How to Create a Real-Time Scalable Streaming App Using Apache NiFi, Apache Pulsar, and Apache Flink SQL
In this article, we'll cover how and when to use Pulsar with NiFi and Flink as you build your streaming application.
Join the DZone community and get the full member experience.
Join For Free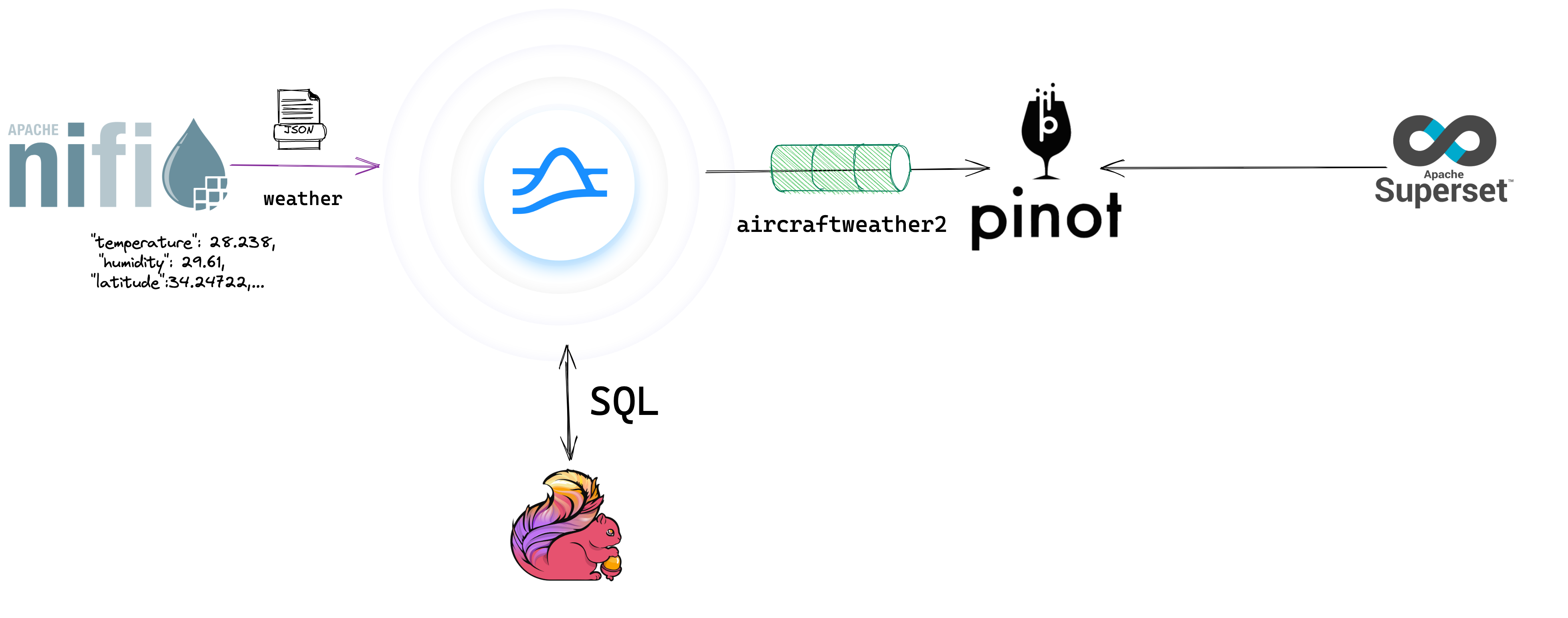
Building streaming applications can be a difficult task — often, just figuring out how to get started can be overwhelming. In this article, we'll cover how and when to use NiFi with Pulsar and Flink and how to get started. Apache NiFi, Apache Pulsar, and Apache Flink are robust, powerful open-source platforms that enable running any size application at any scale. This enables us to take our quickly developed prototype and deploy it as an unbreakable clustered application ready for internet-scale production workloads of any size.
Using a drag-and-drop tool can help reduce that difficulty and allow us to get the data flowing. By utilizing Apache NiFi, we can quickly go from ideation to data streaming as live events in our Pulsar topics. Once we have a stream, building applications via SQL becomes a much more straightforward premise. The ability to rapidly prototype, iterate, test, and repeat are critical in modern cloud applications.
We are now faced with a familiar scenario where it appears like traditional database-driven or batch applications that most data engineers and programmers use.
Before we cover how to get started with NiFi, Pulsar, and Flink, let’s discuss how and why these platforms work for real-time streaming. ChatGPT said:
Why Use Apache NiFi With Apache Pulsar and Apache Flink?
Architects and developers have many options for building real-time scalable streaming applications, so why should they utilize the combination of Apache NiFi, Apache Pulsar, and Apache Flink? The initial reason I started utilizing this combination of open-source projects is the ease of getting started. I always recommend first starting with the simplest way for anyone exploring solutions to new use cases or problems. The simplest solution to start data flowing from a source or extract is usually Apache NiFi.
Apache NiFi is a drag-and-drop tool that works on live data, so I can quickly point to my source of data and start pulling or triggering data from it. Since Apache NiFi supports hundreds of sources, often, the data I want to access is a straightforward drag-and-drop. Once the data starts flowing, I can build an interactive streaming pipeline one step at a time in real time with live data flowing. I can examine the state of that data before building the next step. With the combination of inter-step queues and data provenance, I know the current state of the data and all the previous states with their extensive metadata. In an hour or less, I can usually build the ingest, routing, transforming, and essential data enrichment. The final step of the Apache NiFi portion of our streaming application is to stream the data to Apache Pulsar utilizing the NiFi-Pulsar connector. Next in our application development process is to provide routing and additional enhancements before data is consumed from Pulsar.
Within Apache Pulsar, we can utilize Functions written in Java, Python, or Go to enrich, transfer, add schemas, and route our data in real time to other topics.
When?
Quick Criteria
| Your Data Source | Recommended Platform(s) |
JSON REST feed |
Looks like a good fit for NiFi+ |
Relational tables CDC |
Looks like a good fit for NiFi+ |
Complex ETL and Transformation |
Look at Spark + Pulsar |
Source requires joins |
Look at Flink applications |
Large batch data |
Look at native applications |
Mainframe data sources |
Look at existing applications that can send messages |
Websocket streams of data |
Looks like a good fit for NiFi+ |
Clickstream data |
Looks like a good fit for NiFi+ |
Sensor data from devices |
Just stream directly to Pulsar via MQTT. |
You may ask when I should use the combination of Apache NiFi/Apache Pulsar/Apache Flink to build my apps, and what if I only need Pulsar? That can be the case many times. Suppose you have an existing application that produces messages or events being sent to Apache Kafka, MQTT, RabbitMQ, REST, WebSockets, JMS, RPC, or RocketMQ. In that case, you can just point that program at a Pulsar cluster or rewrite to us the superior native Pulsar libraries.
After an initial prototype with NiFi, if it is too slow, you can deploy your flow on a cluster and resize with Kubernetes, expand out vertically with more RAM and CPU cores or look for solutions with my streaming advisors. The great thing about Apache NiFi is that there are many pre-built solutions, demos, examples, and articles for most use cases spanning from REST to CDC to logs to sensor processing.
If you hit a wall at any step, then perhaps Apache NiFi is not right for this data. If it is mainframe data, complex ingest rules require joins, many enrichment steps, and complex ETL or ELT. I suggest looking at custom Java code, Apache Spark, Apache Flink, or another tool.
If you don’t have an existing application, but your data requires no immediate changes and comes from a known system, perhaps you can use a native Pulsar source. Check them out at https://hub.streamnative.io/. If you need to do some routing, enrichment, and enhancement, you may want to look at Pulsar Functions which can take your raw data in that newly populated topic event at a time to do that.
If you have experience with an existing tool such as Spark and have an environment, that may be a good way for you to bring this data into the Pulsar stream. This is especially true if there are a lot of ETL steps or you are combining it with Spark ML.
There are several items you should catalog about your data sources, data types, schemas, formats, requirements, and systems before you finalize infrastructure decisions.
A series of questions should be answered. These are a few basic questions.
Is this pipeline one that requires Exactly Once semantics?
What effects would duplicate data have on your pipeline?
What are the scale in events per second, gigabytes per second, and total storage and completion requirements?
How many infrastructure resources do you have?
What is the sacrifice for speed vs. cost?
How much total storage per day?
How long do you wish to store your data stream?
Does this need to be repeatable?
Where will this run? Will it need to run in different locations, countries, availability zones, on-premise, cloud, K8, Edge...?
What does your data look like? Prepare data types, schemas, and everything you can about the source and final data. Is your data binary, image, video, audio, documents, unstructured, semi-structured, structured, normalized relational data, etc.?
What are the upstream and downstream systems?
Do NiFi, Pulsar, Flink, Spark, and other systems have native connectors or drivers for your system?
Is this data localized, and does it require translation for formatting or language?
What type of enrichment is required?
Do you require strict auditing, lineage, provenance, and data quality?
Who is using this data and how?
What team is involved? Data scientists? Data engineers? Data analysts? Programmers? Citizen streaming developers?
Is this batch-oriented?
How long will this pipeline live?
Is this time series data?
Is machine learning or deep learning part of the flow or final usage?
References
Opinions expressed by DZone contributors are their own.
Comments