team oversees Delta Lake storage along with the Unity Catalog, and CI/CD templates.
- Domain teams constructing the pipelines using the shared platform take ownership of the quality and delivery of their data products.
- Governance is federated, standardized, and interoperable across the ecosystem.
This setup combines the best of technical efficiency and organizational flexibility.
Industry Examples
- Retail: Centrally planned Lakehouse for transactional data, Mesh domains for analytics in personalization and supply chains.
- Banking: Compliance Lakehouse with Mesh for innovation in fraud detection.
- Healthcare: Lakehouse for HIPAA-compliant storage with Mesh for responsible publishing of ML domain-annotated models.
These examples show that hybrid models demonstrate Lakehouse and Mesh are not opponents in modern data architecture, but rather, they are complements [5].
Key Considerations Before Choosing
When to Choose a Data Lakehouse
- Your primary goal is centralized governance and cost optimization.
- You manage diverse data types (structured, semi-structured, unstructured).
- Your data team is small or moderately centralized.You want consistent and cohesive reporting across all your data.
When to Consider a Data Mesh
Your company has several independent business units. You need your teams to iterate more quickly. Your organization has a well-established data culture and data fluency across business units. You operate on a data platform such as a Lakehouse that allows for decentralization. [4]
Conclusions
The choice for organizations is no longer Data Lakehouse or Data Mesh. It is both. The Lakehouse provides the primitives — scalable storage, ACID transactions, and unified governance — while the Mesh provides the organizational model that democratizes access and ownership.
Predictably, in 2026, organizations will continue working on hybrid data ecosystems within the Mesh and Lakehouse. The architecture will be centrally governed and will allow for autonomy. The Mesh will be governed by the Lakehouse, providing the governance and control that allows for agility, and scalability will be matched with accountability.
The architecture will prioritize collaboration over centralization, federation over fragmentation, and will be adaptable rather than rigid.
References
[1] Databricks Blog, “What Is a Data Lakehouse?”, 2023.
[2] AWS Big Data Blog, “Modernizing Data Lakes with Apache Iceberg,” 2024.
[3] Gartner Research, “The Future of Data Management: Hybrid Architectures,” 2025.
[4] Z. Dehghani, Data Mesh: Delivering Data-Driven Value at Scale, O’Reilly Media, 2022.
[5] ThoughtWorks Technology Radar, “Data Mesh and Lakehouse Trends,” Vol. 29, 2024.
Opinions expressed by DZone contributors are their own.
Comments