Migrating Apache Flume Flows to Apache NiFi: Kafka Source to Multiple Sinks
How-to move off of legacy Flume and into modern Apache NiFi for data pipelines.
Join the DZone community and get the full member experience.
Join For Free
The world of streaming is constantly moving... yes I said it. Every few years some projects get favored by the community and by developers. Apache NiFi has stepped ahead and has been the go-to for quickly ingesting sources and storing those resources to sinks with routing, aggregation, basic ETL/ELT, and security. I am recommending a migration from legacy Flume to Apache NiFi. The time is now.
Below, I walk you through a common use case. It's easy to integrate Kafka as a source or sink with Apache NiFi or MiNiFi agents. We can also add HDFS or Kudu sinks as well. All of this with full security, SSO, governance, cloud and K8 support, schema support, full data lineage, and an easy to use UI. Don't get fluming mad, let's try another great Apache project.
As a first step, you can also start by migrating Flume sources and sinks to NiFi.
Source Code: https://github.com/tspannhw/flume-to-nifi

Consume/Publish Kafka and Store to Files, HDFS, Hive 3.1, Kudu

Consume Kafka Flow

Merge Records And Store As AVRO or ORC

Consume Kafka, Update Records via Machine Learning Models In CDSW And Store to Kudu

Source: Apache Kafka Topics

You enter a few parameters and start ingesting data with or without schemas. Apache Flume had no Schema support. Flume did not support transactions.

Sink: Files



Storing to files in files systems, object stores, SFTP, or elsewhere could not be easier. Choose S3, Local File System, SFTP, HDFS, or wherever.
Sink: Apache Kudu/Apache Impala

Storing to Kudu/Impala (or Parquet for that manner could not be easier with Apache NiFi).

Sink: HDFS for Apache ORC Files
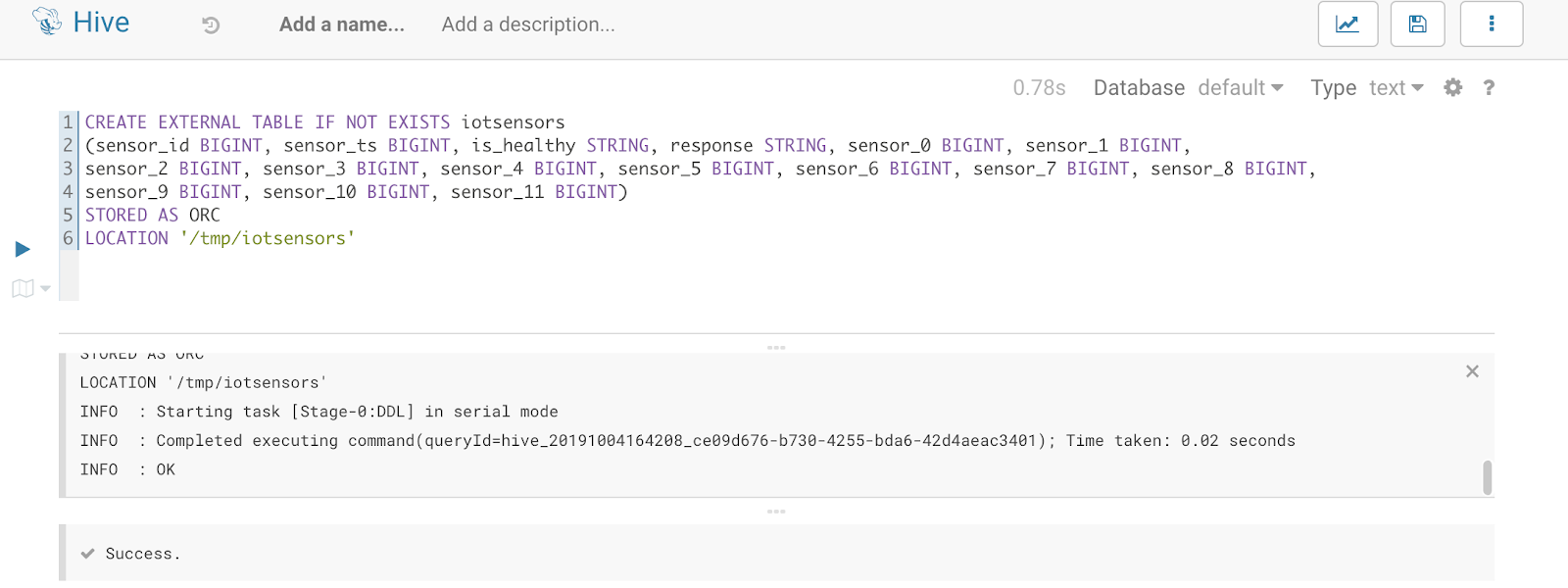
When this is completed, the ConvertAvroToORC and PutHDFS build the Hive DDL for you! You can build the tables automagically with Apache NiFi if you wish.
CREATE EXTERNAL TABLE IF NOT EXISTS iotsensors
(sensor_id BIGINT, sensor_ts BIGINT, is_healthy STRING, response STRING, sensor_0 BIGINT, sensor_1 BIGINT,
sensor_2 BIGINT, sensor_3 BIGINT, sensor_4 BIGINT, sensor_5 BIGINT, sensor_6 BIGINT, sensor_7 BIGINT, sensor_8 BIGINT,
sensor_9 BIGINT, sensor_10 BIGINT, sensor_11 BIGINT)
STOREAS ORC
LOCATION '/tmp/iotsensors'



Sink: Kafka
Publishing to Kafka is just as easy! Push records with schema references or raw data. AVRO or JSON, whatever makes sense for your enterprise.
Write to data easily with no coding and no changes or redeploys for schema or schema version changes.

Pick a Topic and Stream Data While Converting Types

Clean UI and REST API to Manage, Monitor, Configure and Notify on Kafka



Other Reasons to Use Apache NiFi Over Apache Flume
DevOps with REST API, CLI, Python API
Schemas! We not only work with semi-structured, structured and unstructured data. We are schema and schema version aware for CSV, JSON, AVRO, XML, Grokked Text Files and more. https://community.cloudera.com/t5/Community-Articles/Big-Data-DevOps-Apache-NiFi-HWX-Schema-Registry-Schema/ta-p/247963.
Flume Replacement Use Cases Implemented in Apache NiFi
Sink/Source: JMS
Source: Files/PDF/PowerPoint/Excel/Word Sink: Files
Source: Files/CSV Sink: HDFS/Hive/Apache ORC
Source: REST/Files/Simulator Sink: HBase, Files, HDFS. ETL with Lookups.
Flume Replacement - Lightweight Open Source Agents

If you need to replace local Log to Kafka agents or anything to Kafka or anything to anything with routing, transformation and manipulation. You can use Edge Flow Manager deployed MiNiFi Agents available in Java and C++ versions.
Further Reading
Opinions expressed by DZone contributors are their own.
Comments