Keeping Two Multi-Master Databases Aligned With a Vector Clock
In this article, learn about an experience in keeping two different databases aligned with two different technologies by using an application-level solution.
Join the DZone community and get the full member experience.
Join For FreeIn today's tech environment, there is a frequent requirement to synchronize applications. This need often arises during technology upgrades, where the goal is to transition a database and its processes from an outdated legacy system to a newer technology. In such scenarios, it's typically required to allow both applications to coexist for a period of time. Sometimes both applications, together with their own databases, must be maintained as masters because dismantling the processes dependent on the legacy one is not viable. Consequently, specific solutions for keeping the two master databases aligned are essential, ensuring that operations on one database are mirrored on the other one, and vice versa.
In this article, we discuss a real case we dealt with by abstracting away from several technical details, but focusing on those decisions that shape the structure of our solution.
The Scenario
The scenario we dealt with was about a technology migration of an application upon which quite all the processes of the company depend. One of the main business constraints was related to the fact that the old application would not be decommissioned at the end of the development, but would continue to coexist with the new one for a long time, allowing for a progressive migration of all the processes to the new version.
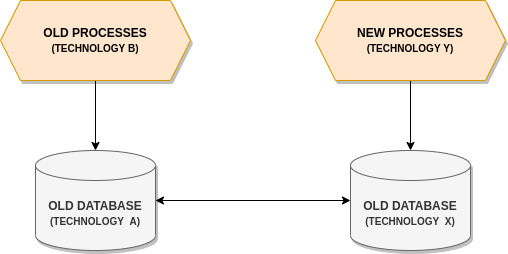
The consequence of this fact was that the two databases would both become master and they would require to be kept aligned.
Here is a list of the main tech constraints that shaped our decision:
- The two databases handle the same dataset but with different schemas: for example, a customer on one database is represented using a different number of tables and columns compared to the other.
- There is no CDC (Change Data Capture) product available for getting the databases in sync.
- The legacy application can synchronize itself only via asynchronous messages.
- If one of the two applications goes down, the other one must still be available.
We approached the solution by making the following decisions:
- We decided to use a bi-directional asynchronous message communication managed at the application level for exchanging data between the two masters and to implement the same synchronizing algorithm on both sides.
- Each master publishes an alignment event that carries the whole set of data aligned with the last modification.
- We exploit a vector clock algorithm for processing the events on both sides.
Asynchronous Communication and Common Algorithm
Two Kafka queues have been used for exchanging messages in both directions. The Avro schema has been kept identical on both queues, so the events are also identical in the format.
Such a decision permitted us to create an abstraction layer in common with the two masters that are independent of the used technologies, but it is only dependent on the alignment algorithm and the shared data model used for the events.
The main advantages we wanted to focus on are:
- Keeping the alignment module separated from the implementation of the two masters, so the design can be addressed separately from them.
- Permitting the two masters to work without being dependent on the other. If one master stops to work, the other can continue.
- Relying everything to an algorithm means not depending on a specific technology, but only on its implementation, which can be tested with special test suites. In the long run, this results in a stable solution with little susceptibility to errors.
The price to pay is the replication of the algorithm on both applications.
Establishing Order Among Messages
A pivotal requirement in aligning databases is a mechanism that enables the ordering of messages irrespective of the system in which they were generated. This ordering mechanism is crucial for maintaining the integrity and consistency of data across distributed environments. Two types of ordering exist: total and partial. Total ordering allows for the sequential arrangement of all generated messages, offering a comprehensive view of events across the system. On the other hand, partial ordering facilitates the sequential arrangement of only a subset of messages, providing flexibility in how events are correlated.
We evaluated different solutions for achieving order among messages:
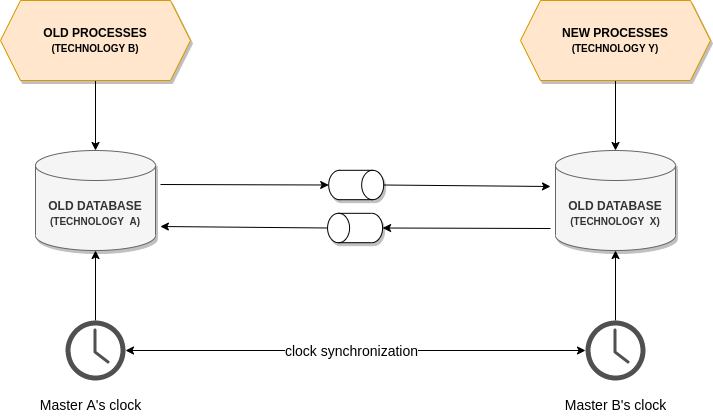
Server Clock
Utilizing the server's clock as a basis for ordering can be straightforward but raises questions about which server's clock to use. Each application has its own infrastructure and components. Which are the components used as a reference for the clocks? How do you keep them synchronized? In cases of misalignment, determining the course of action becomes crucial and the order can be compromised.
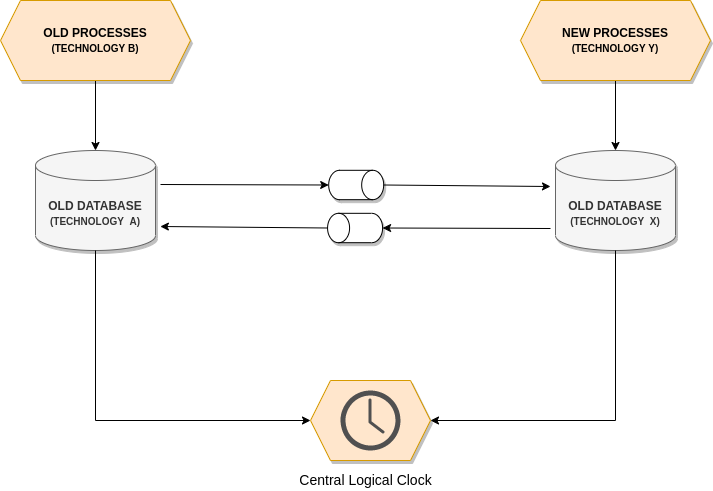
A Dedicated Centralized Logical Clock
A centralized logical clock presents an alternative by providing a singular reference point for time across the system. However, this centralization can introduce bottlenecks and points of failure, making it less ideal for highly distributed or scalable systems.
Distributed Logical Clock
Distributed logical clocks, such as vector clocks, offer a solution that allows for both total and partial ordering without relying on a single point of failure. This approach enables each part of the system to maintain its own clock, with mechanisms in place to update these clocks based on the arrival of new messages or data changes. Vector clocks are particularly suitable for managing the complexities of distributed systems, offering a way to resolve conflicts and synchronize data effectively.
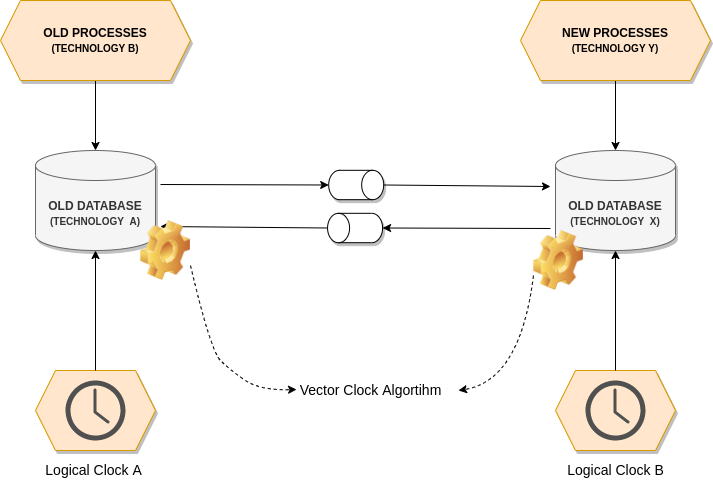
Vector Clocks: How They Work
For each record of the database, each system keeps its own internal logic clock together with the clock of the other database received from the alignment queue. In the following diagram, they are represented by columns Clock A and Clock B.
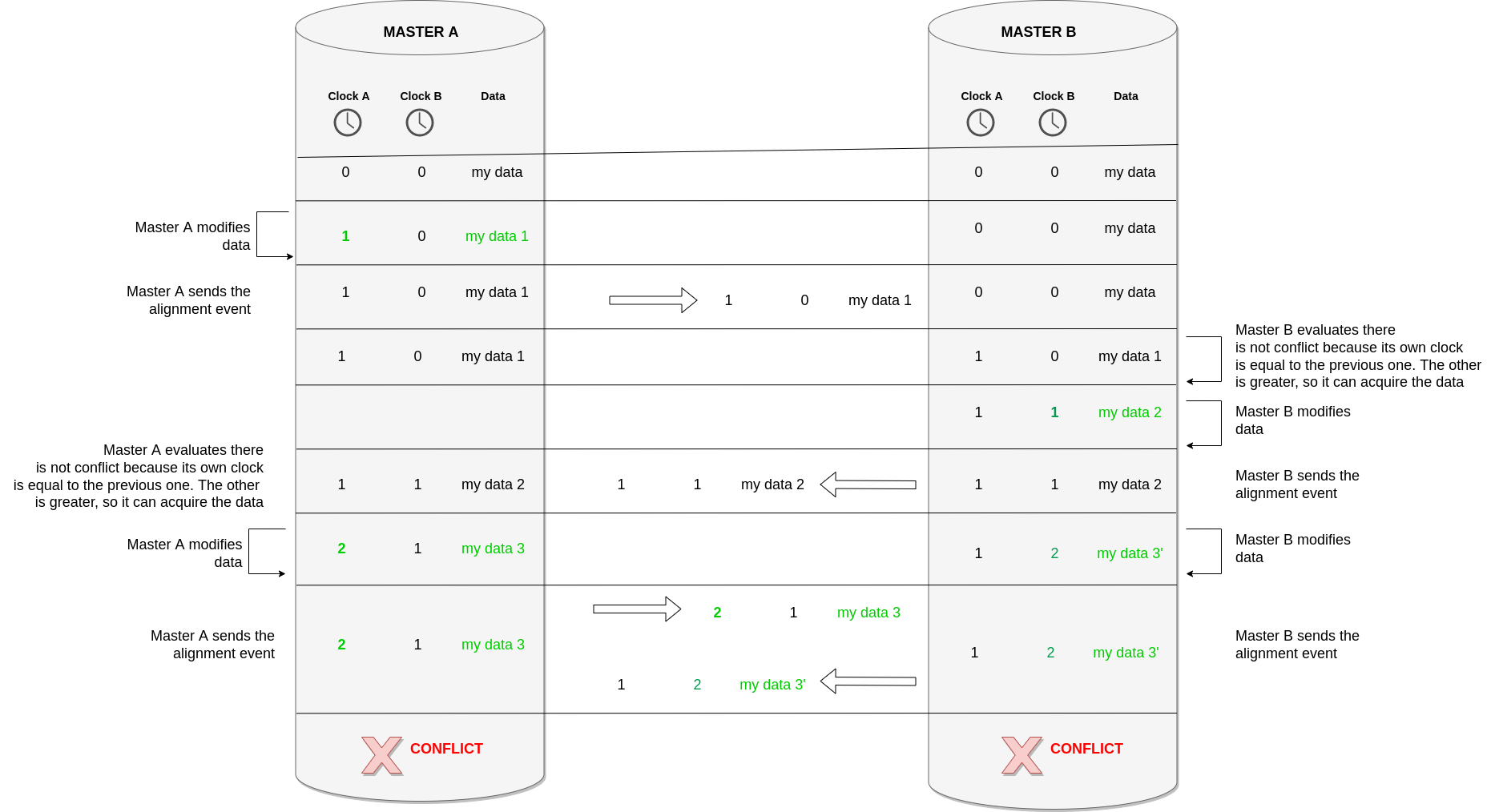
In the example, Master A modifies a record and increases the value of its own Clock A. Master B receives the record and compares the two clocks. Clock B is 0 and it is equal, whereas Clock A has been increased; thus, Master B accepts the message and overwrites its own record by aligning it with that of Master A. In the following, Master B performs a similar modification on the same record, increasing its own clock Clock B. Master A will receive the message and since Clock A is the same, it can accept the message by aligning the record.
There is the possibility of a conflict when a modification is performed concurrently on the same record in both systems. In this particular case, both the systems receive an alignment message where their own clock is minor w.r.t. to what is stored at that moment. Although this scenario could be considered rare, we need to define how to resolve a conflict. There could be different solutions: for example, we could decide that in case of conflict, one of the two masters always wins, which means it is "more master" than the other. Or, as we decided, we used timestamps for defining the "last" record. We are aware that using timestamps for defining ordering can be very problematic, but the probability of a conflict (i.e., an update on the same data occurring on both systems in a short period of time) was considered very low (under 0,1%). In this scenario, also the event timestamp must be sent in the alignment message.
Conclusions
In this article, we report our experience in keeping two different databases aligned with two different technologies by using an application-level solution. The core of the solution is the usage of asynchronous communication together with a solid algorithm that guarantees determinism in the alignment.
Such a solution works, even if it requires efforts in modifying the databases and all the writing queries for managing the vector clocks atomically, and it requires also the duplication of the algorithm on both sides.
Opinions expressed by DZone contributors are their own.
Comments