Integrating Apache Spark With Drools: A Loan Approval Demo
Combine Apache Spark’s data processing with Drools’ rule engine to automate loan approvals based on credit scores, using a scalable, rule-based approach with Scala.
Join the DZone community and get the full member experience.
Join For FreeNear real-time decision-making systems are critical for modern business applications. Integrating Apache Spark (Streaming) and Drools provides scalability and flexibility, enabling efficient handling of rule-based decision-making at scale. This article showcases their integration through a loan approval system, demonstrating its architecture, implementation, and advantages.
Problem Statement
Applying numerous rules using Spark user-defined functions (UDFs) can become complex and hard to maintain due to extensive if-else logic.
Solution
Drools provides a solution through DRL files or decision tables, allowing business logic to be written in a business-friendly language. Rules can be dynamically managed and applied if included in the classpath.
Use Case
While streaming data from upstream systems, Drools enables simple decision-making based on defined rules.
Implementation Overview
This demo is implemented as a standalone program in IntelliJ for easy testing without requiring a cluster. The following library versions are used:
- Scala
- Drools
- Apache Spark
System Architecture Overview
Diagram: High-Level System Architecture
This diagram illustrates the flow of data and components involved in the system:
- Input data: Loan applications.
- Apache Spark: Ingests and processes data in a distributed manner.
- Drools engine: Applies business rules to each application.
- Output: Approved or rejected applications.
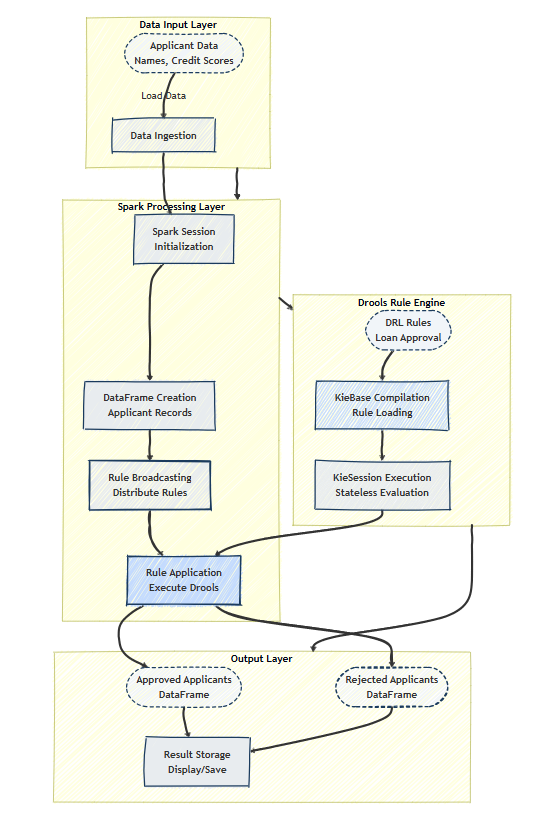
Workflow
- Data ingestion: Applicant data is loaded into Spark as a DataFrame.
- Rule execution: Spark partitions the data, and Drools applies rules on each partition.
- Result generation: Applications are classified as approved or rejected based on the rules.
Step 1: Define the Model
A Scala case class ApplicantForLoan represents loan applicant details, including credit score and requested amount. Below is the code:
ApplicantForLoan.scala
package com.droolsplay
case class ApplicantForLoan(id: Int, firstName: String, lastName: String, requestAmount: Int, creditScore: Int) extends Serializable {
private var approved = false
def getFirstName: String = firstName
def getLastName: String = lastName
def getId: Int = id
def getRequestAmount: Int = requestAmount
def getCreditScore: Int = creditScore
def isApproved: Boolean = approved
def setApproved(_approved: Boolean): Unit = {
approved = _approved
}
}Step 2: Define the Drools Rule
A self-explanatory DRL file (loanApproval.drl) defines the rule for loan approval based on a credit score:
package com.droolsplay;
/**
* @author : Ram Ghadiyaram
*/
import com.droolsplay.ApplicantForLoan
rule "Approve_Good_Credit"
when
a: ApplicantForLoan(creditScore >= 680)
then
a.setApproved(true);
endStep 3: Configure Drools Knowledge Base
Drools 6 supports declarative configuration of the knowledge base and session in a kmodule.xml file:
<?xml version="1.0" encoding="UTF-8"?>
<kmodule xmlns="http://jboss.org/kie/6.0.0/kmodule">
<kbase name="AuditKBase" default="true" packages="com.droolsplay">
<ksession name="AuditKSession" type="stateless" default="true"/>
</kbase>
</kmodule>A KieBase is a repository of knowledge definitions (rules, processes, functions, and type models) but does not contain data. Sessions are created from the KieBase to insert data and start processes. Creating a KieBase is resource-intensive, but session creation is lightweight, so caching the KieBase is recommended. The KieContainer automatically handles this caching.
Step 4: Create a Utility for Rule Application
The DroolUtil object handles loading and applying rules, and SparkSessionSingleton ensures a single Spark session:
package com.droolsplay.util
import com.droolsplay.ApplicantForLoan
import org.apache.log4j.Logger
import org.apache.spark.internal.Logging
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.kie.api.{KieBase, KieServices}
import org.kie.internal.command.CommandFactory
/**
* @author : Ram Ghadiyaram
*/
object DroolUtil extends Logging {
/**
* loadRules.
*
* @return KieBase
*/
def loadRules: KieBase = {
val kieServices = KieServices.Factory.get
val kieContainer = kieServices.getKieClasspathContainer
kieContainer.getKieBase
}
/**
* applyRules.
*
* @param base
* @param applicant
* @return ApplicantForLoan
*/
def applyRules(base: KieBase, applicant: ApplicantForLoan): ApplicantForLoan = {
val session = base.newStatelessKieSession
session.execute(CommandFactory.newInsert(applicant))
logTrace("applyrules ->" + applicant)
applicant
}
/**
* checkDFSize
*
* @param spark
* @param applicantsDS
* @return
*/
def checkDFSize(spark: SparkSession, applicantsDS: DataFrame) = {
applicantsDS.cache.foreach(x => x)
val catalyst_plan = applicantsDS.queryExecution.logical
// just to check dataframe size
val df_size_in_bytes = spark.sessionState.executePlan(
catalyst_plan).optimizedPlan.stats.sizeInBytes.toLong
df_size_in_bytes
}
}
/** Lazily instantiated singleton instance of SparkSession */
object SparkSessionSingleton extends Logging {
val logger = Logger.getLogger(this.getClass.getName)
@transient private var instance: SparkSession = _
def getInstance(): SparkSession = {
logDebug(" instance " + instance)
if (instance == null) {
instance = SparkSession
.builder
.config("spark.master", "local") //.config("spark.eventLog.enabled", "true")
.appName("AppDroolsPlayGroundWithSpark")
.getOrCreate()
}
instance
}
}Step 5: Implement the Spark Driver
The main Spark driver (App) processes the input data and applies the rules:
package com.droolsplay
import com.droolsplay.util.DroolUtil._
import com.droolsplay.util.SparkSessionSingleton
import org.apache.spark.SparkConf
import org.apache.spark.internal.Logging
import org.apache.spark.sql.functions._
/**
* @author : Ram Ghadiyaram
*/
object App extends Logging {
def main(args: Array[String]): Unit = {
// prepare some funny input data
val inputData = Seq(
ApplicantForLoan(1, "Ram", "Ghadiyaram", 680, 680),
ApplicantForLoan(2, "Mohd", "Ismail", 12000, 679),
ApplicantForLoan(3, "Phani", "Ramavajjala", 100, 600),
ApplicantForLoan(4, "Trump", "Donald", 1000000, 788),
ApplicantForLoan(5, "Nick", "Suizo", 10, 788),
ApplicantForLoan(7, "Sreenath", "Mamilla", 10, 788),
ApplicantForLoan(8, "Naveed", "Farroqui", 10, 788),
ApplicantForLoan(9, "Ashish", "Anand", 1000, 788),
ApplicantForLoan(10, "Vasudha", "Nanduri", 1001, 788),
ApplicantForLoan(11, "Tathagatha", "das", 1002, 788),
ApplicantForLoan(12, "Sean", "Owen", 1003, 788),
ApplicantForLoan(13, "Sandy", "Raza", 1004, 788),
ApplicantForLoan(14, "Holden", "Karau", 1005, 788),
ApplicantForLoan(15, "Gobinathan", "SP", 1005, 7),
ApplicantForLoan(16, "Arindam", "SenGupta", 1005, 670),
ApplicantForLoan(17, "NIKHIL", "POTLAPALLY", 100, 670),
ApplicantForLoan(18, "Phanindra", "Ramavojjala", 100, 671)
)
val spark = SparkSessionSingleton.getInstance()
// load drl file using loadRules from the DroolUtil class shown above...
val rules = loadRules
/*** broadcast all the rules using broadcast variable ***/
val broadcastRules = spark.sparkContext.broadcast(rules)
val applicants = spark.sparkContext.parallelize(inputData)
logInfo("list of all applicants " + applicants.getClass.getName)
import spark.implicits._
val applicantsDS = applicants.toDF()
applicantsDS.show(false)
val df_size_in_bytes: Long = checkDFSize(spark, applicantsDS)
logInfo("byteCountToDisplaySize - df_size_in_bytes " + df_size_in_bytes)
logInfo(applicantsDS.rdd.toDebugString)
val approvedguys = applicants.map {
x => {
logDebug(x.toString)
applyRules(broadcastRules.value, x)
}
}.filter((a: ApplicantForLoan) => (a.isApproved == true))
logInfo("approvedguys " + approvedguys.getClass.getName)
approvedguys.toDS.withColumn("Remarks", lit("Good Going!! your credit score =>680 check your score in https://www.creditkarma.com")).show(false)
var numApproved: Long = approvedguys.count
logInfo("Number of applicants approved: " + numApproved)
/** **
* another way to do it with dataframes just an example not required to execute this code above rdd applicants
* is sufficient to get isApproved == false
*/
val notApprovedguys = applicantsDS.rdd.map { row =>
applyRules(broadcastRules.value,
ApplicantForLoan(
row.getAs[Int]("id"),
row.getAs[String]("firstName"),
row.getAs[String]("lastName"),
row.getAs[Int]("requestAmount"),
row.getAs[Int]("creditScore"))
)
}.filter((a: ApplicantForLoan) => (a.isApproved == false))
logInfo("notApprovedguys " + notApprovedguys.getClass.getName)
notApprovedguys.toDS().withColumn("Remarks", lit("credit score <680 Need to improve your credit history!!! check your score : https://www.creditkarma.com")).show(false)
val numNotApproved: Long = notApprovedguys.count
logInfo("Number of applicants NOT approved: " + numNotApproved)
}
}The results of applying the Drools rules to the input data are presented below in a table format, showing the original DataFrame and the outcomes for both approved and non-approved applicants.
Original DataFrame
The original DataFrame contained 18 records with dummy data, as shown below:
|
id |
firstName |
lastName |
requestAmount |
creditScore |
|---|---|---|---|---|
|
1 |
Ram |
Ghadiyaram |
680 |
680 |
|
2 |
Mohd |
Ismail |
12000 |
679 |
|
3 |
Phani |
Ramavajjala |
100 |
600 |
|
4 |
Trump |
Donald |
1000000 |
788 |
|
5 |
Nick |
Suizo |
10 |
788 |
|
7 |
Sreenath |
Mamilla |
10 |
788 |
|
8 |
Naveed |
Farroqui |
10 |
788 |
|
9 |
Ashish |
Anand |
1000 |
788 |
|
10 |
Vasudha |
Nanduri |
1001 |
788 |
|
11 |
Tathagatha |
das |
1002 |
788 |
|
12 |
Sean |
Owen |
1003 |
788 |
|
13 |
Sandy |
Raza |
1004 |
788 |
|
14 |
Holden |
Karau |
1005 |
788 |
|
15 |
Gobinathan |
SP |
1005 |
7 |
|
16 |
Arindam |
SenGupta |
1005 |
670 |
|
17 |
NIKHIL |
POTLAPALLY |
100 |
670 |
|
18 |
Phanindra |
Ramavojjala |
100 |
671 |
Approved Applicants
After applying the DRL rule (creditScore >= 680), 11 applicants were approved. The log output indicates: 18/11/03 00:15:38 INFO App: Number of applicants approved: 11. The approved applicants are:
|
id |
firstName |
lastName |
requestAmount |
creditScore |
Remarks |
|---|---|---|---|---|---|
|
1 |
Ram |
Ghadiyaram |
680 |
680 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
|
4 |
Trump |
Donald |
1000000 |
788 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
|
5 |
Nick |
Suizo |
10 |
788 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
|
7 |
Sreenath |
Mamilla |
10 |
788 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
|
8 |
Naveed |
Farroqui |
10 |
788 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
|
9 |
Ashish |
Anand |
1000 |
788 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
|
10 |
Vasudha |
Nanduri |
1001 |
788 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
|
11 |
Tathagatha |
das |
1002 |
788 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
|
12 |
Sean |
Owen |
1003 |
788 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
|
13 |
Sandy |
Raza |
1004 |
788 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
|
14 |
Holden |
Karau |
1005 |
788 |
Good Going!! your credit score =>680 check your score in https://www.creditkarma.com |
Non-Approved Applicants
Six applicants did not meet the rule criteria (creditScore < 680). The log output indicates: 18/11/03 00:15:39 INFO App: Number of applicants NOT approved: 6. The not approved applicants are:
|
id |
firstName |
lastName |
requestAmount |
creditScore |
Remarks |
|---|---|---|---|---|---|
|
2 |
Mohd |
Ismail |
12000 |
679 |
credit score <680 Need to improve your credit history!!! check your score : https://www.creditkarma.com |
|
3 |
Phani |
Ramavajjala |
100 |
600 |
credit score <680 Need to improve your credit history!!! check your score : https://www.creditkarma.com |
|
15 |
Gobinathan |
SP |
1005 |
7 |
credit score <680 Need to improve your credit history!!! check your score : https://www.creditkarma.com |
|
16 |
Arindam |
SenGupta |
1005 |
670 |
credit score <680 Need to improve your credit history!!! check your score : https://www.creditkarma.com |
|
17 |
NIKHIL |
POTLAPALLY |
100 |
670 |
credit score <680 Need to improve your credit history!!! check your score : https://www.creditkarma.com |
|
18 |
Phanindra |
Ramavojjala |
100 |
671 |
credit score <680 Need to improve your credit history!!! check your score : https://www.creditkarma.com |
Applications
This approach is applicable across various domains, including but not limited to the following. It can also be utilized in Spark Streaming applications to process data in real-time or near real-time:
- Finance: Trade analysis, fraud detection, loan approval, or rejection
- Airlines: Operations monitoring
- Healthcare: Claims processing, patient monitoring, Cancer report evaluation, drug evaluation based on symptoms
- Energy and Telecommunications: Outage detection
Note: In this project, the DRL file is stored in resources/META-INF. In real-world applications, rules are often stored in databases, allowing dynamic updates without redeploying the application.
Conclusion
This demo illustrates how Apache Spark and Drools can be integrated to streamline rule-based decision-making, such as loan approvals based on credit scores. By leveraging Drools' rule engine and Spark's data processing capabilities, complex business logic can be managed efficiently.
For the complete code and setup, refer to my GitHub repository, which has been found to be useful and archived in the Arctic Code Vault (code preserved for future generations).
Disclaimer: The input data, result names, and URL are indicated for illustrative purposes only. I don't affiliate with any person or organization.
Published at DZone with permission of Ram Ghadiyaram. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments