Enterprise LLM Architecture Patterns, From RAG to Agentic Systems
A practical guide to 11 proven LLM architecture patterns, with real-world examples for building scalable, trustworthy, production-ready AI systems.
Join the DZone community and get the full member experience.
Join For FreeLarge language models (LLMs) have rapidly moved from experimentation to production across enterprises, startups, and regulated industries. In this article, I present a set of 11 core LLM architecture patterns that have emerged as industry standards. These patterns are not mutually exclusive.
In practice, high-quality LLM applications combine multiple patterns to achieve robustness, observability, and governance readiness.
Each pattern is explained in simple terms, supported by practical examples, and aligned with real deployment constraints such as hallucination control, feedback loops, workflow orchestration, and compliance.
These patterns are intended for architects, engineers, and decision-makers building production-grade AI systems.
Let’s start.
1. Best-of-Breed Retrieval-Augmented Generation (RAG) Architecture
Retrieval-Augmented Generation (RAG) is the leading pattern for building fact-grounded, scalable, and reliable LLM applications. It combines the generative power of large language models with real-time retrieval from external knowledge sources, ensuring responses are accurate, up to date, and traceable.
Key Features
- Grounds LLM outputs in external, verifiable data
- Reduces hallucinations and improves trustworthiness
- Supports citations and source attribution
- Enables continuous improvement through feedback loops
- Scalable and modular for enterprise deployments
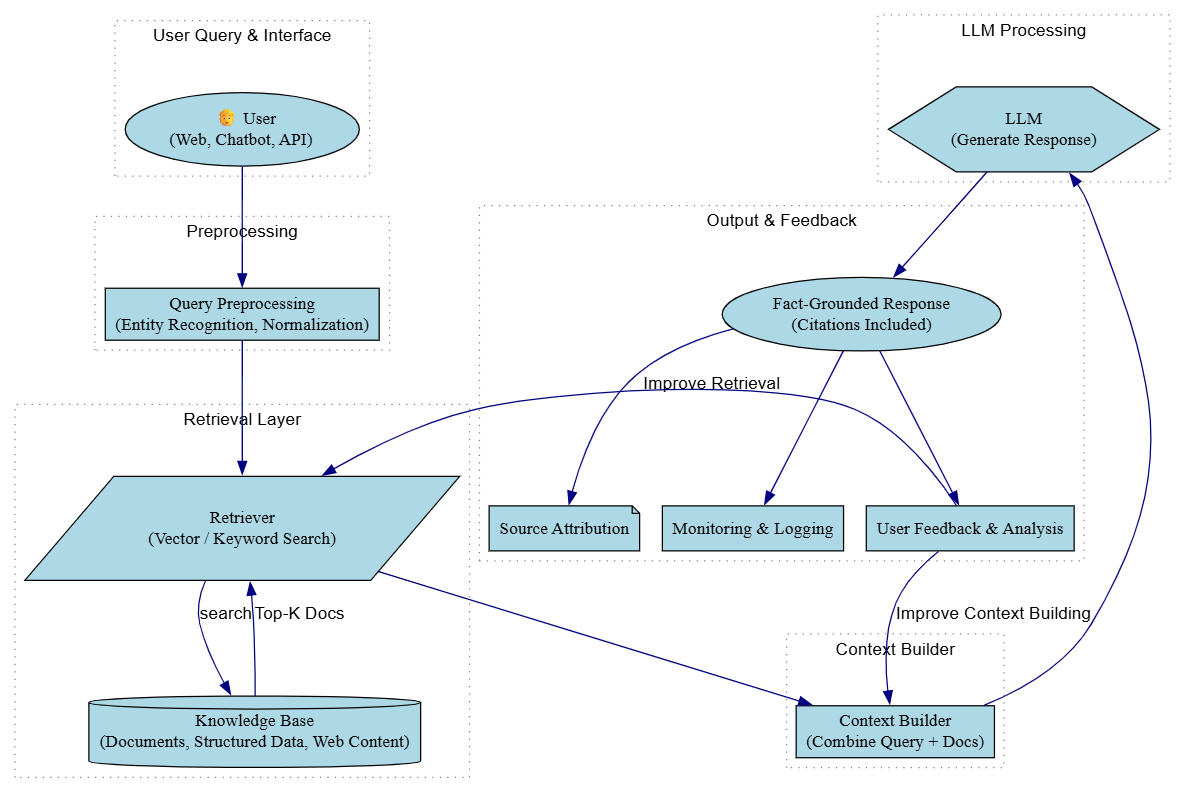
Step-by-Step Architecture Explanation
- User Query & Interface: The user submits a question or request via a web UI, chatbot, or API.
- Query Preprocessing: The system normalizes the query, performs entity recognition, and prepares it for retrieval.
- Retriever: Uses semantic search (vector database) or keyword search to find the most relevant documents or passages.
- Knowledge Base: Stores source documents, structured data, or web content (internal or external).
- Relevant Documents/Passages: The retriever returns the most relevant content.
- Context Builder: Combines the user query and retrieved documents into a single context window for the LLM.
- LLM: Generates a response grounded in the retrieved facts.
- Fact-Grounded Response: Returns the answer to the user, ideally with citations.
- Source Attribution: Provides references to the documents used, increasing trust and transparency.
- Monitoring & Logging: Captures queries, retrievals, and responses for observability, compliance, and debugging.
- User Feedback & Analysis: Users can rate or correct responses; feedback is analyzed to improve retrieval and context construction (e.g., retraining embeddings, prompt tuning).
- Feedback Loops: Feedback updates embeddings, prompts, and retrieval strategies for continuous improvement.
Although there are many possible use cases, this represents the simplest and most common RAG implementation.
Example: Medical Assistant
A doctor asks: “What are the latest guidelines for treating hypertension?”
- The query is preprocessed for medical entities such as “hypertension” or “high blood pressure.”
- The retriever searches a medical database containing clinical guidelines.
- The most recent documents are retrieved and combined with the query.
- The LLM generates a concise summary and cites official source documents.
- The doctor provides feedback (e.g., “missing pediatric guidelines”), which the system uses to refine future retrieval and context building.
2. Prompt Engineering (Zero-shot, One-shot, Few-shot, Chain-of-Thought)
Prompt engineering defines how tasks are communicated to the LLM. While many variants exist, the following are the most important.
Zero-shot Prompting
The model performs a task without any examples, relying solely on pre-trained knowledge.
Example:
Translate this text to French.
One-shot Prompting
A single example of the desired input-output pair is provided to guide the model.
Example:
Translate the following word from English to Spanish.
Example: “House” → “Casa”
Now translate “Apple” →
Answer: Manzana
Few-shot Prompting
A small number of examples (a "few shots") of the desired input-output behavior are included to clarify the task.
Example:
Classify the sentiment as positive, negative, or neutral.
- Text: The product is terrible.
Sentiment: Negative - Text: I think the vacation was okay.
Sentiment: Neutral - Text: The weather is beautiful today.
Sentiment:
Answer: Positive
Chain-of-Thought (CoT) Prompting
Encourages the model to break down complex problems and show its step-by-step reasoning. You can initiate this by simply adding a phrase like "Let's think step by step" to the prompt.
CoT prompts the LLM to reason step-by-step, making its logic explicit and verifiable.
Example:
A math tutor asks: What is 12 × (3 + 4)?
LLM Response:
First, calculate 3 + 4 = 7.
Then, 12 × 7 = 84.
The answer is 84.
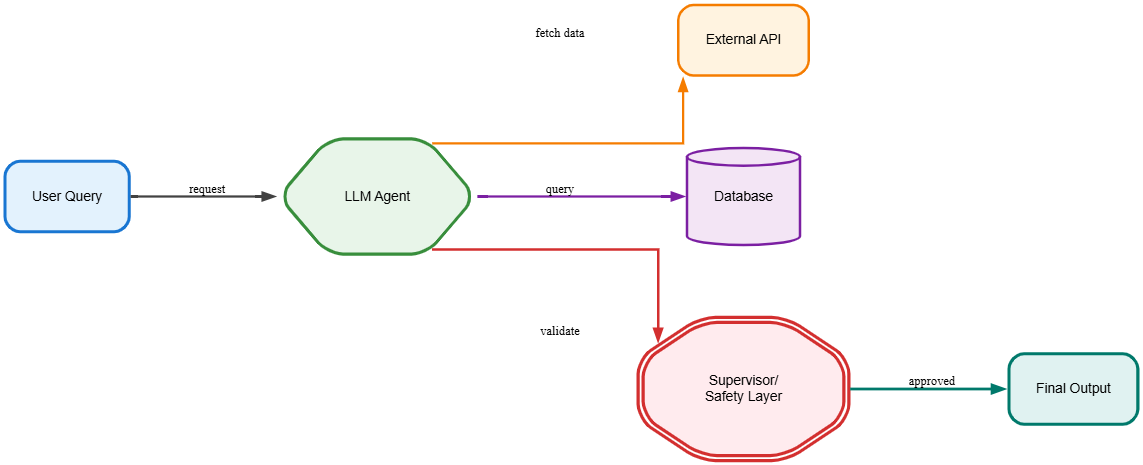
3. Agent-Based Interaction
Explanation:
The LLM acts as an agent that dynamically calls APIs, databases, or tools, often with a supervisory layer for safety.
Example:
A travel assistant books flights using airline APIs, checks weather conditions, and confirms bookings with the user.
4. Few-shot and Zero-shot Prompting
Explanation:
- Few-shot: The prompt includes examples to guide the LLM.
- Zero-shot: The model receives only instructions, relying on its pre-trained knowledge.
Example:
- Few-shot: Translate “Hello” to French. Example: “Goodbye” → “Au revoir.” Now, “Hello” →
- Zero-shot: Translate “Hello” to French.
5. Workflow Automation
Explanation:
LLMs orchestrate multi-step processes, often integrating with external workflow engines.
Example:
An LLM drafts a blog post, routes it for review, and publishes it upon approval.
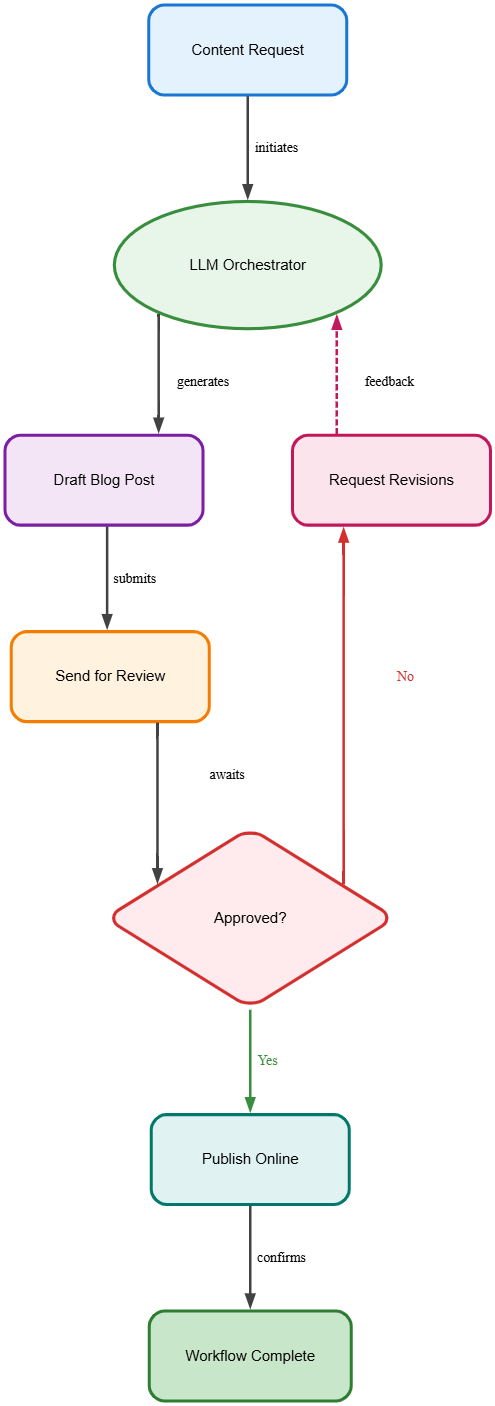
6. Personalization and Adaptation
Explanation:
The system adapts responses based on user history, preferences, or context.
Example:
A language-learning app customizes vocabulary exercises based on past mistakes and preferred topics.
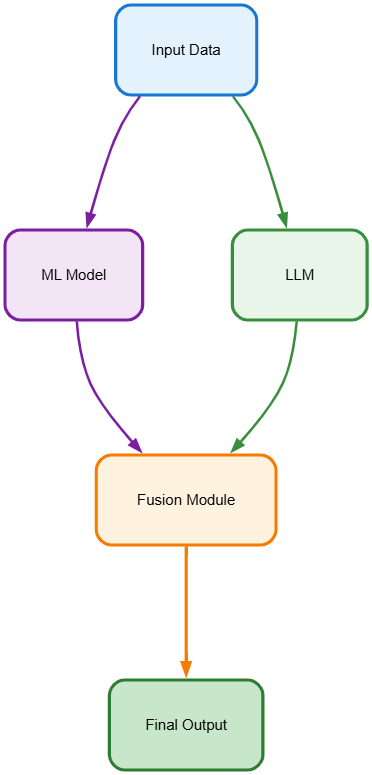
7. Hybrid Models
Explanation:
Combines LLMs with traditional ML models for classification, ranking, or structured prediction.
Example:
A search engine ranks results using a classifier, then uses an LLM to summarize the top results.
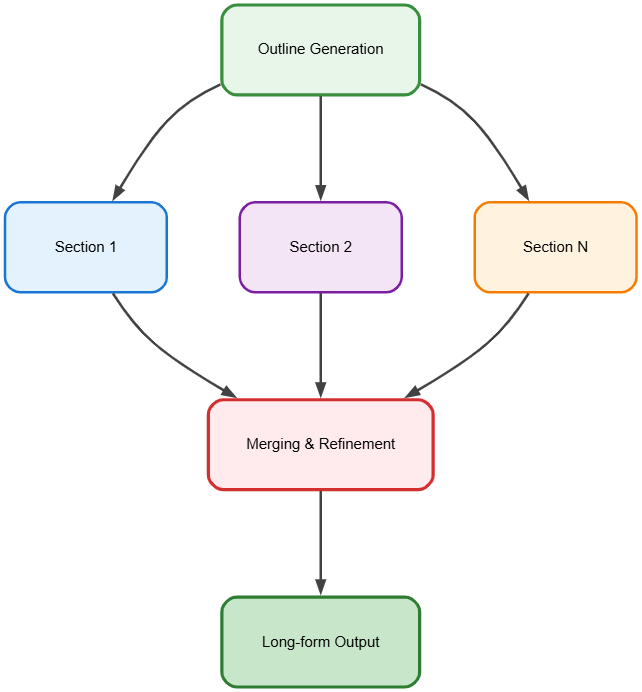
8. Long-form Content Generation
Explanation:
Breaks large content generation tasks into smaller sections, then merges and refines the output.
Example:
An LLM generates an outline, drafts each section, and edits the final document for coherence.
9. Multi-modal Systems
Explanation:
Combines LLMs with models that process images, audio, or other data types.
Example:
An application processes a photo and a voice note, then generates a descriptive caption using both inputs.
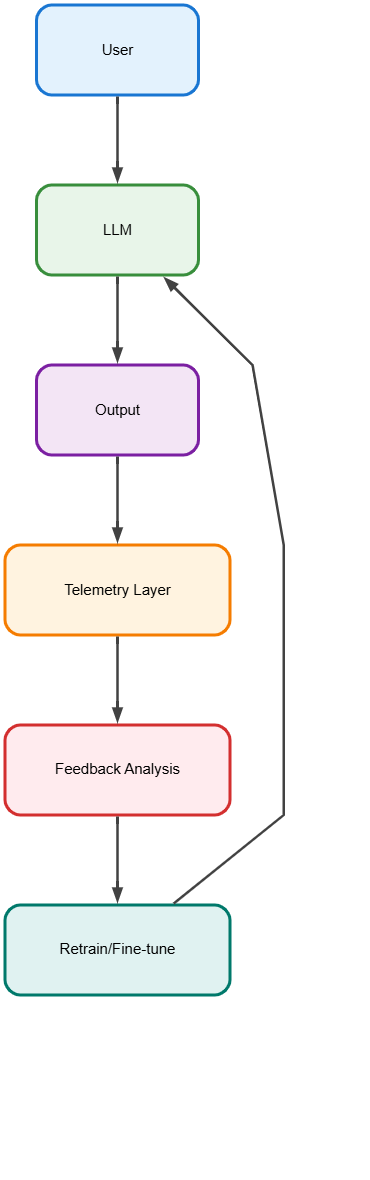
10. Monitoring and Feedback Loops
Explanation:
Continuously collects user feedback and system metrics to improve performance and reliability.
Example:
A chatbot gathers user ratings and uses the data to retrain or fine-tune the model.
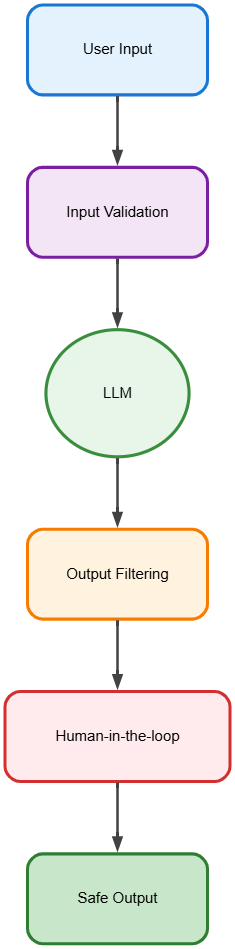
11. Safety and Guardrails
Explanation:
Implements input/output filtering, human review, and policy enforcement.
Example:
A moderation system blocks unsafe queries and flags uncertain outputs for human review.
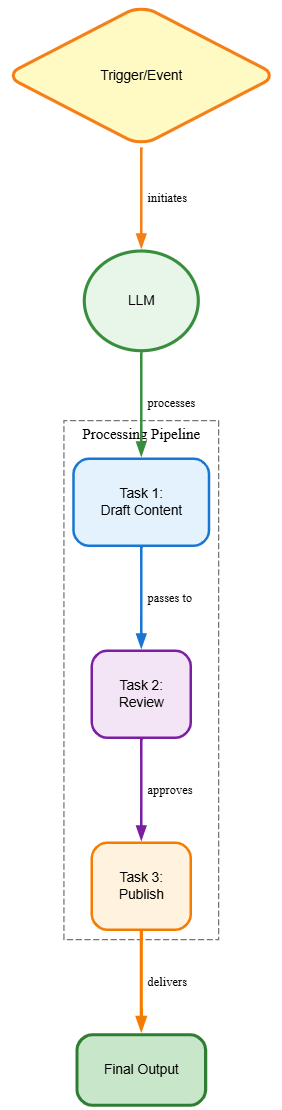
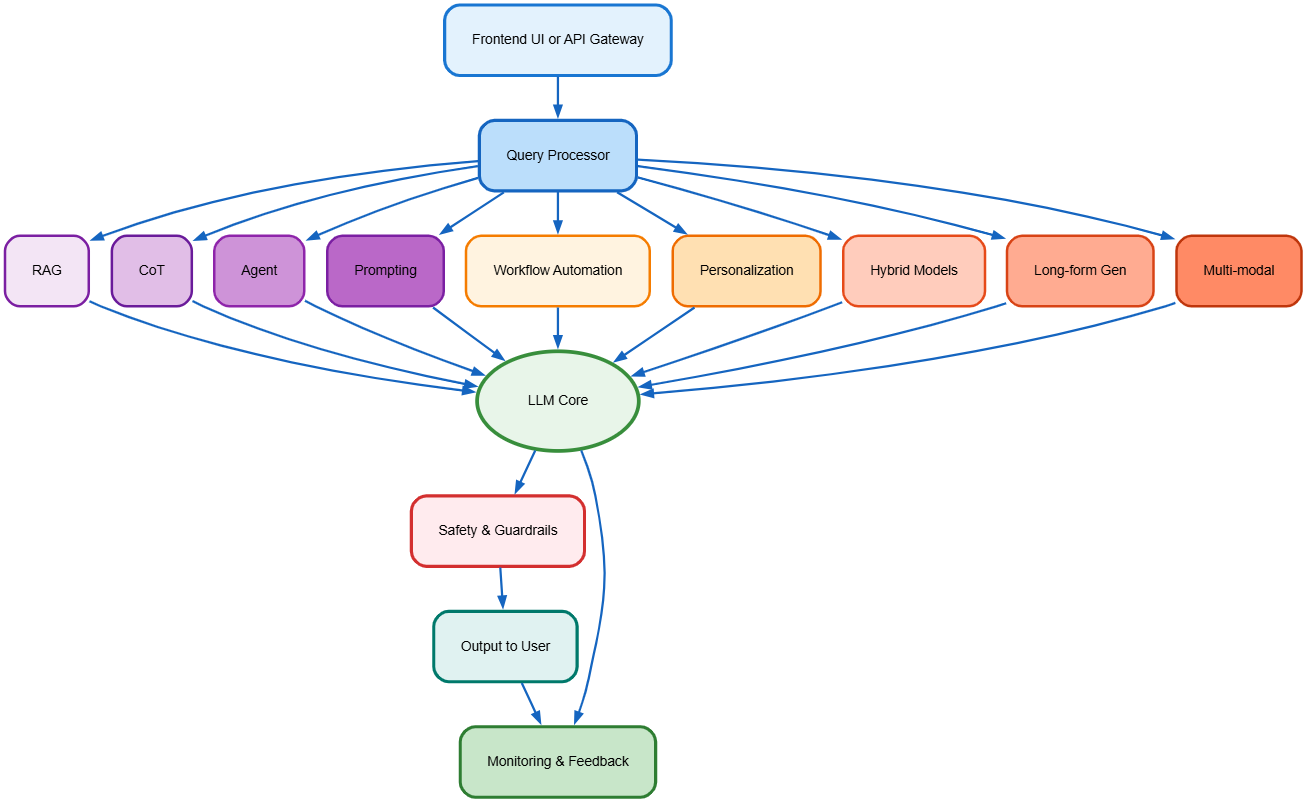
End-to-End Modular LLM Application Architecture
Bringing It All Together
A modern LLM application typically combines several of these patterns to achieve robustness, scalability, and safety.
Final Thoughts
Modern LLM systems are no longer defined by the model alone. They are defined by the architectural patterns that govern how the model retrieves knowledge, reasons, interacts with tools, adapts to users, and remains safe over time.
The 11 patterns described here provide a practical foundation for building reliable and scalable LLM applications. In real-world deployments, these patterns are combined, layered, and continuously iterated. For example, a single system may use RAG for grounding, agents for tool use, workflows for orchestration, feedback loops for continuous improvement, and guardrails for compliance.
As LLM capabilities evolve, these architectural principles will remain stable. Teams that invest in modular, observable, and safety-aware designs will be best positioned to adapt to new models, reduce operational risk, and deliver long-term value from AI.
Successful LLM adoption is not about choosing the most powerful model. It is about choosing the right architecture.
Opinions expressed by DZone contributors are their own.
Comments