GenAI in Java With Merlinite, Quarkus, and Podman Desktop AI Lab
Discover the simple and easy way to quickly get up and running with containerized LLMs and AI-infused Quarkus applications in Java.
Join the DZone community and get the full member experience.
Join For FreeGenAI is everywhere these days, and I feel it is particularly hard for developers to navigate the almost endless possibilities and catch up with all the learning that seems upon us. It's time for me to get back to writing and make sure nobody feels left behind in this craziness.
GenAI Use Cases For Developers
As developers, we basically have to deal with two main aspects of artificial intelligence.
The first one is how to use the enhanced tooling available to us now. There are plenty of IDE plug-ins, web-based tools, and chatbots that promise to help us be more efficient with coding. Bad news first: this article doesn't cover a bit about this. You're on your own figuring out what suits you and helps you best. I am personally following what Stephan Janssen is doing with his Devoxx Ginie Plug-In, in case you need some inspiration to look at something.
The second biggest aspect, on the other hand, is indeed something I want to write about in this article. It's how to incorporate "intelligence" into our own applications, and where to even start. This is particularly challenging if you are completely new to the topic and haven't had a chance to follow what is going on for a little over a year now.
Finding, Tuning, and Running Suitable Models, Locally
I will spare you an introduction about what AI models are and what types are available. Honestly, I've been digging into the basics quite a bit for a while and have to admit that it gets data-science-y very quickly. Especially if you see yourself more on the consuming side of artificial intelligence, there is probably very little value to deep dive into the inner workings. The following is a very condensed and opinionated view of models and how I personally think about them. If you want to learn all the basics, feel free to follow your passion.
There are uncountable models out there already, and they all have a specific set of training data that theoretically makes them a fit for solving business challenges. Getting a model to this point is the basic step, and it is called "training" (probably one of the most expensive things you ever planned to do in your whole career). I like to call the outcome state of an initially trained model "foundation." Those foundation models (e.g., GPT-n, BERT, LLAMA-n, etc.) have been trained on a broad data set, making them a mediocre fit for pretty much everything. And they come with some disadvantages. They don't know much about your specific problem, they probably don't disclose what kind of data has been used to train them, and they might just make things up and some other downsides. You might wanna look for smaller and more suitable models that you can actually influence, at least partly. Instead of "influence" I probably should say "infuse" or "tune" with additional context.
There are various ways to "tune" a model (compare the image below), and the approach depends on your goals.
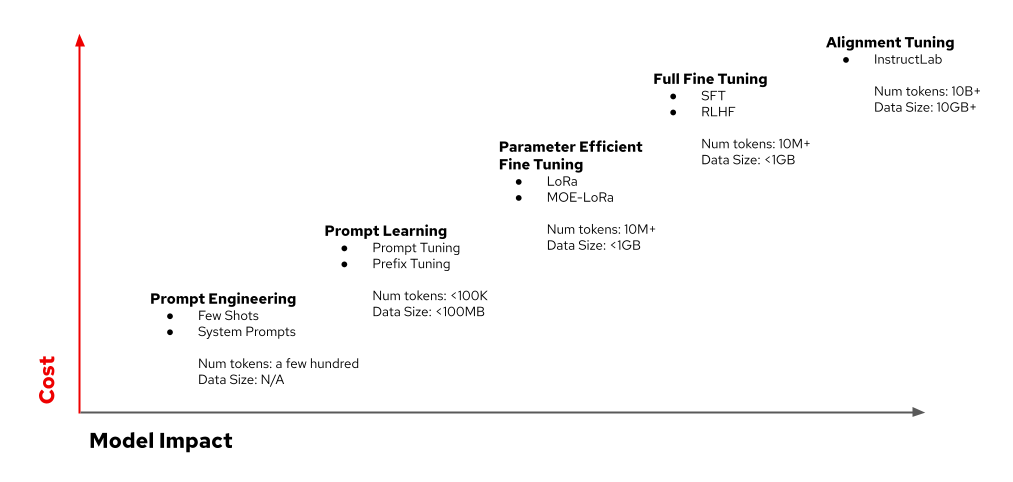
On the very left side, you see what is commonly known as "prompt engineering," which is kind of an "on the fly" model tuning, and on the very upper right side, you see full "alignment tuning." While alignment tuning actually changes model weights and behavior, prompt tuning does not.
You may have already guessed that every single one of these steps has not only a quality difference but also a cost difference attached to it. I am going to talk mostly about a version of prompt tuning in this article, but wanted to also get you excited about the alignment tuning. I will use the Merlinite-7B model further down in this article. The main reason is that it is an open-source model and it has a community attached to it, so you can help contribute knowledge and grow transparent training data. Make sure to check out InstructLab and dive into LAB tuning a little more.
Well, now that I picked a model, how do we run it locally? There are (again) plenty of alternatives and ways. And trying to research and understand the various formats and ways left me exhausted quickly. My developer mind wanted to understand models like deployments with endpoints that I could access. Thankfully, this is slowly but surely becoming a reality. With various binary model formats in the wild, the GGUF format was introduced late last year by the team creating the most broadly used endpoint API (llama.cpp) right now.
When I talk about endpoints and APIs, I should at least introduce the term "inference." This is basically what data scientists call a query to a model. And it is called this because inferences are steps in reasoning, moving from premises to consequences. It basically is a beautiful way to explain how AI models work.
Back to llama.cpp, which is written in C/C++ and serves as an inference engine for various model formats on a variety of hardware, locally and in the cloud: The llama.cpp web server provides an OpenAI compatible API that can be used to serve local models and connects them to clients (thanks to the OpenAI folks for the MIT license on the API!). More on the API part later. Let's get this thing fired up locally. But wait, C/C++ you said? and GGUF? How do I? Well, easy. Just use Podman Desktop AI lab. It is an extension to the desktop client released last year which lets you work with models locally. It is a one-click installation if you have Podman Desktop running already, and all that is left to do is to download a desired model via the Model Catalog.
When that is done, we need to create a Model Service and run it.
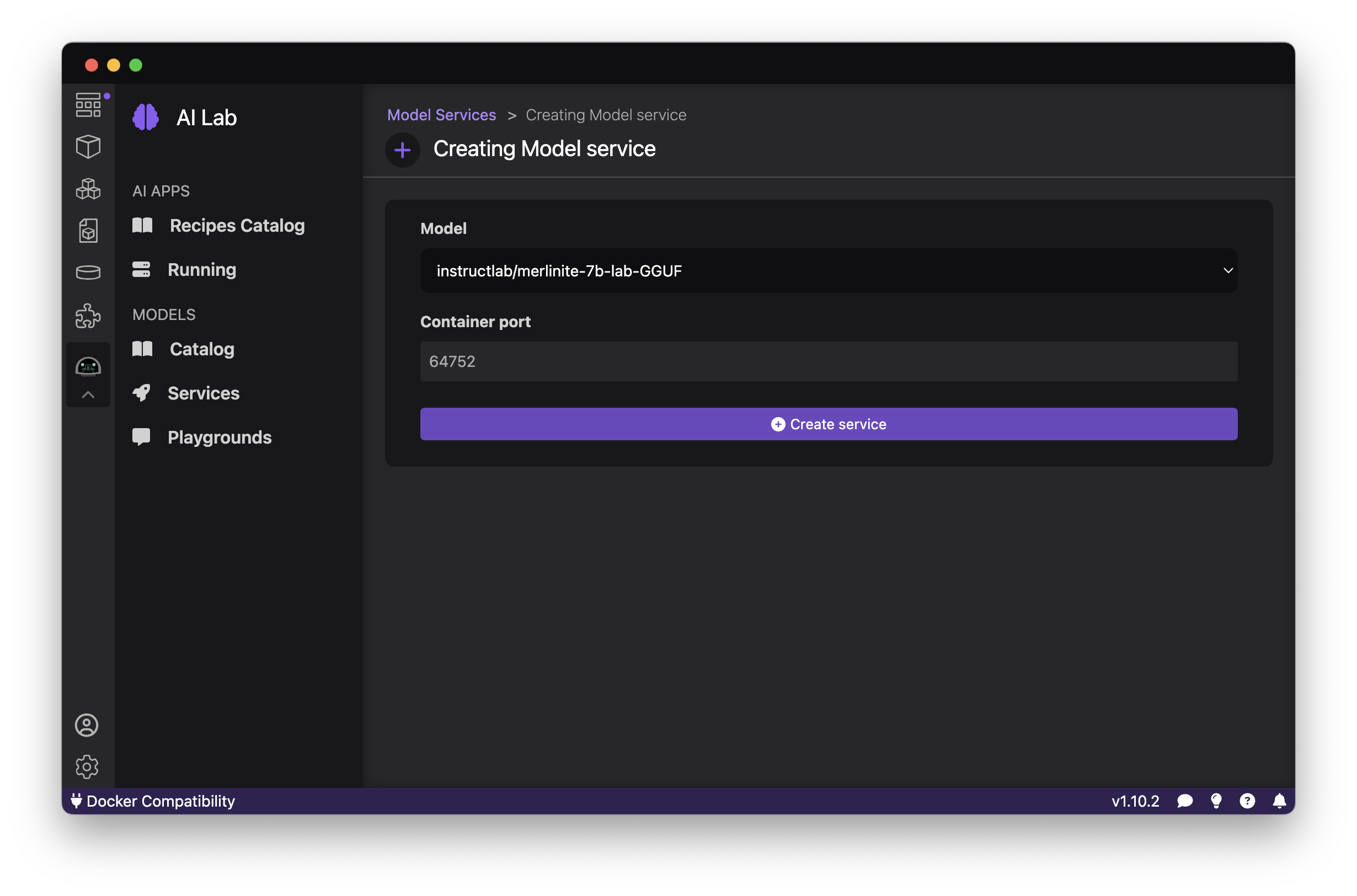
I've selected the Merlinite lab model that you learned about above already. Clicking "create service" creates the llama.ccp-based inference server for you and packs everything up in a container to use locally. Going to the "Service Details," you are presented with a UI that gives you the API endpoint for the model and some pre-generated client code you can use in various languages and tools.
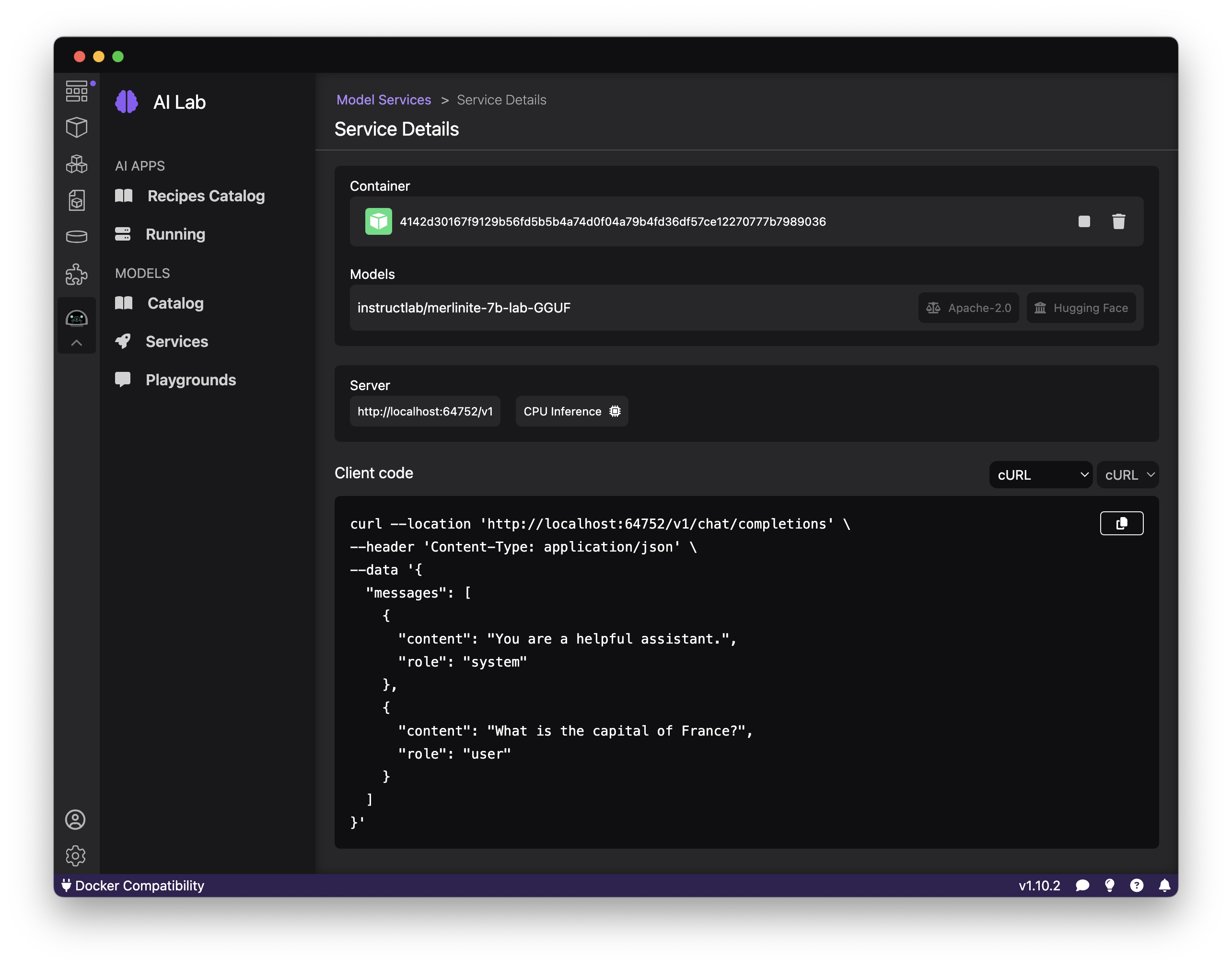
Play around with curl and use the playground to start a chat with the model directly from Podman Desktop. But in this blog post, we are going to dive deeper into how to integrate the model you just containerized and started into your application.
Quarkus and LangChain4j
Having a model run locally in a container is already pretty cool, but what we really want is to use it from our Java application - ideally from Quarkus, of course. I mentioned the OpenAI API above already, but we really do not want to handle direct API calls ourselves anymore. This is where LangChain4j comes into the picture. It provides a unified abstraction and various tools to integrate the shiny GenAI world into your Java applications. Additionally, Quarkus makes it even easier by providing a LangChain4j extension that does all the configuration and heavy lifting for you.
Let's start our AI-infused Quarkus application. I am assuming that you have the following:
- Roughly 15 minutes
- An IDE
- JDK 17+ installed with
JAVA_HOMEconfigured appropriately - Apache Maven 3.9.6
Go into your projects folder or somewhere to bootstrap a simple Quarkus project with the following Maven command:
mvn io.quarkus.platform:quarkus-maven-plugin:3.10.1:create \
-DprojectGroupId=org.acme \
-DprojectArtifactId=get-ai-started \
-Dextensions='rest,quarkus-langchain4j-openai'This will create a folder called "get-ai-started" that you need to change into. Open the project with your favorite editor and delete everything from the src/main/test folder. Yeah, I know, but I really want this to be a super simple start. Next create a Bot.java file in /src/main/java/org.acme/ with the following content:
package org.acme;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
import io.quarkiverse.langchain4j.RegisterAiService;
import jakarta.enterprise.context.SessionScoped;
@RegisterAiService()
@SessionScoped
public interface Bot {
String chat(@UserMessage String question);
}Save and open the src/main/resources/application.properties file. Just add the following two lines:
quarkus.langchain4j.openai.base-url=<MODEL_URL_FROM_PODMAN_SERVICE>
quarkus.langchain4j.openai.timeout=120sMake sure to change to the endpoint your Podman Desktop AI Lab shows you under Service Details. In the above example, it is http://localhost:64752/v1. Now open GreetingResource.java and change to the following:
package org.acme;
import io.quarkiverse.langchain4j.RegisterAiService;
import jakarta.enterprise.context.SessionScoped;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
@Path("/hello")
@RegisterAiService()
@SessionScoped
public class GreetingResource {
private final Bot bot;
public GreetingResource(Bot bot){
this.bot = bot;
}
@GET
@Produces(MediaType.TEXT_PLAIN)
public String hello() {
return bot.chat("What model are you?");
}
}You've now basically added the call to the model and the /hello resource should respond with the answer to the hard-coded question "What model are you?".
Start your application in Development Mode on the terminal:
mvn quarkus:devAnd navigate your browser of choice to http://localhost:8080/hello. Assuming that your model container is still running in Podman Desktop, you will see the answer within a few seconds in your browser:
"I am a text-based AI language model, trained by OpenAI. I am designed to assist users in various tasks and provide information based on my knowledge cutoff of September 2021."
Quarkus makes interacting with the underlying LLM super simple. If you navigate to http://localhost:8080/q/dev-ui/io.quarkiverse.langchain4j.quarkus-langchain4j-core/chat, you can access the built-in chat functionality of the Quarkus LangChain4J integration.

Wrapping Up
That's it: as simple and straightforward as you can imagine. Feel free to play around further and let me know in the comments what you'd like to learn more about next.
Opinions expressed by DZone contributors are their own.
Comments