Fine-Tuning Microsoft’s LayoutLM Model for Invoice Recognition
In this article, we will fine-tune the recently released Microsoft’s LayoutLM model on an annotated custom dataset that includes French and English invoices.
Join the DZone community and get the full member experience.
Join For Free
Introduction
Building on my recent tutorial on how to annotate PDFs and scanned images for NLP applications, we will attempt to fine-tune the recently released Microsoft’s Layout LM model on an annotated custom dataset that includes French and English invoices. While the previous tutorials focused on using the publicly available FUNSD dataset to fine-tune the model, here we will show the entire process starting from annotation and pre-processing to training and inference.
LayoutLM Model
The LayoutLM model is based on BERT architecture but with two additional types of input embeddings. The first is a 2-D position embedding that denotes the relative position of a token within a document, and the second is an image embedding for scanned token images within a document. This model achieved new state-of-the-art results in several downstream tasks, including form understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24), and document image classification (from 93.07 to 94.42). For more information, refer to the original article.
Thankfully, the model was open-sourced and made available in the huggingface library. Thanks, Microsoft!
For this tutorial, we will clone the model directly from the huggingface library and fine-tune it on our own dataset. Here is a link to Google Colab but first, we need to create the training data.
Invoice Annotation
Using a text annotation tool, I have annotated around 50 personal invoices. I am interested to extract both the keys and values of the entities; for example in the following text “Date: 06/12/2021” we would annotate “Date” as DATE_ID and “06/12/2021” as DATE. Extracting both the keys and values will help us correlate the numerical values to their attributes. Here are all the entities that have been annotated:
DATE_ID, DATE, INVOICE_ID, INVOICE_NUMBER,SELLER_ID, SELLER, MONTANT_HT_ID, MONTANT_HT, TVA_ID, TVA, TTC_ID, TTC
Here are a few entity definitions:
MONTANT_HT: Total price pre-taxTTC: Total price with taxTVA: Tax amount
Below is an example of an annotated invoice using UBIAI:
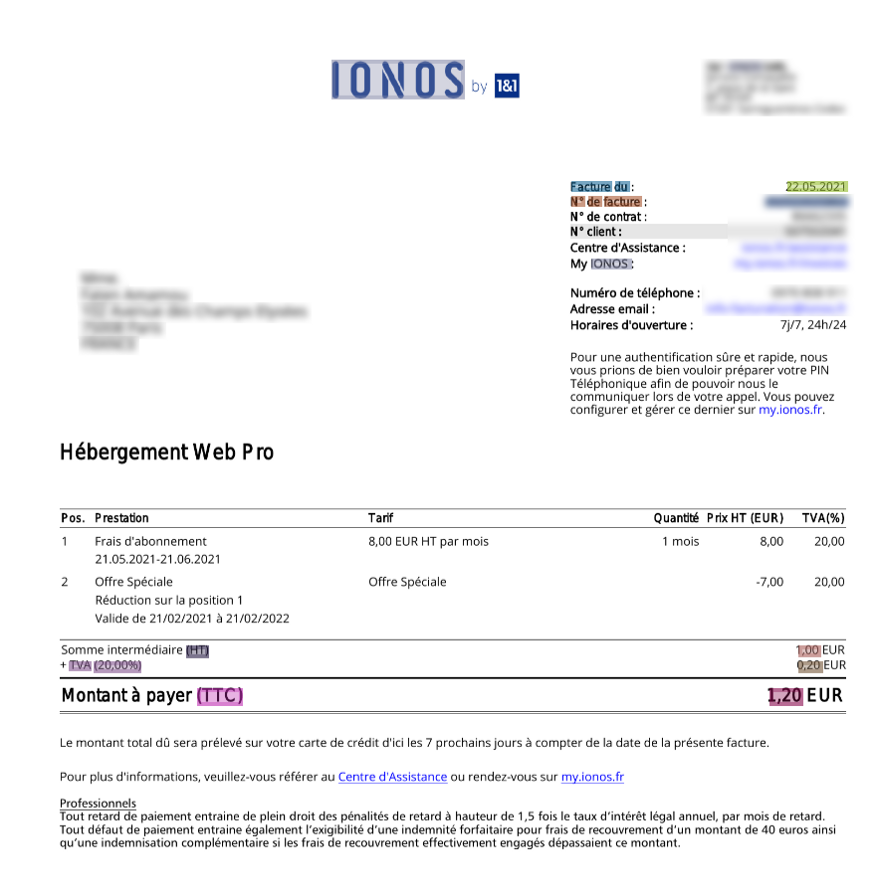
After annotation, we export the train and test files from UBIAI directly in the correct format without any pre-processing step. The export will include three files for each training and test dataset and one text file containing all the labels named labels.txt:
Train/Test.txt
2018 O
Sous-total O
en O
EUR O
3,20 O
€ O
TVA S-TVA_ID
(0%) O
0,00 € S-TVA
Total B-TTC_ID
en I-TTC_ID
EUR E-TTC_ID
3,20 S-TTC
€ O
Services O
soumis O
au O
mécanisme O
d'autoliquidation O
- O
Train/Test_box.txt (contain bounding box for each token):
€ 912 457 920 466
Services 80 486 133 495
soumis 136 487 182 495
au 185 488 200 495
mécanisme 204 486 276 495
d'autoliquidation 279 486 381 497
- 383 490 388 492
Train/Test_image.txt (contain bounding box, document size, and name):
€ 912 425 920 434 1653 2339 image1.jpg
TVA 500 441 526 449 1653 2339 image1.jpg
(0%) 529 441 557 451 1653 2339 image1.jpg
0,00 € 882 441 920 451 1653 2339 image1.jpg
Total 500 457 531 466 1653 2339 image1.jpg
en 534 459 549 466 1653 2339 image1.jpg
EUR 553 457 578 466 1653 2339 image1.jpg
3,20 882 457 911 467 1653 2339 image1.jpg
€ 912 457 920 466 1653 2339 image1.jpg
Services 80 486 133 495 1653 2339 image1.jpg
soumis 136 487 182 495 1653 2339 image1.jpg
au 185 488 200 495 1653 2339 image1.jpg
mécanisme 204 486 276 495 1653 2339 image1.jpg
d'autoliquidation 279 486 381 497 1653 2339 image1.jpg
- 383 490 388 492 1653 2339 image1.jpg
labels.txt:
B-DATE_ID
B-INVOICE_ID
B-INVOICE_NUMBER
B-MONTANT_HT
B-MONTANT_HT_ID
B-SELLER
B-TTC
B-DATE
B-TTC_ID
B-TVA
B-TVA_ID
E-DATE_ID
E-DATE
E-INVOICE_ID
E-INVOICE_NUMBER
E-MONTANT_HT
E-MONTANT_HT_ID
E-SELLER
E-TTC
E-TTC_ID
E-TVA
E-TVA_ID
I-DATE_ID
I-DATE
I-SELLER
I-INVOICE_ID
I-MONTANT_HT_ID
I-TTC
I-TTC_ID
I-TVA_ID
O
S-DATE_ID
S-DATE
S-INVOICE_ID
S-INVOICE_NUMBER
S-MONTANT_HT_ID
S-MONTANT_HT
S-SELLER
S-TTC
S-TTC_ID
S-TVA
S-TVA_ID
Fine-Tuning LayoutLM Model
Here, we use Google Colab with GPU to fine-tune the model. The code below is based on the original layoutLM paper and this tutorial.
First, install the layoutLM package.
! rm -r unilm! git clone -b remove_torch_save https://github.com/NielsRogge/unilm.git! cd unilm/layoutlm! pip install unilm/layoutlm
As well as the transformer package from where the model will be downloaded:
! rm -r transformers! git clone https://github.com/huggingface/transformers.git! cd transformers! pip install ./transformers
Next, create a list containing the unique labels from labels.txt:
from torch.nn import CrossEntropyLossdef get_labels(path): with open(path, "r") as f: labels = f.read().splitlines() if "O" not in labels: labels = ["O"] + labels return labelslabels = get_labels("./labels.txt") num_labels = len(labels) label_map = {i: label for i, label in enumerate(labels)} pad_token_label_id = CrossEntropyLoss().ignore_index
Then, create a PyTorch dataset and data loader:
from transformers import LayoutLMTokenizer from layoutlm.data.funsd import FunsdDataset, InputFeatures from torch.utils.data import DataLoader, RandomSampler, SequentialSamplerargs = {'local_rank': -1, 'overwrite_cache': True, 'data_dir': '/content/data', 'model_name_or_path':'microsoft/layoutlm-base-uncased', 'max_seq_length': 512, 'model_type': 'layoutlm',}# class to turn the keys of a dict into attributes class AttrDict(dict): def __init__(self, *args, **kwargs): super(AttrDict, self).__init__(*args, **kwargs) self.__dict__ = selfargs = AttrDict(args)tokenizer = LayoutLMTokenizer.from_pretrained("microsoft/layoutlm-base-uncased")# the LayoutLM authors already defined a specific FunsdDataset, so we are going to use this here train_dataset = FunsdDataset(args, tokenizer, labels, pad_token_label_id, mode="train") train_sampler = RandomSampler(train_dataset) train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=2)eval_dataset = FunsdDataset(args, tokenizer, labels, pad_token_label_id, mode="test") eval_sampler = SequentialSampler(eval_dataset) eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=2)batch = next(iter(train_dataloader))input_ids = batch[0][0]tokenizer.decode(input_ids)
Load the model from huggingface. This will be fine-tuned on the dataset.
from transformers import LayoutLMForTokenClassification import torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = LayoutLMForTokenClassification.from_pretrained("microsoft/layoutlm-base-uncased", num_labels=num_labels) model.to(device)
Finally, start the training:
from transformers import AdamW from tqdm import tqdmoptimizer = AdamW(model.parameters(), lr=5e-5)global_step = 0 num_train_epochs = 50 t_total = len(train_dataloader) * num_train_epochs # total number of training steps#put the model in training mode model.train() for epoch in range(num_train_epochs): for batch in tqdm(train_dataloader, desc="Training"): input_ids = batch[0].to(device) bbox = batch[4].to(device) attention_mask = batch[1].to(device) token_type_ids = batch[2].to(device) labels = batch[3].to(device)# forward pass outputs = model(input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids, labels=labels) loss = outputs.loss# print loss every 100 steps if global_step % 100 == 0: print(f"Loss after {global_step} steps: {loss.item()}")# backward pass to get the gradients loss.backward()#print("Gradients on classification head:") #print(model.classifier.weight.grad[6,:].sum())# update optimizer.step() optimizer.zero_grad() global_step += 1
You should be able to see the training progress and the loss getting updated.
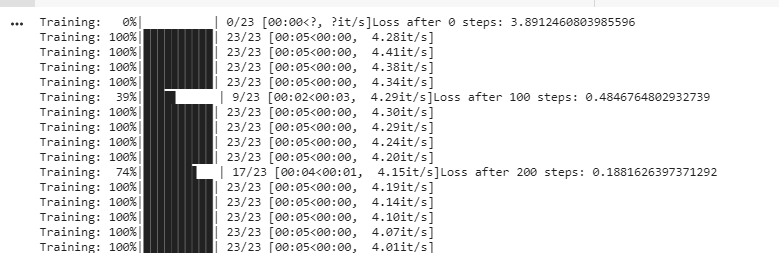
After training, evaluate the model performance with the following function:
import numpy as np from seqeval.metrics import ( classification_report, f1_score, precision_score, recall_score, )eval_loss = 0.0 nb_eval_steps = 0 preds = None out_label_ids = None# put model in evaluation mode model.eval() for batch in tqdm(eval_dataloader, desc="Evaluating"): with torch.no_grad(): input_ids = batch[0].to(device) bbox = batch[4].to(device) attention_mask = batch[1].to(device) token_type_ids = batch[2].to(device) labels = batch[3].to(device)# forward pass outputs = model(input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids, labels=labels) # get the loss and logits tmp_eval_loss = outputs.loss logits = outputs.logitseval_loss += tmp_eval_loss.item() nb_eval_steps += 1# compute the predictions if preds is None: preds = logits.detach().cpu().numpy() out_label_ids = labels.detach().cpu().numpy() else: preds = np.append(preds, logits.detach().cpu().numpy(), axis=0) out_label_ids = np.append( out_label_ids, labels.detach().cpu().numpy(), axis=0 )# compute average evaluation loss eval_loss = eval_loss / nb_eval_steps preds = np.argmax(preds, axis=2)out_label_list = [[] for _ in range(out_label_ids.shape[0])] preds_list = [[] for _ in range(out_label_ids.shape[0])]for i in range(out_label_ids.shape[0]): for j in range(out_label_ids.shape[1]): if out_label_ids[i, j] != pad_token_label_id: out_label_list[i].append(label_map[out_label_ids[i][j]]) preds_list[i].append(label_map[preds[i][j]])results = { "loss": eval_loss, "precision": precision_score(out_label_list, preds_list), "recall": recall_score(out_label_list, preds_list), "f1": f1_score(out_label_list, preds_list), }
With only 50 documents, we get the following scores:

With more annotations, we should certainly get higher scores.
Finally, save the model for future prediction:
PATH='./drive/MyDrive/trained_layoutlm/layoutlm_UBIAI.pt'torch.save(model.state_dict(), PATH)
Inference
Now comes the fun part, let’s upload an invoice, OCR it, and extract relevant entities. For this test, we are using an invoice that was not in the training or test dataset. To parse the text from the invoice, we use the open-source Tesseract package. Let’s install the package:
!sudo apt install tesseract-ocr!pip install pytesseract
Before running predictions, we need to parse the text from the image and pre-process the tokens and bounding boxes into features. To do so, I have created a preprocess python file layoutLM_preprocess.py that will make it easier to preprocess the image:
import sys sys.path.insert(1, './drive/MyDrive/UBIAI_layoutlm') from layoutlm_preprocess import *image_path='./content/invoice_test.jpg'image, words, boxes, actual_boxes = preprocess(image_path)
Next, load the model and get word predictions with their bounding boxes:
model_path='./drive/MyDrive/trained_layoutlm/layoutlm_UBIAI.pt'model=model_load(model_path,num_labels)word_level_predictions, final_boxes=convert_to_features(image, words, boxes, actual_boxes, model)
Finally, display the image with the predicted entities and bounding boxes:
draw = ImageDraw.Draw(image)font = ImageFont.load_default()def iob_to_label(label): if label != 'O': return label[2:] else: return ""label2color = {'data_id':'green','date':'green','invoice_id':'blue','invoice_number':'blue','montant_ht_id':'black','montant_ht':'black','seller_id':'red','seller':'red', 'ttc_id':'grey','ttc':'grey','':'violet', 'tva_id':'orange','tva':'orange'}for prediction, box in zip(word_level_predictions, final_boxes): predicted_label = iob_to_label(label_map[prediction]).lower() draw.rectangle(box, outline=label2color[predicted_label]) draw.text((box[0] + 10, box[1] - 10), text=predicted_label, fill=label2color[predicted_label], font=font)image
Et voila:
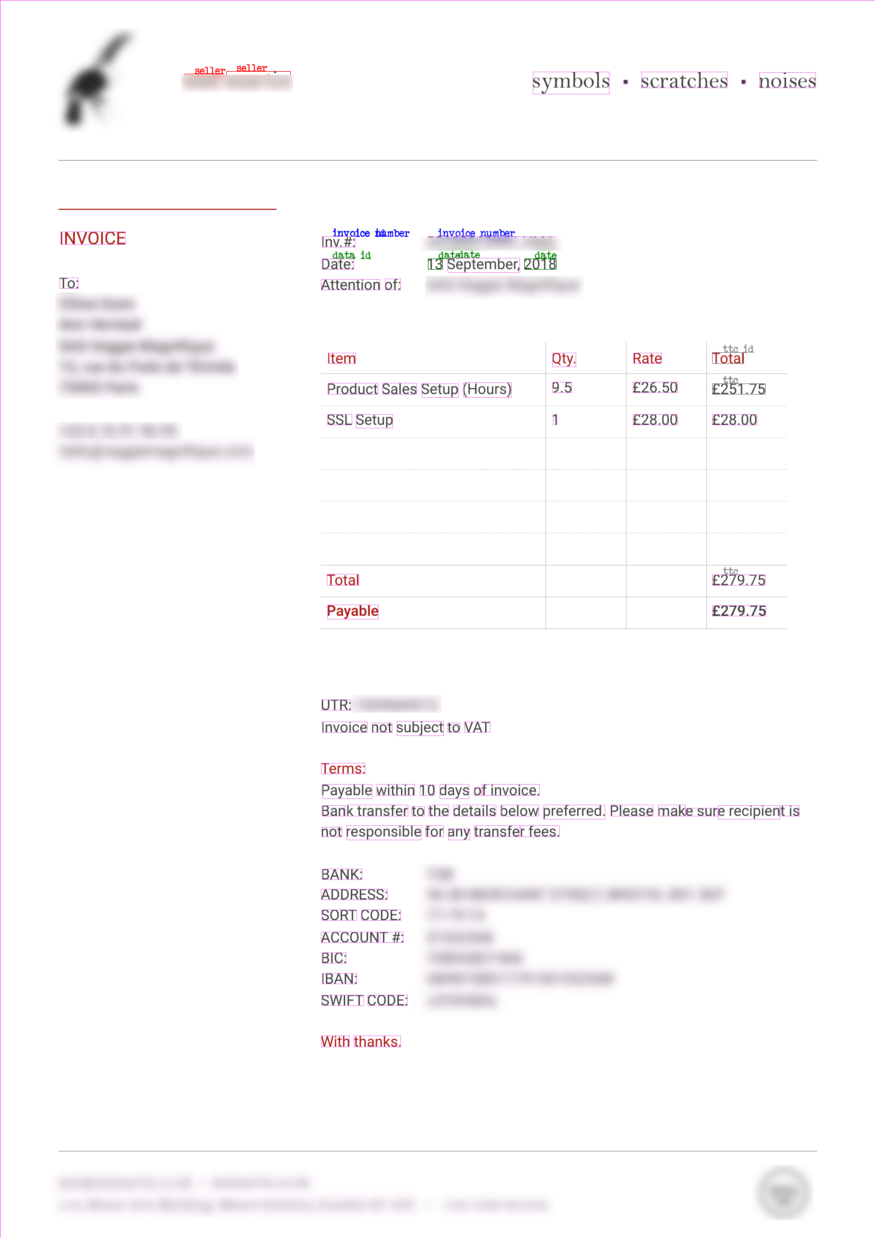
While the model made a few mistakes such as assigning the TTC label to a purchased item or not identifying some IDs, it was able to extract the seller, invoice number, date, and TTC correctly. The results are impressive and very promising given the low number of annotated documents (only 50)! With more annotated invoices, we will be able to reach higher F scores and more accurate predictions.
Conclusion
Overall, the results from the LayoutLM model are very promising and demonstrate the usefulness of transformers in analyzing semi-structured text. The model can be fine-tuned on any other semi-structured documents such as driver licenses, contracts, government documents, financial documents, etc.
If you have any questions, don’t hesitate to ask below.
If you liked this article, please like and share!
Published at DZone with permission of Walid Amamou. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments