Data Privacy Mechanisms and Attacks
In this article, learn more about Data Privacy Mechanisms based on anonymization and perturbation, and gain insight into possible attacks.
Join the DZone community and get the full member experience.
Join For FreeA large volume of sensitive personal data is collected on a day-to-day basis by organizations like hospitals, financial institutions, government agencies, social networks, and insurance companies. The purpose of the organization can be to extract and publish useful information about the data while protecting the private information of individuals.
Data privacy laws, regulations, and issues come up when an organization wants to share or publish private data of individuals while at the same time wanting to protect their personally identifiable information.
There are two main research focuses for the implementation of data privacy.
- Perturbation: Addition of noise (i.e., differential privacy)
- Anonymization: Anonymize data records (i.e., k-anonymity, l-diversity, t-closeness)
The aim is to release or publish the private data such that there can be guarantees to the participating individuals that they cannot be identified while the released data is still useful.
Records in a data set are uniquely identified by a set of identifiers associated with it. The first step towards anonymization is the removal of these identifiers. For example, if the name, phone number, and address fields are removed from the medical data published by a hospital, it can be assumed to be anonymous. However, it is not sufficient as there are still link attacks that can be done to uniquely identify individuals.
For example, two sets of data can be obtained from different sources like a voter registration list and the anonymous data released by medical organizations from which the unique identifiers have been removed. These two can be linked based on their common attributes (zip code, birth date, gender, etc.) to identify individuals and their medical conditions.
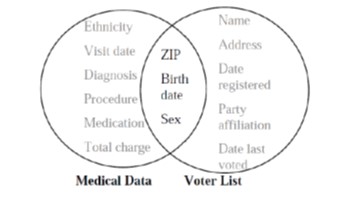
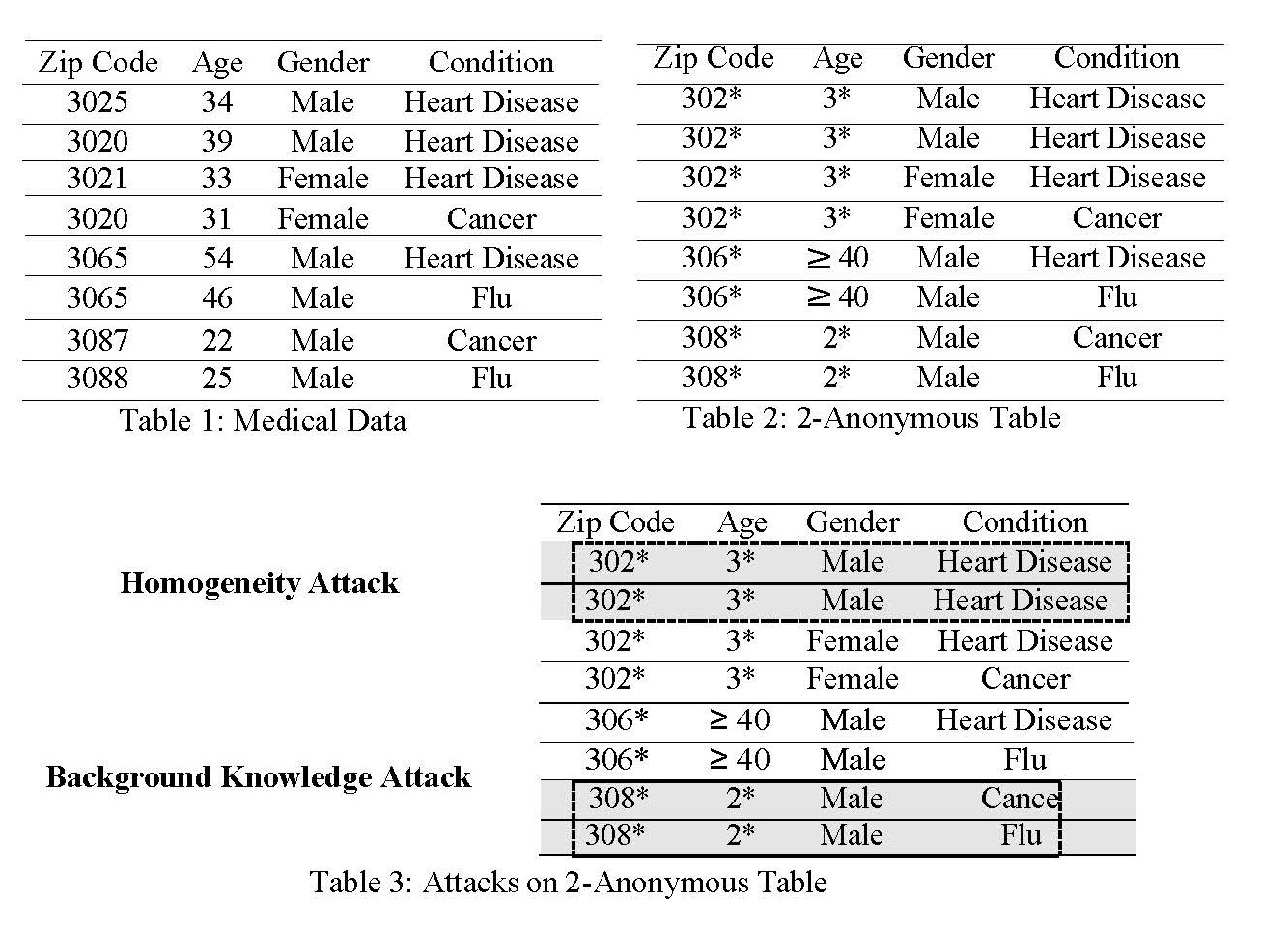
k-anonymity is a privacy protection model where the information of each individual cannot be distinguished from at least k-1 individuals whose information also appears in the database. k-anonymity provides a “blend in the crowd" approach to privacy; however, it is still subject to link and homogeneity attacks. There are attacks possible in which case k-anonymity fails to provide privacy which are:
- Homogeneity Attack: This is possible when the sensitive attribute lacks diversity in its values. For example, if the attacker knows that he is trying to find information for his neighbor (zip code 3024) Mark who is nearly 33-year-old, then looking at the 2-anonymized in Table 3, he knows that Mark has heart disease.
- Background knowledge attack: This is when the attacker has background knowledge. For example, if the attacker knows that Mark, his 25-year-old neighbor (zip code:3087), is seriously ill and was taken in an ambulance, then by looking at Table 3, he knows that he has either flu or cancer. Since he knows he is seriously ill and in the hospital for a long time, he knows that he has cancer.
 Privacy algorithms like l-diversity and t-closeness protect against some of these attacks, but they still have limitations. For example, l-diversity does not protect against probabilistic inference attacks and similarity attacks.
Privacy algorithms like l-diversity and t-closeness protect against some of these attacks, but they still have limitations. For example, l-diversity does not protect against probabilistic inference attacks and similarity attacks.
- Similarity attack: Since l-diversity does not consider the semantic meanings of sensitive values there could be blocks with very similar values of the sensitive attribute hence providing little or no privacy.
The Differential Privacy model claims that it provides a stronger privacy guarantee than the above-discussed models, as it does not require any assumptions about the data and protects against attackers who know all but one row in the database. It provides privacy guarantees regardless of the background knowledge and computational power of the attacker. Differential privacy originated as a model for interactive databases and seeks to limit the knowledge that users obtain from query responses. It was later extended to privacy-preserving data publishing.
For data publishing, both t-closeness and differential privacy limit disclosure, as an attacker’s prior knowledge is limited to their prior knowledge about the distribution of confidential attributes.
The Differential Privacy model provides privacy guarantees where the overall information gained by an adversary does not change, whether an individual opts to be present or absent in the data. The objective is as follows: if a disclosure occurs when an individual participates in the database, then the same disclosure also occurs with a similar probability (within a small multiplicative factor) even when the individual does not participate. Differential privacy attempts to break the strong correlation between the output of a function (or algorithm) from its set of inputs such that a small change in the input data set should not cause huge variations in the output.
However, there are challenges to implementing differential private systems. The first is how to adapt to time series data or highly co-related data. For time series data, the composition property adds up the noise added at each timestamp to generate a huge amount of noise in the series. It is known that differential privacy does not protect against attackers' auxiliary information. The biggest challenge is privacy vs utility, which is how to reduce noise while still maintaining the utility of the results. It is a challenge to tune the data privacy approach based on the tradeoff between utility and privacy, and create metrics to evaluate the model quality measuring utility loss and privacy gain, and strike the right balance.
Opinions expressed by DZone contributors are their own.
Comments