Breaking to Build Better: Platform Engineering With Chaos Experiments
Platform engineering uses chaos experiments to build resilient, self-healing systems that withstand and adapt during real-world failures.
Join the DZone community and get the full member experience.
Join For FreeImagine you're on a high-speed train—sleek, automated, and trusted by thousands every day. It rarely misses a beat. But behind that smooth ride is a team that constantly simulates disasters: brake failures, signal losses, and power surges. Why? Because when lives depend on reliability, you don’t wait for failure to happen—you plan for it. The same principle applies in today’s cloud-native platforms.
As platform engineers, we design systems to be resilient, scalable, and reliable. But here’s the truth—no matter how perfect your YAMLs or CI/CD pipelines are, failure is inevitable. Chaos engineering, a discipline born out of necessity, is not about causing random destruction, but it’s about intentionally injecting failure into your systems in a controlled environment to understand how they behave under stress. Like fire drills for your platform. In this blog, we’ll explore how you can bring this into your Platform Engineering practices using LitmusChaos, an open-source chaos engineering framework built for Kubernetes.
Platform Engineering and the Need for Resilience
You could say platform engineering is what quietly holds modern software delivery together, keeping everything running smoothly behind the scenes. It provides reusable, secure, and scalable frameworks—Internal Developer Platforms (IDPs)—that abstract the complexity of cloud environments and let developers focus on shipping features. But as these platforms become more critical and interconnected, any small failure can cascade into major outages.
That’s why resilience is not just a nice-to-have—it’s a design requirement. Resilience must be validated continuously—and this is where chaos engineering becomes a critical tool in the platform engineer’s toolkit.
By proactively injecting faults—killing pods, simulating node failures, introducing latency—you get to see how your platform truly behaves when things go sideways. It’s a stress test for your system's immune response. In other words, platform engineering builds the runway; resilience ensures the plane can land safely even in a storm.
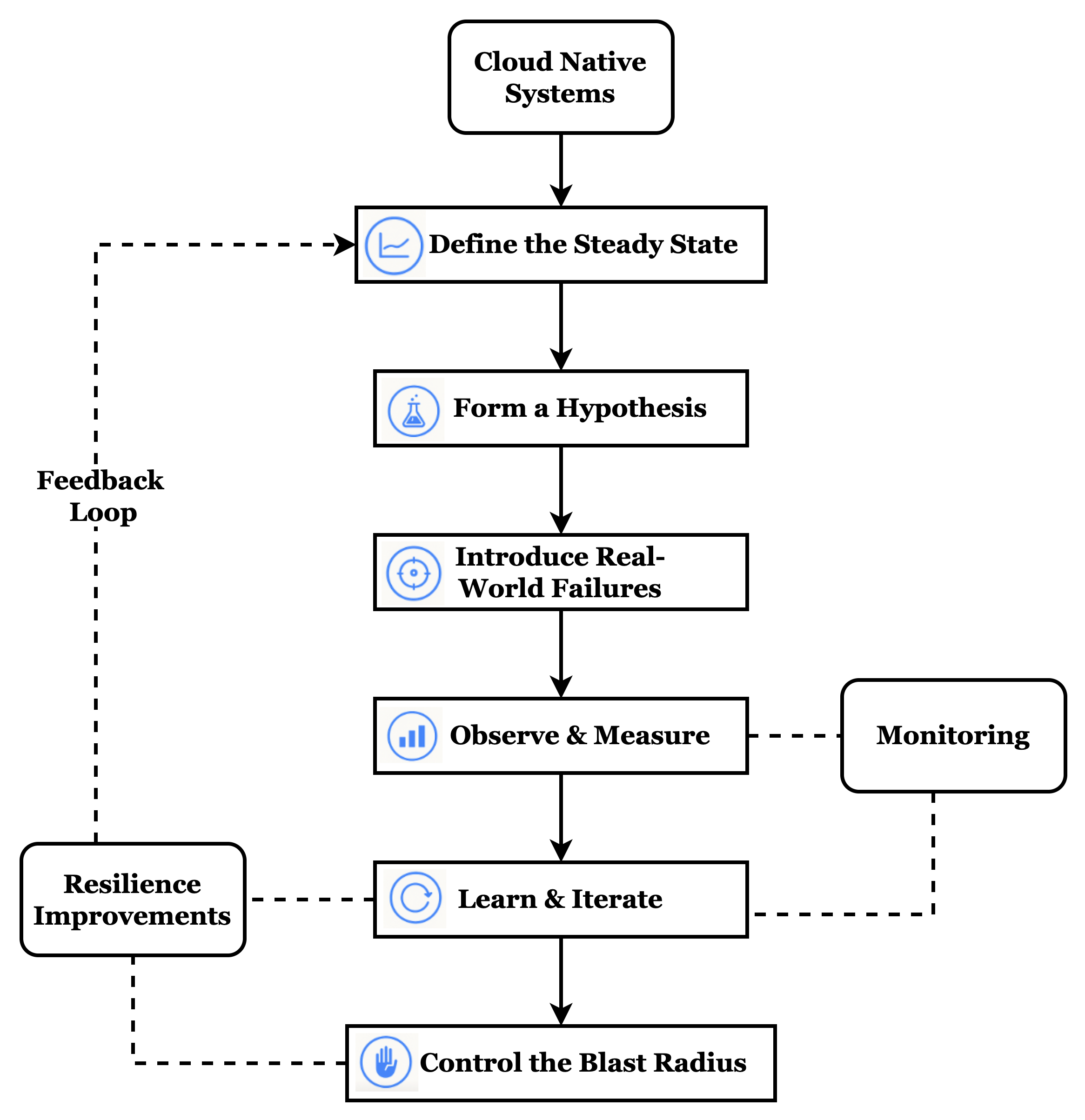
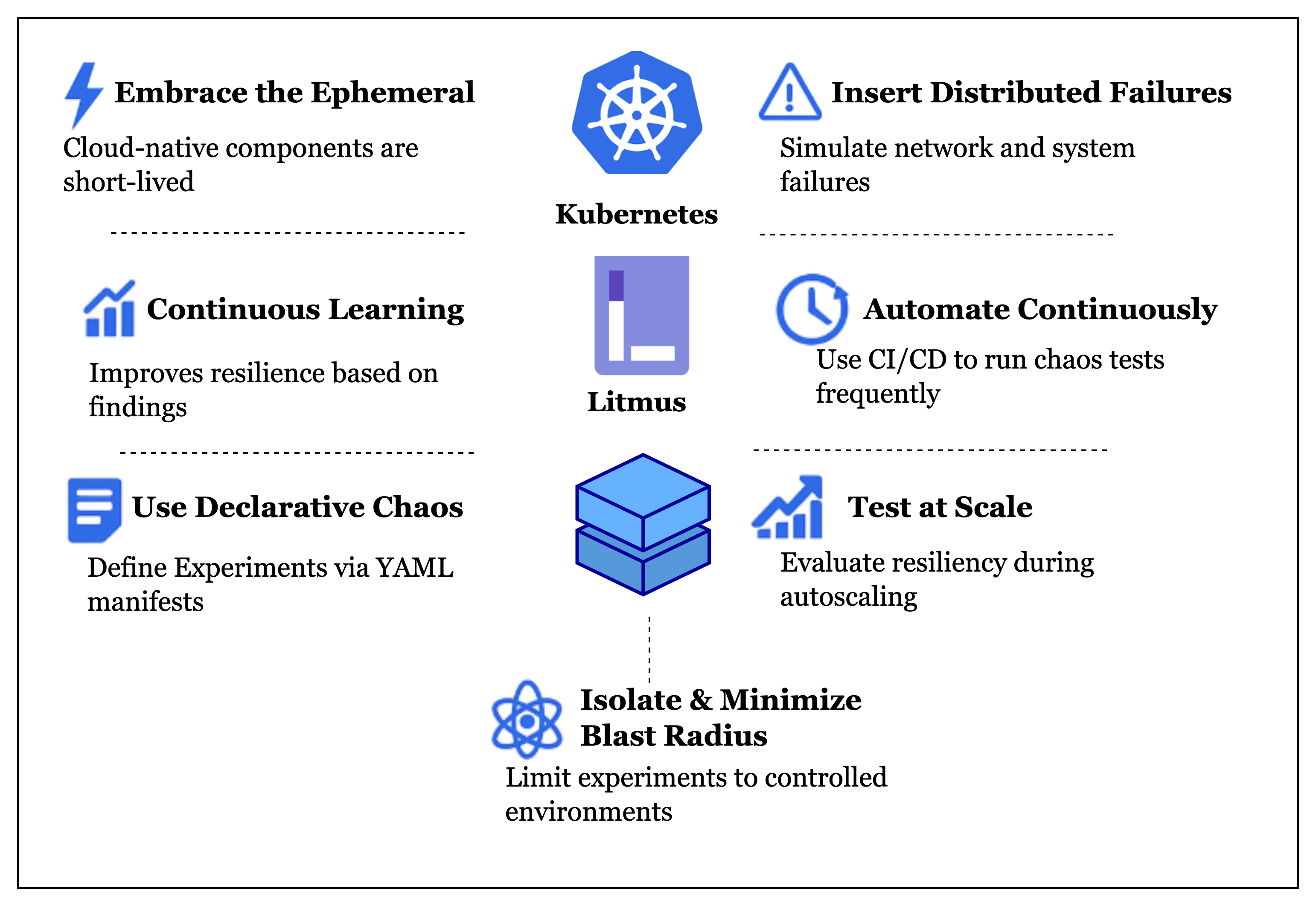
Chaos Engineering Principles for Cloud Native Systems
At its core, chaos engineering is about injecting controlled failure into a system to uncover weaknesses before they manifest in production. It’s especially relevant for cloud-native architectures, where microservices, containers, service meshes, and dynamic orchestration introduce both flexibility and fragility.
Following are the core principles of chaos engineering for cloud-native systems:
- Define the Steady State—Before you break anything, you need to know what “healthy” looks like. In cloud-native systems, this could mean the following, and it becomes your baseline for measuring impact.
- 95th percentile latency stays below 200ms
- Error rate < 1%
- All pods are in
RunningandReadystate
- Form a Hypothesis—Chaos isn’t about random destruction. It’s about testing expectations:
“If I kill a pod in the recommendation service, the platform should automatically restart it without user-visible impact.”
Every experiment should have a clear hypothesis you're validating.
- Introduce Real-World Failures—Chaos experiments simulate real failure conditions, such as:
- Killing pods or containers
- Introducing network latency or partition
- Simulating node or region outages
- Exhausting memory/CPU
Tools like LitmusChaos, Gremlin, and Chaos Mesh integrate directly with Kubernetes to inject such failures in a safe, controlled manner.
- Observe and Measure —Use observability stacks—Prometheus, Grafana, Loki, Jaeger—to monitor how your system responds. Did it:
- Auto-heal?
- Retry requests?
- Degrade gracefully?
- Fail catastrophically?
Monitoring the blast radius and behavior is crucial to understanding systemic weaknesses.
- Automate & Run Continuously—One-time experiments are valuable, but resilience needs to be continuously validated. Integrate chaos into:
- CI/CD pipelines
- GitOps workflows
- Post-deployment testing
- Canary releases
This ensures your platform remains robust through change, scaling, and evolution.
- Control the Blast Radius—Start small. Chaos is only useful if it doesn’t break everything all at once. Use Namespaces, Resource labels, Time-limited experiments to ensure your testing is safe and contained.
- Learn and Iterate—Every chaos experiment is a learning opportunity. Feed failures and insights back into:
- Platform design
- Readiness/liveness probes
- Retry logic
- Scaling policies
This feedback loop is what makes chaos engineering a strategic practice, not a one-time stunt.
Introducing LitmusChaos: CNCF’s Chaos Engineering Tool
LitmusChaos is an open-source chaos engineering platform incubated under the Cloud Native Computing Foundation (CNCF). It’s designed specifically for Kubernetes environments, making it a natural fit for platform engineers who are building and maintaining IDPs and cloud-native systems. Unlike traditional chaos tools that might focus on virtual machines or networks, Litmus is purpose-built for Kubernetes—meaning it speaks the language of pods, deployments, namespaces, CRDs, and RBAC.
Key Components of LitmusChaos
LitmusChaos is modular, extensible, and built on Kubernetes-native principles. Here are its major building blocks:
Chaos Operator: A controller that watches forChaosEnginecustom resources and triggers chaos experiments accordingly.ChaosExperiments: Predefined templates that define the chaos logic (e.g.,pod-delete,container-kill,network-delay).ChaosEngine: The custom resource that links a specific experiment with a target application.ChaosResult: Automatically generated resources that store the outcome and verdict of experiments.ChaosCenter(optional UI): A web-based dashboard to design, schedule, and monitor experiments—ideal for team collaboration.
Refer here to learn more about Litmus architecture and its flow.
Running Chaos Experiments
This tutorial demonstrates how to inject controlled failure into a live Kubernetes workload using LitmusChaos, validating NGINX’s resilience and the platform’s self-healing capabilities
Deploy a Sample Microservice (NGINX)
Deploy an Nginx into Kubernetes using the below commands.
kubectl create namespace litmus
kubectl create deployment nginx --image=nginx --namespace=litmus
kubectl label deployment nginx app=nginx -n litmusExpose the deployment internally as a service by running the command kubectl apply -f nginx-service.yamlusing the below YAML saved as nginx-service.yaml.
# nginx-service.yaml
apiVersion: v1
kind: Service
metadata:
name: nginx
namespace: litmus
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: ClusterIP
Install LitmusChaos
Install using Helm (recommended):
helm repo add litmuschaos https://litmuschaos.github.io/litmus-helm/
helm install litmus litmuschaos/litmus --namespace=litmus
Connect the Agent (Chaos Delegate)
Enable the access to the ChaosCenter UI by running the command kubectl port-forward svc/litmus-frontend-service -n litmus 9091:9091
Navigate to http://localhost:9091, log in (admin/litmus), and follow the UI to "Enable Chaos" in the litmus namespace.
Create and Run a Chaos Experiment (Pod Delete)
From the UI:
- Go to Chaos Experiments > + New Experiment
- Choose Agent →
poddeletechaos - Select
pod-deletefrom ChaosHub - Set:
- App label:
app=nginx - Namespace:
litmus
- App label:
- Optionally add an HTTP Probe:
- URL:
http://nginx.litmus.svc.cluster.local - Method:
GET - Expected status:
200
- URL:
Click Apply Changes, then Run.
Observe the Chaos
Watch the chaos pod using the command kubectl get pods -n litmus -w
Watch the chaos results using the command
kubectl describe chaosresult nginx-pod-delete-pod-delete -n litmus
This chaos experiment intentionally deleted an NGINX pod in the litmus namespace. The deployment's self-healing capability brought up a new pod, and the ChaosResult confirmed a successful run. This validated the platform's ability to recover from unplanned pod terminations — a cornerstone for production-grade resilience in Kubernetes.
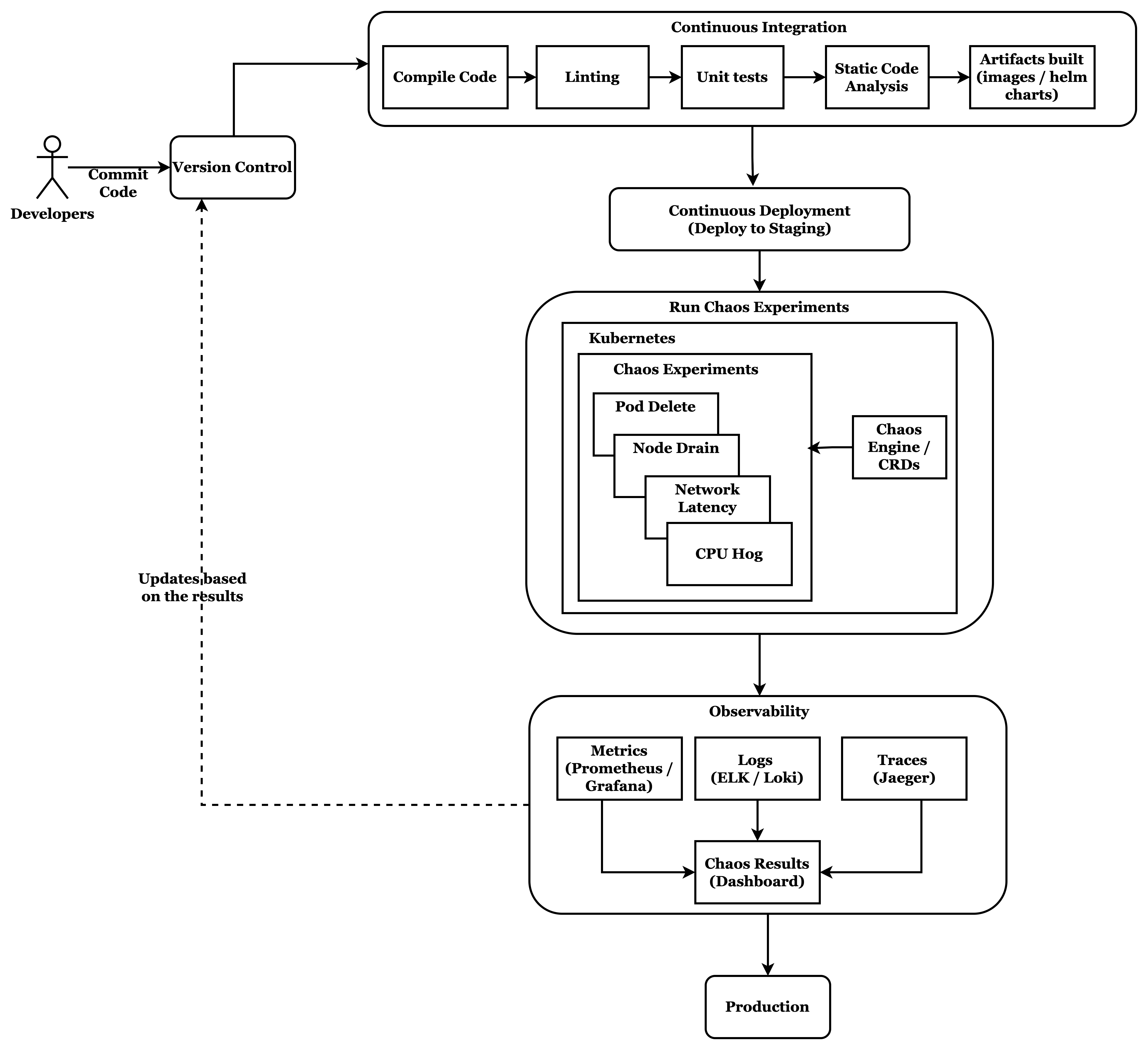
Automating Chaos in Platform Engineering Pipelines
In the world of Platform Engineering, automation is the backbone of efficiency. CI/CD pipelines, GitOps workflows, and infrastructure-as-code have revolutionized how software and infrastructure are delivered. But what if you could automate resilience testing the same way you automate deployments?
Manual chaos experiments are a wonderful starting point, but they’re limited in scope, frequency, and reproducibility. Automation brings consistency, speed, early detection, and developer confidence.
Why Chaos Engineering Matters for Platform Engineering
|
Role of PE
|
How Chaos Engineering Helps
|
|---|---|
|
Abstracting infrastructure |
Validates if infrastructure abstractions survive real-world failures |
|
Providing golden paths |
Ensures golden paths can recover from outages (e.g., self-healing K8s) |
|
Platform reliability guarantees |
Verifies platform uptime and SLOs through fault injection |
|
Tooling & automation |
Integrates chaos into CI/CD pipelines to catch regressions early |
|
Developer experience (DX) |
Avoids developer disruption due to cascading failures |
Where Chaos Fits in the Pipeline?
Here’s how LitmusChaos can integrate into various stages of your platform engineering pipeline:
|
Pipeline Stage
|
Integration Example
|
|---|---|
|
Pre-merge |
Run chaos tests for core services in ephemeral test environments. |
|
Post-deploy (stage) |
Inject pod/network faults to validate system recovery before production. |
|
Canary releases |
Introduce failure during partial rollouts to test real-time rollback policies. |
|
Nightly builds |
Trigger stress, latency, or resource chaos experiments in batch. |
Toolchain Integration Examples
- GitHub Actions: Use kubectl or litmusctl to run chaos workflows as part of CI.
- Jenkins Pipelines: Integrate Litmus YAMLs into Jenkinsfile stages with recovery validation.
- ArgoCD/Tekton: Chaos CRDs can be versioned and triggered via GitOps, ensuring declarative chaos-as-code.
- Helm and Terraform: Deploy chaos infrastructure as part of your platform provisioning pipelines.
Integration Points in Platform Engineering
|
Integration Layer
|
Example Chaos Scenario
|
|---|---|
|
CI/CD Pipelines |
Simulate artifact registry failure during deployment |
|
Kubernetes |
Pod/node/network failures for a platform service |
|
Observability |
Drop metrics/alerts to test dashboard reliability |
|
Secrets/Configs |
Inject stale or revoked credentials to test fallback |
|
Autoscalers |
Chaos during scale-out and scale-in events |
|
GitOps |
Simulate Git server unavailability or drift |
Automate But With Governance
Chaos automation doesn’t mean recklessness. Platform teams must ensure:
- RBAC and blast radius controls
- Time-boxed chaos execution
- Audit trails and experiment result logs
- Approval flows for certain environments (like staging or production)
Using tools like LitmusChaos’s ChaosCenter, teams can visualize and manage chaos runs securely and collaboratively.
What Not to Do: Chaos Testing Anti-Patterns
Chaos testing, when done correctly, helps build resilient systems. However, several anti-patterns can lead to misleading results, system degradation, or loss of stakeholder confidence. Below are key chaos testing anti-patterns, grouped into categories:
- Testing Without a Hypothesis - Running chaos experiments without a clear, measurable hypothesis.
- Best Practice - Always start with a hypothesis like “If service A fails, service B should automatically retry and not crash.”
- No Baseline Observability - Injecting failures without knowing the baseline performance or having proper monitoring/logging.
- Best Practice - Ensure observability tools like Prometheus, Grafana, or OpenTelemetry are in place and capturing metrics like latency, error rates, and throughput.
- Conducting Tests in Production Without Guardrails - Running chaos experiments in production with no safeguards or rollback strategies.
- Best Practice - Use feature flags, blast radius control, and time-boxing to minimize impact.
- Ignoring Blast Radius - Launching broad, uncontrolled chaos tests affecting critical infrastructure components.
- Best Practice - Start small (single service or pod), expand gradually.
- One-Off Chaos Events (Not Continuous) - Running chaos tests only once, usually just before major releases.
- Best Practice - Integrate chaos into CI/CD pipelines or schedule it as recurring events.
- No Stakeholder Communication - Running chaos experiments without informing relevant teams (SRE, DevOps, Product).
- Best Practice - Notify teams in advance, document test plans, and involve stakeholders in planning.
-
Focusing Only on Infrastructure Failures - Only injecting failures like CPU hogs or pod deletions and ignoring application-level or dependency failures.
- Best Practice - Include real-world scenarios (DNS misconfig, network latency, API throttling, etc.)
- Lack of Automation - Manually triggering chaos tests each time.
- Best Practice - Automate chaos workflows using tools like LitmusChaos, Gremlin, or Chaos Mesh integrated with CI/CD or event-driven pipelines.
- Tying Chaos to Technical Impacts Only—Focusing solely on technical metrics without measuring impact on customer experience or SLAs.
- Best Practice - Correlate with user-facing metrics (conversion rate, availability, SLO breaches).
Conclusion: Building Trust Through Controlled Failure
In platform engineering, trust isn't built by avoiding failure—it’s earned by surviving it.
Chaos Engineering isn’t about being reckless or crashing systems just for fun. It’s about being curious and intentional—introducing failures in a safe, controlled way to uncover blind spots before they impact real users. It’s a practice rooted in preparation, not panic.
When teams embrace chaos as part of their platform engineering mindset, something powerful happens: they move beyond just “getting things to run” and start building platforms that can bend without breaking. Tools like LitmusChaos make this possible at scale—automating chaos experiments, integrating them into CI/CD pipelines, and turning chaos into just another quality check.
The process—defining what “healthy” looks like, experimenting with failure, observing the outcomes, and learning from the results—shifts how teams think about reliability. Failure stops being something to fear and starts being something to prepare for.
Resilience isn't just a feature—it's a promise.
Opinions expressed by DZone contributors are their own.
Comments