Massive Parallel Query Log Processing With ClickHouse
Learn how ClickHouse uses multi-core parallel query processing to efficiently perform heavy analytical workloads and crunch log files.
Join the DZone community and get the full member experience.
Join For FreeIn this blog, I'll look at how to use ClickHouse for parallel log processing.
Percona is seen primarily for our expertise in MySQL and MongoDB (at this time), but neither is quite suitable to perform heavy analytical workloads. There is a need to analyze data sets, and a very popular task is crunching log files. Below, I'll show how ClickHouse can be used to efficiently perform this task. ClickHouse is attractive because it has multi-core parallel query processing, and it can even execute a single query using multiple CPUs in the background.
I am going to check how ClickHouse utilizes multiple CPU cores and threads. I will use a server with two sockets, equipped with "Intel(R) Xeon(R) CPU E5-2683 v3 @ 2.00GHz" in each. That gives a total of 28 CPU cores / 56 CPU threads.
To analyze workload, I'll use an Apache log file from one of Percona's servers. The log has 1.56 billion rows and uncompressed it takes 274G. When inserted into ClickHouse, the table on disk takes 9G.
How do we insert the data into ClickHouse? There is a lot of scripts to transform Apache log format to CSV, which ClickHouse can accept. As for the base, I used this one, and you can find my modification here.
The ClickHouse table definition:
CREATE TABLE default.apachelog ( remote_host String, user String, access_date Date, access_time DateTime, timezone String, request_method String, request_uri String, status UInt32, bytes UInt32, referer String, user_agent String) ENGINE = MergeTree(access_date, remote_host, 8192)To test how ClickHouse scales on multiple CPU cores/threads, I will execute the same query by allocating from 1 to 56 CPU threads for ClickHouse processes. This can be done as:
ps -eLo cmd,tid | grep clickhouse-server | perl -pe 's/.* (d+)$/1/' | xargs -n 1 taskset -cp 0-$i...where $i is (N CPUs-1).
We must also take into account that not all queries are equal. Some are easier to execute in parallel than others. So I will test three different queries. In the end, we can't get around Amdahl's Law!
The first query should be easy to execute in parallel:
select extract(request_uri,'(w+)$') p,sum(bytes) sm,count(*) c from apachelog group by p order by c desc limit 100Speedup:
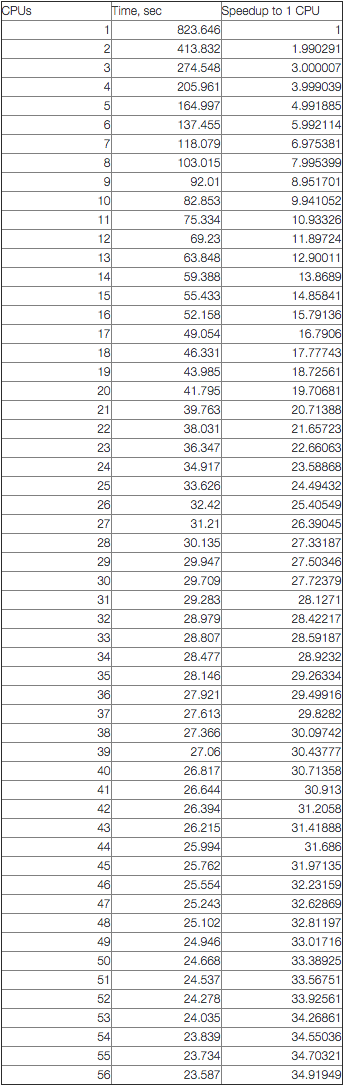
It's much more interesting to chart these results:

From the chart, we can see that the query scales linearly up to 28 cores. After that, it continues to scale up to 56 threads (but with a lesser slope). I think this is related to the CPU architecture (remember we have 28 physical cores and 56 CPU "threads"). Let's look at the results again. With one available CPU, the query took 823.6 seconds to execute. With all available CPUs, it took 23.6 second. So the total speedup is 34.9 times.
But let's consider a query that allows a lesser degree of parallelism. For example, this one:
select access_date c2, count(distinct request_uri) cnt from apachelog group by c2 order by c2 limit 300This query uses aggregation that counts unique URIs, which I am sure limits the counting process to a single shared structure. So some part of the execution is limited to a single process. I won't show the full results for all 1 to 56 CPUs, but for one CPU, the execution time is 177.715 seconds, and for 56 CPUs the execution time is 11.564 seconds. The total speedup is 15.4 times.
The speedup chart looks like this:
As we suspected, this query allows less parallelism. What about even heavier queries? Let's consider this one:
SELECT y, request_uri, cnt FROM (SELECT access_date y, request_uri, count(*) AS cnt FROM apachelog GROUP BY y, request_uri ORDER BY y ASC ) ORDER BY y,cnt DESC LIMIT 1 BY yIn that query, we build a derived table (to resolve the subquery) and I expect it will limit the parallelism even further. And it does; with one CPU, the query takes 183.063 seconds to execute. With 56 CPUs, it takes 28.572 seconds. So the speedup is only 6.4 times.
The chart is:
Conclusion
ClickHouse can capably utilize multiple CPU cores available on the server, and query execution is not limited by a single CPU (like in MySQL). The degree of parallelism is defined by the complexity of the query, and in the best case scenario, we see linear scalability with the number of CPU cores. For the scaling on multiple servers, you can see my previous post.
However, if query execution is serial, it limits the speedup (as described in Amdahl's Law).
One example is a 1.5 billion record Apache log, and we can see that ClickHouse can execute complex analytical queries within tens of seconds.
Published at DZone with permission of Vadim Tkachenko. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments