Is Claude 3 Outperforming GPT-4?
Does Claude 3 beat GPT-4? Check out this blog on which AI model has the capability to determine performance for every user in daily life.
Join the DZone community and get the full member experience.
Join For FreeIn the rapidly evolving world of large language models (LLMs), a new challenger has emerged that claims to outperform the reigning champion, OpenAI's GPT-4. Anthropic, a relatively new player in the field of artificial intelligence, has recently announced the release of Claude 3, a powerful language model that comes in three different sizes: Haiku, Sonnet, and Opus.
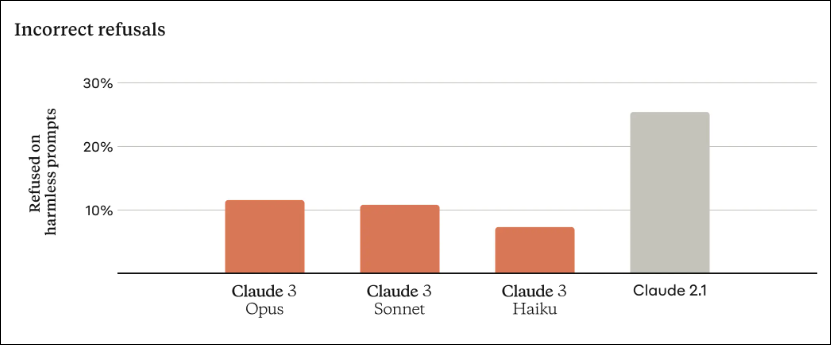
Compared to previous models, the new Claude 3 model displays enhanced contextual understanding that ultimately results in fewer refusals (as shown in the above image). The company claims that the Claude 3 Opus model rivals or even surpasses GPT-4 considering performance across various benchmarks. Experts engage in lively debates regarding the possible superiority of Claude 3 over GPT-4 as the pre-eminent language model on the market.
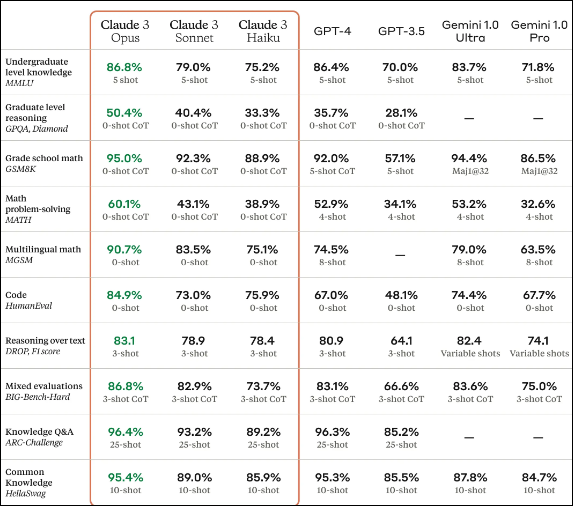
This comprehensive analysis deals with both models' strengths, limitations, and real-world applications across diverse benchmarks.
Performance: A Closer Look
Benchmarks and Scores
Anthropic cites benchmark scores to support its claim that the Claude 3 Opus model outperforms GPT-4. Anthropic cites benchmark scores to support its claim that the Claude 3 Opus model outperforms GPT-4. For instance, in the GSM8K benchmark, which evaluates language models on their ability to understand and reason about natural language, the Claude 3 Opus model notably outperformed GPT-4, securing a score of 95.0% compared to GPT-4's 92.0%.
However, it's important to note that this comparison was made against the default GPT-4 model, not the advanced GPT-4 Turbo variant. When GPT-4 Turbo is factored into the equation, the tables turn: in the same GSM8K test, GPT-4 Turbo scored an impressive 95.3%, edging out the Claude 3 Opus model.
Similar to GPT-4V, Claude 3 also comes with Vision support and also creates benchmarks across, multilingual understanding, reasoning, and so on. There are three models included in this Claude 3’s family: i.e. Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku. Sonnet is one of three multi-modal models released by Anthropic in text-only version and provides 2x the speed of Claude 2 models for most workloads. Claude 3 Haiku is the fastest and cheapest model that can easily process a 10,000-token research paper in under 3 seconds whereas Opus delivers amazing outcomes on evaluations like GPQA, MMLU, and MMMU, showing fluency on the most difficult tasks like human-level comprehension.
Input/Output Variety
One area where GPT-4 holds a clear advantage is its ability to process a wide range of input and output formats. GPT-4's capabilities encompass understanding various forms of data, including text, code, visuals, and audio inputs. It generates precise outputs by comprehending and combining this diverse information. Additionally, the GPT-4V variant can produce novel and distinctive images by analyzing textual or visual prompts, making it a versatile tool for professionals in fields necessitating visual content creation.
In contrast, the Claude 3 model is limited to processing textual and visual inputs, generating only textual outputs. While it can extract insights from images, and read graphs, and charts, it cannot produce visual outputs like GPT-4V. Furthermore, the Claude 3 Sonnet model, while more advanced than GPT-3.5, is still weaker than GPT-4 in terms of overall capabilities.
Prompt Following and Task Completion
Both models demonstrate impressive capabilities when following prompts and completing tasks but with slight differences. The Claude 3 Opus model has more advanced prompt-following skills than GPT-4, generating 10 logical outputs by following a given prompt, while GPT-4 can only generate 9. However, the Claude 3 Sonnet model lags, producing only 7 logical sentences in the same test.
This suggests that while the top-tier Claude 3 Opus excels at prompt following, the more accessible Sonnet model falls short compared to GPT-4. Additionally, GPT-4's performance in task completion and reasoning may vary depending on the specific task and context.
Accessibility and Cost
Regarding accessibility and cost, GPT-4 has a slight edge over Claude 3. While OpenAI offers free access to the GPT-3.5 model, accessing GPT-4 requires an OpenAI Plus subscription, which involves costs per month. This subscription grants users access to the GPT-4 model and its advanced features, such as custom GPTs and web search capabilities.
On the other hand, to experience the Claude 3 Sonnet model, users simply need to create an account on Anthropic's official web chatbot interface, which is available in 159 countries. However, to access the more powerful Claude 3 Opus model, users must have a paid Claude Pro subscription from Anthropic.
The Verdict: A Nuanced Comparison
Anthropic's Claude 3 Opus model and OpenAI's GPT-4 are powerful language models with distinct strengths. While Anthropic claims that Claude 3 Opus outperforms GPT-4 in certain tasks, the introduction of GPT-4 Turbo complicates the comparison. GPT-4 Turbo seems to have an overall edge, scoring higher on benchmarks like GSM8K. However, Claude 3 Opus excels at prompt following, generating more logical outputs when given prompts. The choice between the two models may also depend on accessibility and cost factors, with Claude 3 offering more affordable options for accessing its lower-tier models.
In terms of overall performance, GPT-4 Turbo appears to have a slight advantage over Claude 3 Opus. It achieves higher scores on several benchmarks designed to test language models' capabilities in various tasks. These benchmarks evaluate factors like coherence, factual accuracy, and reasoning abilities. However, it's important to note that no single benchmark can provide a complete picture of a model's performance, and different benchmarks may favor different strengths.
On the other hand, Claude 3 Opus stands out in its ability to follow prompts more closely and generate outputs that are more logically consistent with the given instructions. This can be particularly valuable in scenarios where precise adherence to prompts is crucial, such as in task-specific applications.
Ultimately, the decision between Claude 3 and GPT-4 will depend on the specific needs and priorities of the user.
The Future of Language Models
As the field of artificial intelligence continues to evolve rapidly, the competition between these powerful language models will likely intensify. While Claude 3 has undoubtedly made a strong entry into the market, GPT-4's versatility and performance make it a formidable opponent.
The continuous progress in language models and AI assistants holds immense advantages for users. As these technologies become more widely accessible, they possess the capability to change various sectors and empower individuals as well as businesses.
Irrespective of the model that ultimately leads the pack, one certainty remains: the era of large language models has arrived, and their influence on our daily lives and professional endeavors will only intensify.
Conclusion
The battle between Claude 3 and GPT-4 is just the beginning of what promises to be an ongoing arms race in the development of increasingly sophisticated and capable large language models. The world of artificial intelligence is continuously advancing as companies like Anthropic and OpenAI bring innovation. However, making definitive comparisons or superiority claims requires careful consideration. While benchmarks offer valuable insights, real-world applications may reveal complexities that these metrics cannot capture fully. Moreover, the scenario shifts rapidly with new advancements like GPT-4 Turbo quickly altering the playing field. A balanced perspective is essential when evaluating these complex language models.
Published at DZone with permission of Nishant Bijani. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments