Problem Analysis in Apache Doris StreamLoad Scenarios
Troubleshoot common Apache Doris StreamLoad import errors, including missing partitions, data type mismatches, and special character issues, for smooth syncing.
Join the DZone community and get the full member experience.
Join For FreeApache Doris provides multiple ways to import data, including StreamLoad, HdfsLoad (gradually replacing BrokerLoad), RoutineLoad, MySQLLoad, and others. StreamLoad is the most commonly used method, as many data synchronization tools like Flink, Spark, and DataX use it under the hood.
Since StreamLoad is the underlying mechanism for Flink Doris Connector, Spark Doris Connector, and DataX, most data import issues tend to occur with StreamLoad. This article will discuss common import errors and their solutions.
Several Common Data Import Errors
1. Partition Not Created
Schema
CREATE TABLE IF NOT EXISTS tb_dynamic_partition_test2 (
`sid` LARGEINT NOT NULL COMMENT "Student ID",
`name` VARCHAR(50) NOT NULL COMMENT "Student Name",
`class` INT COMMENT "Class",
`age` SMALLINT COMMENT "Age",
`sex` TINYINT COMMENT "Gender",
`phone` LARGEINT COMMENT "Phone",
`address` VARCHAR(500) NOT NULL COMMENT "Address",
`date` DATETIME NOT NULL COMMENT "Date of Data Entry"
)
ENGINE=olap
DUPLICATE KEY (`sid`, `name`)
PARTITION BY RANGE(`date`)()
DISTRIBUTED BY HASH (`sid`) BUCKETS 4
PROPERTIES (
"dynamic_partition.enable"="true",
"dynamic_partition.start"="-3",
"dynamic_partition.end"="1",
"dynamic_partition.time_unit"="DAY",
"dynamic_partition.prefix"="p_",
"dynamic_partition.replication_num"="1",
"dynamic_partition.buckets"="4"
);StreamLoad Command
curl --location-trusted -u root -H "column_separator:," -T /mnt/disk2/test.csv http://ip:8030/api/test/tb_dynamic_partition_test2/_stream_loadError
Reason: no partition for this tuple. tuple=+---------------+---------------+--------------------+--------------------+--------------------+------------------+-----------------+----------------+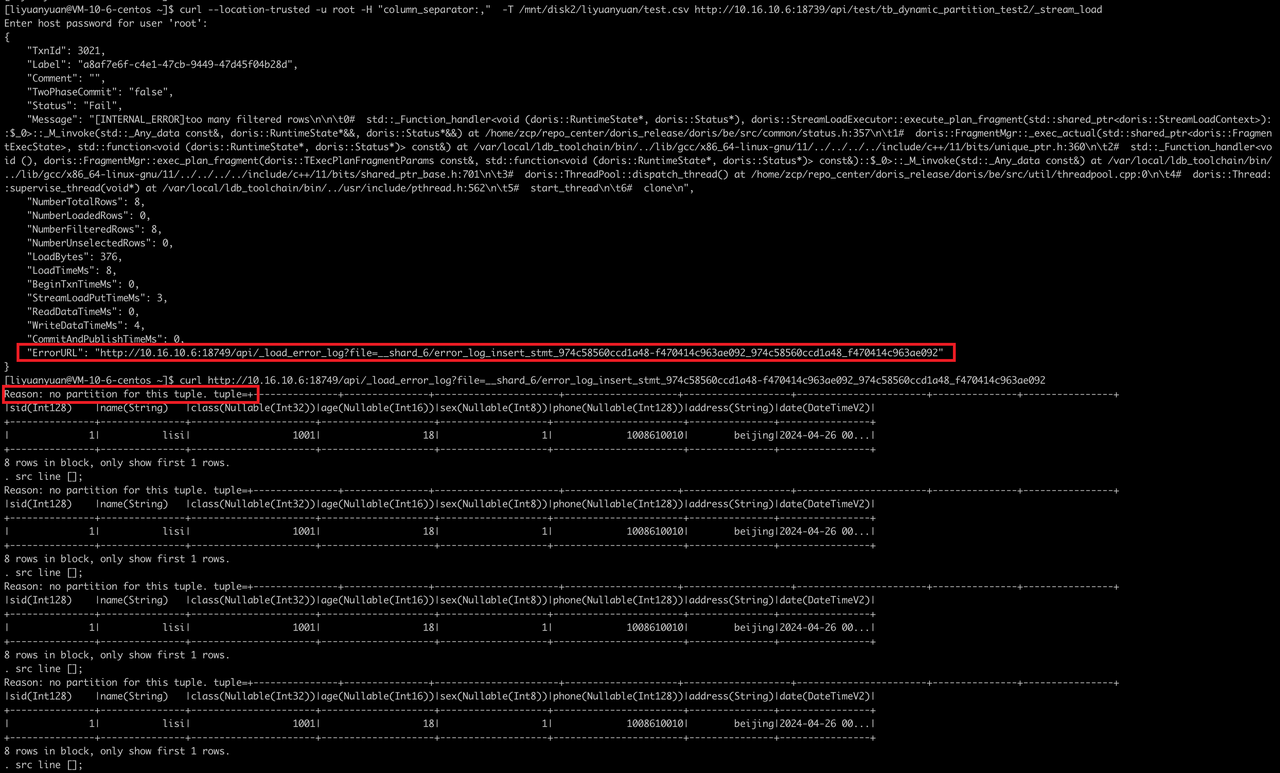
Solution
The error occurs when there is no partition for the data. To resolve this, create the missing partition:
-- Disable dynamic partition
ALTER TABLE tb_dynamic_partition_test2 SET ("dynamic_partition.enable" = "false");
-- Add partition
ALTER TABLE tb_dynamic_partition_test2 ADD PARTITION p_20240426 VALUES [("2024-04-26 00:00:00"), ("2024-04-27 00:00:00")) ("replication_num"="1");
-- Re-enable dynamic partition
ALTER TABLE tb_dynamic_partition_test2 SET ("dynamic_partition.enable" = "true");After adding the partition, data should import successfully.
2. Data and Column Type Mismatch
Schema
CREATE TABLE IF NOT EXISTS test (
`sid` LARGEINT NOT NULL COMMENT "Student ID",
`name` VARCHAR(5) NOT NULL COMMENT "Student Name",
`class` INT COMMENT "Class",
`age` SMALLINT COMMENT "Age",
`sex` TINYINT COMMENT "Gender",
`phone` LARGEINT COMMENT "Phone",
`address` VARCHAR(5) NOT NULL COMMENT "Address",
`date` DATETIME NOT NULL COMMENT "Date of Data Entry"
)
ENGINE=olap
DUPLICATE KEY (`sid`, `name`)
DISTRIBUTED BY HASH (`sid`) BUCKETS 4
PROPERTIES (
"replication_num"="1"
);StreamLoad Command
curl --location-trusted -u root -H "column_separator:," -T /mnt/disk2/liyuanyuan/data/test.csv http://10.16.10.6:18739/api/test/test/_stream_loadData
1, lisixxxxxxxxxxxxxxxxxxxx, 1001, 18, 1, 1008610010, bj, 2024-04-26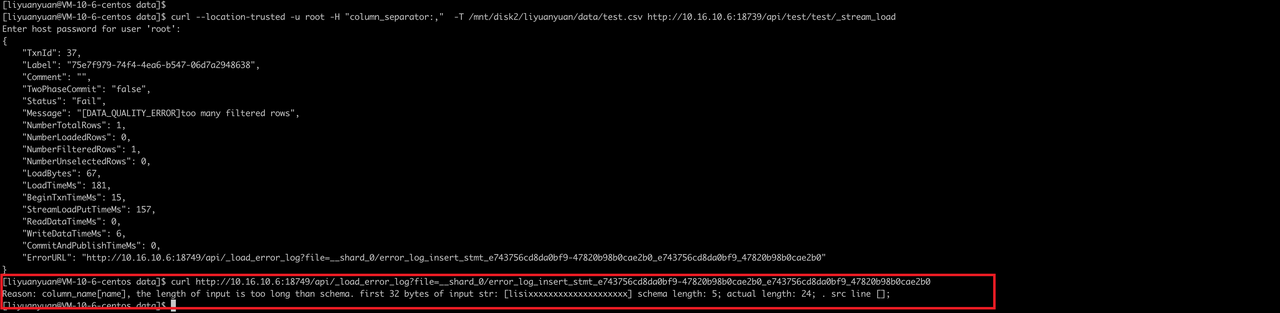
Error
Reason: column_name[name], the length of input is too long than schema. first 32 bytes of input str: [lisixxxxxxxxxxxxxxxxxxxx] schema length: 5; actual length: 24;Solution
The name column's data length exceeds the schema definition. To fix this, increase the length of the name column.
ALTER TABLE test MODIFY COLUMN name VARCHAR(50);Data should now import successfully.
3. Mismatched Columns Between Data and Schema
Schema
CREATE TABLE IF NOT EXISTS test2 (
`sid` LARGEINT NOT NULL COMMENT "Student ID",
`name` VARCHAR(50) NOT NULL COMMENT "Student Name",
`class` INT COMMENT "Class",
`age` SMALLINT COMMENT "Age",
`sex` TINYINT COMMENT "Gender",
`phone` LARGEINT COMMENT "Phone",
`address` VARCHAR(50) NOT NULL COMMENT "Address",
`date` DATETIME NOT NULL COMMENT "Date of Data Entry"
)
ENGINE=olap
DUPLICATE KEY (`sid`, `name`)
DISTRIBUTED BY HASH (`sid`) BUCKETS 4
PROPERTIES (
"replication_num"="1"
);Data
1, xxxxxxxxxxxxxxxxxxxxxxx, 1001, 18, 1, 1008610010, beijing, 2024-04-26, test_columnStreamLoad Command
curl --location-trusted -u root -H "column_separator:," -T /mnt/disk2/liyuanyuan/data/test2.csv http://10.16.10.6:18739/api/test/test2/_stream_load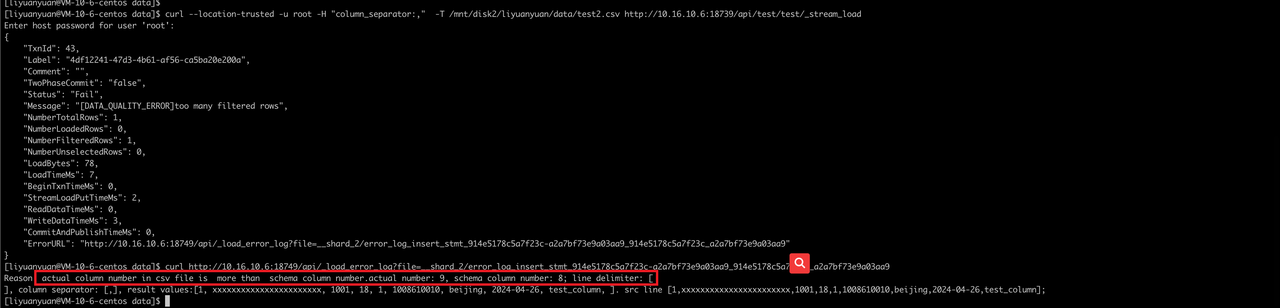
Error
Reason: actual column number in CSV file is more than schema column number. Actual number: 9, schema column number: 8.Solution
To fix this, add the extra column to the schema:
ALTER TABLE test2 ADD COLUMN new_col VARCHAR(50);4. Special Characters in CSV Causing Import Failure
Special characters like commas within the data can cause issues during import, especially when columns contain delimiters. A good solution is to use the JSON format instead of CSV for such cases.
If the spark or flink engine is used for import, set the following parameters.
Solution
properties.setProperty("format", "json");
properties.setProperty("read_json_by_line", "true");Alternatively, use the proper escape sequences for handling special characters in CSV files.
Handling Special Characters in CSV Files
1. Data Containing Quotation Marks
When dealing with CSV files where data is enclosed in quotation marks, it’s important to configure StreamLoad with the appropriate settings.
Example Schema
CREATE TABLE IF NOT EXISTS test3 (
`sid` LARGEINT NOT NULL COMMENT "Student ID",
`name` VARCHAR(50) NOT NULL COMMENT "Student Name",
`class` INT COMMENT "Class",
`age` SMALLINT COMMENT "Age",
`sex` TINYINT COMMENT "Gender",
`phone` LARGEINT COMMENT "Phone",
`address` VARCHAR(50) NOT NULL COMMENT "Address",
`date` DATETIME NOT NULL COMMENT "Date of Data Entry"
)
ENGINE=olap
DUPLICATE KEY (`sid`, `name`)
DISTRIBUTED BY HASH (`sid`) BUCKETS 4
PROPERTIES (
"replication_num"="1"
);Data
"1","xxxxxxx","1001","18","1","1008610010","beijing","2024-04-26"StreamLoad Command
curl --location-trusted -u root -H "column_separator:," -H "enclose:\"" -H "trim_double_quotes:true" -T /path/to/test3.csv http://ip:8030/api/test/test3/_stream_loadSolution
enclose: specifies a enclose character.
trim_double_quotes: to true when cutting the CSV file for each field of the outermost double quotation marks.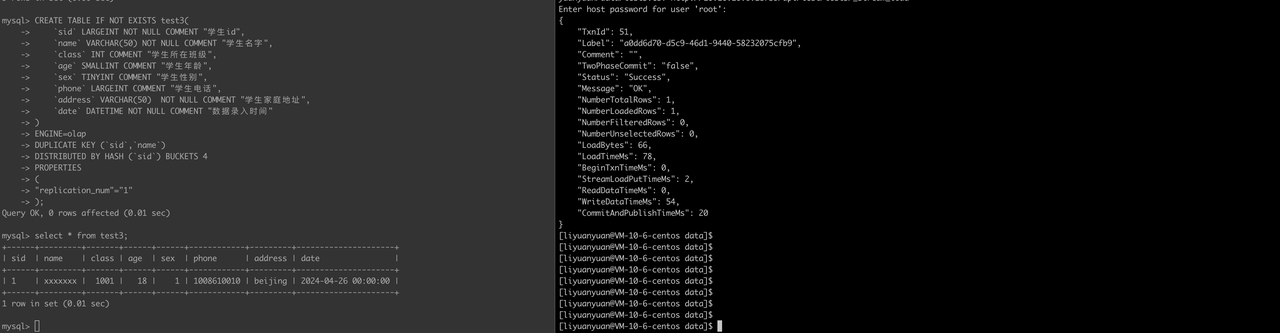
2. Data Containing Partial Quotes
Data
"1","xx,x,x,xxx",1001,18,"1",1008610010,"bei,jing",2024-04-26StreamLoad Command
curl --location-trusted -u root -H "column_separator:," -H "enclose:\"" -H "trim_double_quotes:true" -T /mnt/disk2/liyuanyuan/data/test4.csv http://10.16.10.6:18739/api/test/test4/_stream_loadHandling Windows Line Endings
If data is imported from Windows (with \r\n line endings) causes issues where queries do not return expected results, check if the Windows line endings are present.
Solution
Use od -c to check for \r\n and specify the correct line delimiter during import:
-H "line_delimiter:\r\n"
Using Expression in StreamLoad
Example 1
CREATE TABLE test_streamload (
user_id BIGINT NOT NULL COMMENT "User ID",
name VARCHAR(20) COMMENT "User Name",
age INT COMMENT "User Age"
)
DUPLICATE KEY (user_id)
DISTRIBUTED BY HASH (user_id) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);StreamLoad Command
curl --location-trusted -u "root:" -T /path/to/data.csv -H "format:csv" -H "column_separator:," -H "columns:user_id,tmp,age,name=upper(tmp)" http://ip:8030/api/test/test_streamload/_stream_load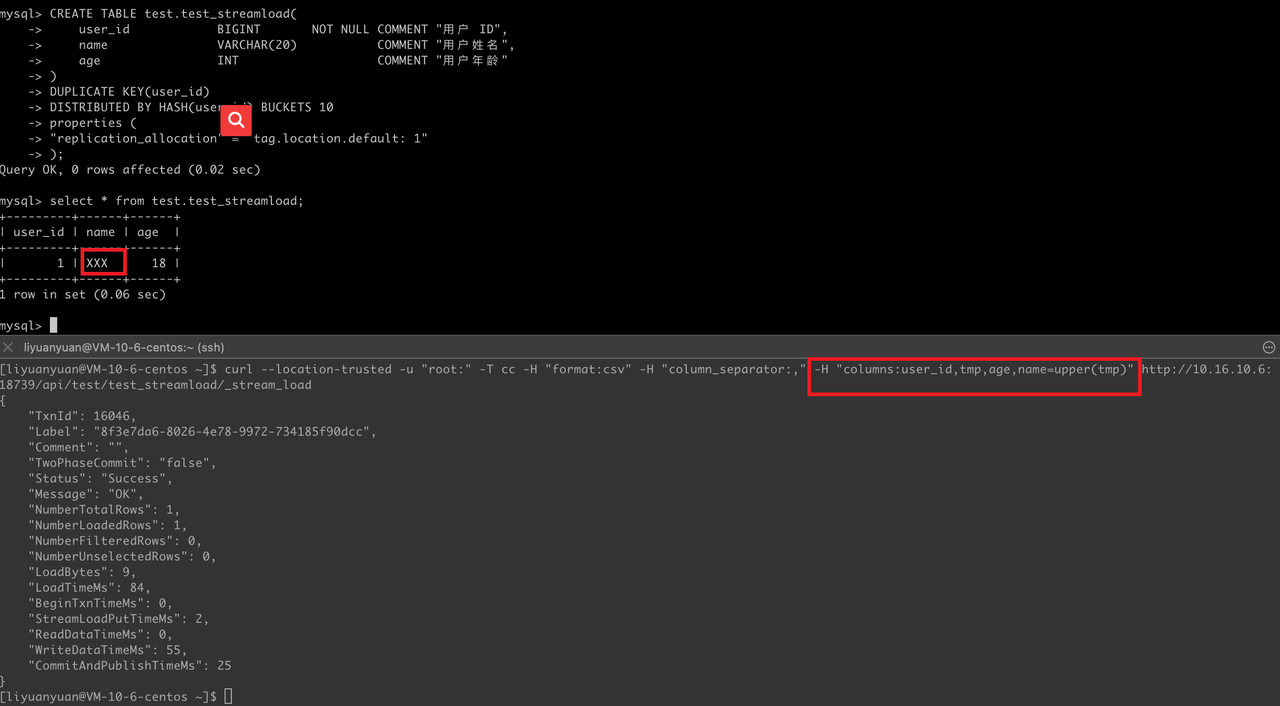
Example 2
CREATE TABLE test_streamload2 (
c1 INT,
c2 INT,
c3 VARCHAR(20)
)
DUPLICATE KEY (c1)
DISTRIBUTED BY HASH (c1) BUCKETS 10
PROPERTIES (
"replication_allocation" = "tag.location.default: 1"
);StreamLoad Command
curl --location-trusted -u "root:" -T /path/to/data.csv -H "format:csv" -H "column_separator:," -H "columns:c1,c2,A,B,C,c3=CONCAT(A,B,C)" http://ip:8030/api/test/test_streamload2/_stream_load
Conclusion
By understanding and addressing these common data import errors, you can significantly reduce the time spent troubleshooting and ensure smoother data synchronization with Apache Doris.
Opinions expressed by DZone contributors are their own.
Comments