Redis as a Primary Database for Complex Applications
This article aims to answer one question: How can Redis be used as a primary database for complex applications that need to store data in multiple formats?
Join the DZone community and get the full member experience.
Join For FreeFirst, we will see what Redis is and its usage, as well as why it is suitable for modern complex microservice applications. We will talk about how Redis supports storing multiple data formats for different purposes through its modules. Next, we will see how Redis, as an in-memory database, can persist data and recover from data loss. We’ll also talk about how Redis optimizes memory storage costs using Redis on Flash.
Then, we will see very interesting use cases of scaling Redis and replicating it across multiple geographic regions. Finally, since one of the most popular platforms for running micro-services is Kubernetes, and since running stateful applications in Kubernetes is a bit challenging, we will see how you can easily run Redis on Kubernetes.
What Is Redis?
Redis, which actually stands for Remote Dictionary Server, is an in-memory database. So many people have used it as a cache on top of other databases to improve the application performance. However, what many people don’t know is that Redis is a fully fledged primary database that can be used to store and persist multiple data formats for complex applications.
Complex Social Media Application Example
Let’s look at a common setup for a microservices application. Let’s say we have a complex social media application with millions of users. And let’s say our microservices application uses a relational database like MySQL to store the data. In addition, because we are collecting tons of data daily, we have an Elasticsearch database for fast filtering and searching the data.
Now, the users are all connected to each other, so we need a graph database to represent these connections. Plus, our application has a lot of media content that users share with each other daily, and for that, we have a document database. Finally, for better application performance, we have a cache service that caches data from other databases and makes it accessible faster.
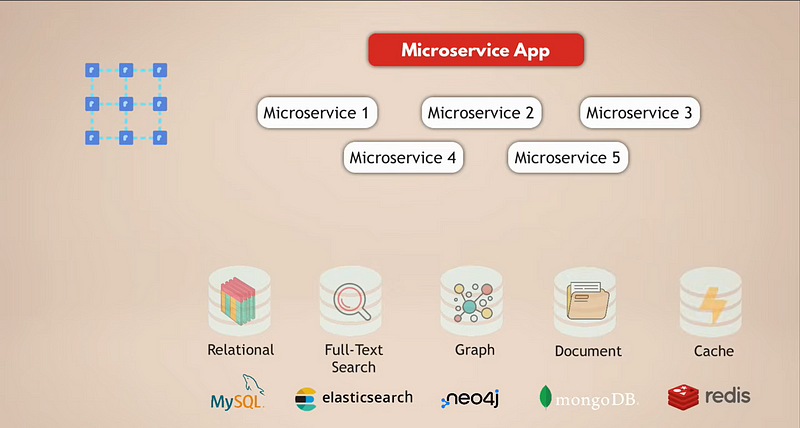
Now, it’s obvious that this is a pretty complex setup. Let’s see what the challenges of this setup are:
1. Deployment and Maintenance
All these data services need to be deployed, run, and maintained. This means your team needs to have some kind of knowledge of how to operate all these data services.
2. Scaling and Infrastructure Requirements
For high availability and better performance, you would want to scale your services. Each of these data services scales differently and has different infrastructure requirements, and that could be an additional challenge. So overall, using multiple data services for your application increases the effort of maintaining your whole application setup.
3. Cloud Costs
Of course, as an easier alternative to running and managing the services yourself, you can use the managed data services from cloud providers. But this could be very expensive because, on cloud platforms, you pay for each managed data service separately.
4. Development Complexity
5. Higher Latency
Why Redis Simplifies This Complexity
In comparison with a multi-modal database like Redis, you resolve most of these challenges:
- Single data service. You run and maintain just one data service. So your application also needs to talk to a single data store, which means only one programmatic interface for that data service.
- Reduced latency. Latency will be reduced by going to a single data endpoint and eliminating several internal network hops.
- Multiple data types in one. Having one database like Redis that allows you to store different types of data (i.e., multiple types of databases in one) as well as act as a cache solves such challenges.
How Redis Supports Multiple Data Formats
So, let’s see how Redis actually works. First of all, how does Redis support multiple data formats in a single database?
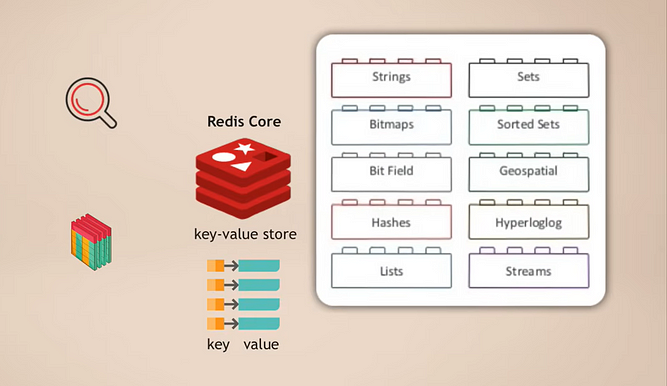
Redis Core and Modules
The way it works is that you have Redis core, which is a key-value store that already supports storing multiple types of data. Then, you can extend that core with what’s called modules for different data types, which your application needs for different purposes. For example:
- RedisSearch for search functionality (like Elasticsearch)
- RedisGraph for graph data storage
A great thing about this is that it’s modular. These different types of database functionalities are not tightly integrated into one database as in many other multi-modal databases, but rather, you can pick and choose exactly which data service functionality you need for your application and then basically add that module.
Built-In Caching
And, of course, when using Redis as a primary database, you don’t need an additional cache because you have that automatically out of the box with Redis. That means, again, less complexity in your application because you don’t need to implement the logic for managing, populating, and invalidating the cache.
High Performance and Faster Testing
Finally, as an in-memory database, Redis is super fast and performant, which, of course, makes the application itself faster. In addition, it also makes running the application tests way faster, as well, because Redis doesn’t need a schema like other databases. So it doesn’t need time to initialize the database, build the schema, and so on before running the tests. You can start with an empty Redis database every time and generate data for tests as you need. Fast tests can really increase your development productivity.
Data Persistence in Redis
We understood how Redis works and all its benefits. But at this point, you may be wondering: How can an in-memory database persist data? Because if the Redis process or the server on which Redis is running fails, all the data in memory is gone, right? And if I lose the data, how can I recover it? So basically, how can I be confident that my data is safe?
The simplest way to have data backups is by replicating Redis. So, if the Redis master instance goes down, the replicas will still be running and have all the data. If you have a replicated Redis, the replicas will have the data. But of course, if all the Redis instances go down, you will lose the data because there will be no replica remaining.
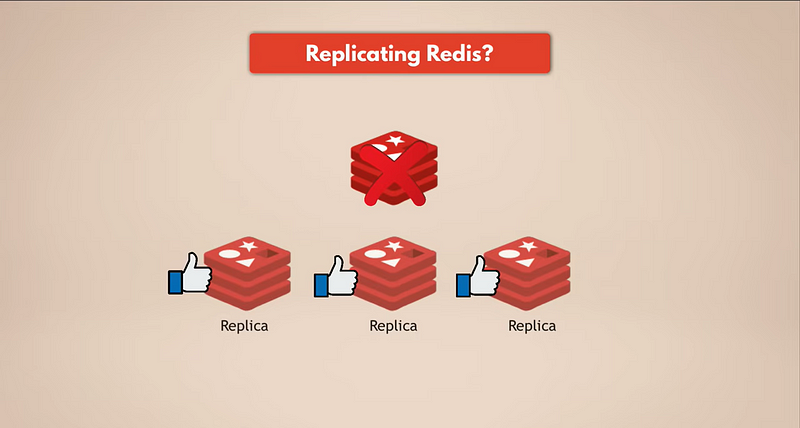
We need real persistence.
Snapshot (RDB)
Redis has multiple mechanisms for persisting the data and keeping the data safe. The first one is snapshots, which you can configure based on time, number of requests, etc. Snapshots of your data will be stored on a disk, which you can use to recover your data if the whole Redis database is gone. But note that you will lose the last minutes of data, because you usually do snapshotting every five minutes or an hour, depending on your needs.
AOF (Append Only File)
As an alternative, Redis uses something called AOF, which stands for Append Only File. In this case, every change is saved to the disk for persistence continuously. When restarting Redis or after an outage, redis will replay the Append Only File logs to rebuild the state. So, AOF is more durable but can be slower than snapshotting.
Combination of Snapshots and AOF
And, of course, you can also use a combination of both AOF and snapshots, where the append-only file is persisting data from memory to disk continuously, plus you have regular snapshots in between to save the data state in case you need to recover it. This means that even if the Redis database itself or the servers, the underlying infrastructure where Redis is running, all fail, you still have all your data safe and you can easily recreate and restart a new Redis database with all the data.
Where Is This Persistent Storage?
A very interesting question is, where is that persistent storage? So where is that disk that holds your snapshots and the append-only file logs located? Are they on the same servers where Redis is running?
This question actually leads us to the trend or best practice of data persistence in cloud environments, which is that it’s always better to separate the servers that run your application and data services from the persistent storage that stores your data.
With a specific example: If your applications and services run in the cloud on, let’s say, an AWS EC2 instance, you should use EBS or Elastic Block Storage to persist your data instead of storing them on the EC2 instance’s hard drive. Because if that EC2 instance dies, you won’t have access to any of its storage, whether it’s RAM or disk storage or whatever. So, if you want persistence and durability for your data, you must put your data outside the instances on an external network storage.
As a result, by separating these two, if the server instance fails or if all the instances fail, you still have the disk and all the data on it unaffected. You just spin up other instances and take the data from the EBS, and that’s it. This makes your infrastructure way easier to manage because each server is equal; you don’t have any special servers with any special data or files on it. So you don’t care if you lose your whole infrastructure because you can just recreate a new one and pull the data from a separate storage, and you’re good to go again.
Going back to the Redis example, the Redis service will be running on the servers and using server RAM to store the data, while the append-only file logs and snapshots will be persisted on a disk outside those servers, making your data more durable.
Cost Optimization With Redis on Flash
Now we know you can persist data with Redis for durability and recovery while using RAM or memory storage for great performance and speed. So the question you may have here is: Isn’t storing data in memory expensive? Because you would need more servers compared to a database that stores data on disk simply because memory is limited in size. There’s a trade-off between the cost and performance.
Well, Redis actually has a way to optimize this using a service called Redis on Flash, which is part of Redis Enterprise.
How Redis on Flash Works
It’s a pretty simple concept, actually: Redis on Flash extends the RAM to the flash drive or SSD, where frequently used values are stored in RAM and the infrequently used ones are stored on SSD. So, for Redis, it’s just more RAM on the server. This means that Redis can use more of the underlying infrastructure or the underlying server resources by using both RAM and SSD drive to store the data, increasing the storage capacity on each server, and this way saving you infrastructure costs.
Scaling Redis: Replication and Sharding
We’ve talked about data storage for the Redis database and how it all works, including the best practices. Now another very interesting topic is how do we scale a Redis database?
Replication and High Availability
Let’s say my one Redis instance runs out of memory, so data becomes too large to hold in memory, or Redis becomes a bottleneck and can’t handle any more requests. In such a case, how do I increase the capacity and memory size of my Redis database?
We have several options for that. First of all, Redis supports clustering, which means you can have a primary or master Redis instance that can be used to read and write data, and you can have multiple replicas of that primary instance for reading the data. This way, you can scale Redis to handle more requests and, in addition, increase the high availability of your database. If the master fails, one of the replicas can take over, and your Redis database can basically continue functioning without any issues.
These replicas will all hold copies of the data of the primary instance. So, the more replicas you have, the more memory space you need. And one server may not have sufficient memory for all your replicas. Plus, if you have all the replicas on one server and that server fails, your whole Redis database is gone, and you will have downtime. Instead, you want to distribute these replicas among multiple nodes or servers. For example, your master instance will be on one node and two replicas on the other two nodes.
Sharding for Larger Datasets
Well, that seems good enough, but what if your data set grows too large to fit in memory on a single server? Plus, we have scaled the reads in the database, so all the requests basically just query the data, but our master instance is still alone and still has to handle all the writes. So, what is the solution here?
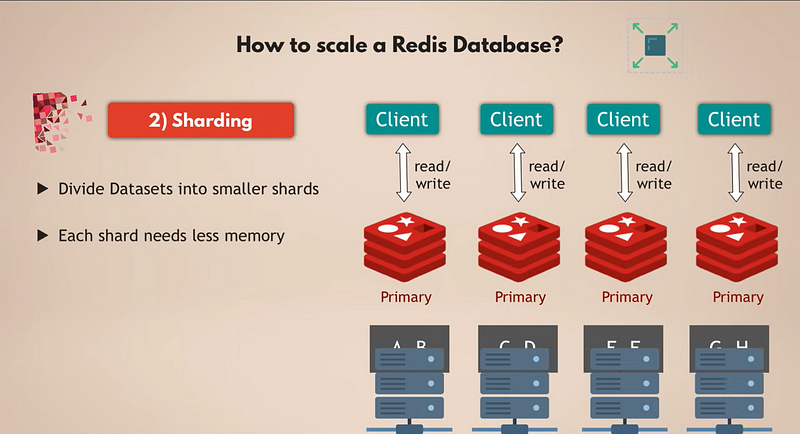
For that, we use the concept of sharding, which is a general concept in databases and which Redis also supports. Sharding basically means that you take your complete data set and divide it into smaller chunks or subsets of data, where each shard is responsible for its own subset of data.
That means instead of having one master instance that handles all the writes to the complete data set; you can split it into, let’s say, four shards, each of them responsible for reads and writes to a subset of the data. Each shard also needs less memory capacity because it just has a fourth of the data. This means you can distribute and run shards on smaller nodes and basically scale your cluster horizontally. And, of course, as your data set grows and as you need even more resources, you can re-shard your Redis database, which basically means you just split your data into even smaller chunks and create more shards.
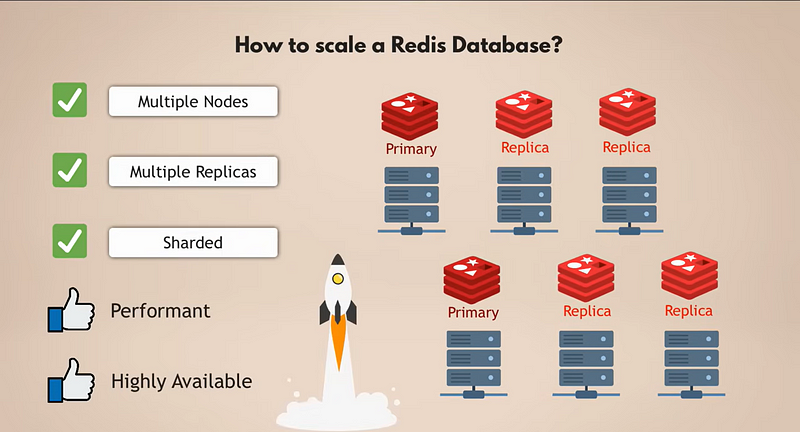
So having multiple nodes that run multiple replicas of Redis, which are all sharded, gives you a very performant, highly available Redis database that can handle many more requests without creating any bottlenecks.
Now, I have to note here that this setup is great, but you would need to manage it yourself, do the scaling, add nodes, do the sharding, and then resharding, etc. For some teams that are more focused on application development and more business logic rather than running and maintaining data services, this could be a lot of unwanted effort. So, as an easier alternative, in Redis Enterprise, you get this kind of setup automatically because the scaling, sharding, and so on are all managed for you.
Global Replication With Redis: Active-Active Deployment
Let’s consider another interesting scenario for applications that need even higher availability and performance across multiple geographic locations. So let’s say we have this replicated, sharded Redis database cluster in one region, in the data center of London, Europe. But we have the two following use cases:
- Our users are geographically distributed, so they are accessing the application from all over the world. We want to distribute our application and data services globally, close to the users, to give our users better performance.
- If the complete data center in London, Europe, for example, goes down, we want an immediate switch-over to another data center so that the Redis service stays available. In other words, we want replicas of the whole Redis cluster in data centers in multiple geographic locations or regions.
Multiple Redis Clusters Across Regions
This means a single data should be replicated to many clusters spread across multiple regions, with each cluster being fully able to accept reads and writes. In that case, you would have multiple Redis clusters that will act as local Redis instances in each region, and the data will be synced across these geographically distributed clusters. This is a feature available in Redis Enterprise and is called active-active deployment because you have multiple active databases in different locations.
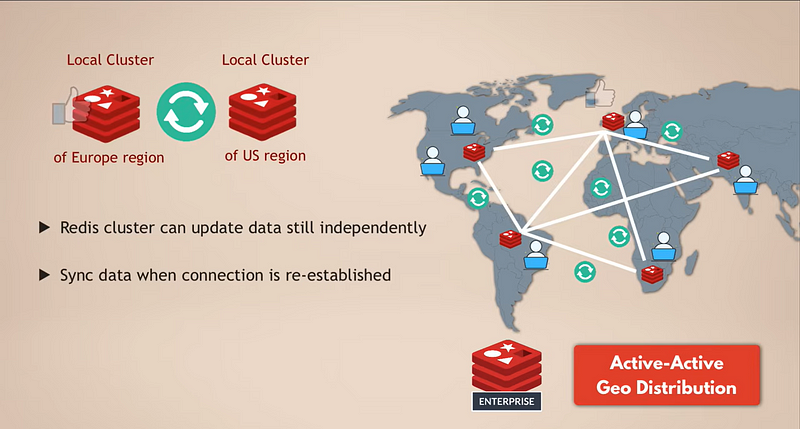
With this setup, we’ll have lower latency for the users. And even if the Redis database in one region completely goes down, the other regions will be unaffected. If the connection or syncing between the regions breaks for a short time because of some network problem, for example, the Redis clusters in these regions can update the data independently, and once the connection is re-established, they can sync up those changes again.
Conflict Resolution With CRDTs
Now, of course, when you hear that, the first question that may pop up in your mind is: How does Redis resolve the changes in multiple regions to the same data set? So, if the same data changes in multiple regions, how does Redis make sure that data changes of any region aren’t lost and data is correctly synced, and how does it ensure data consistency?
Specifically, Redis Enterprise uses a concept called CRDTs, which stands for conflict-free replicated Data types, and this concept is used to resolve any conflicts automatically at the database level and without any data loss. So basically, Redis itself has a mechanism for merging the changes that were made to the same data set from multiple sources in a way that none of the data changes are lost and any conflicts are properly resolved. And since, as you learned, Redis supports multiple data types, each data type uses its own data conflict resolution rules, which are the most optimal for that specific data type.
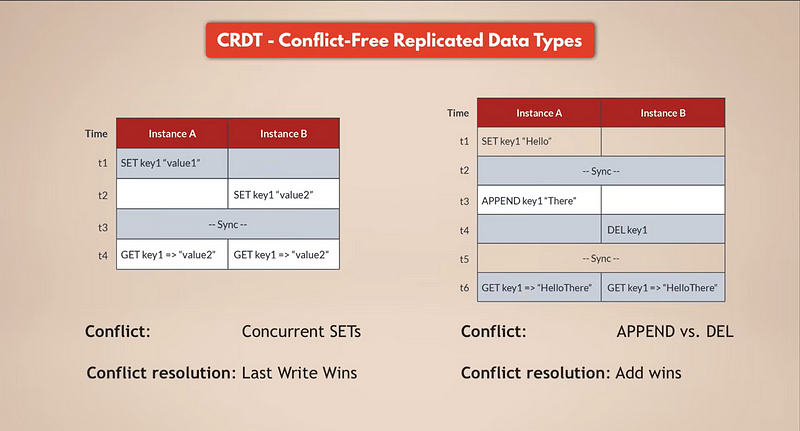
Simply put, instead of just overriding the changes of one source and discarding all the others, all the parallel changes are kept and intelligently resolved. Again, this is automatically done for you with this active-active geo-replication feature, so you don’t need to worry about that.
Running Redis in Kubernetes
And the last topic I want to address with Redis is running Redis in Kubernetes. As I said, Redis is a great fit for complex micro-services that need to support multiple data types and that need an easy scaling of a database without worrying about data consistency. And we also know that the new standard for running microservices is the Kubernetes platform. So, running Redis in Kubernetes is a very interesting and common use case. So how does that work?
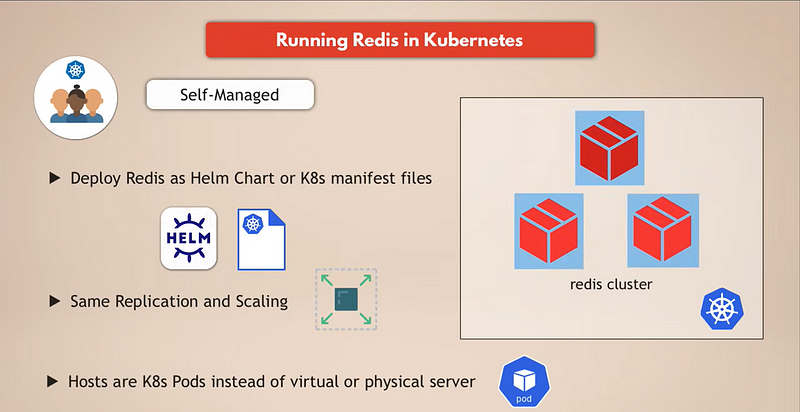
Open Source Redis on Kubernetes
With open-source Redis, you can deploy replicated Redis as a Helm chart or Kubernetes manifest files and, basically, using the replication and scaling rules that we already talked about, set up and run a highly available Redis database. The only difference would be that the hosts where Redis will run will be Kubernetes pods instead of, for example, EC2 instances or any other physical or virtual servers. But the same sharding, replicating, and scaling concepts apply here as well when you want to run a Redis cluster in Kubernetes, and you would basically have to manage that setup yourself.
Redis Enterprise Operator
However, as I mentioned, many teams don’t want to make the effort to maintain these third-party services because they would rather invest their time and resources in application development or other tasks. So, having an easier alternative is important here as well. Redis Enterprise has a managed Redis cluster, which you can deploy as a Kubernetes operator.
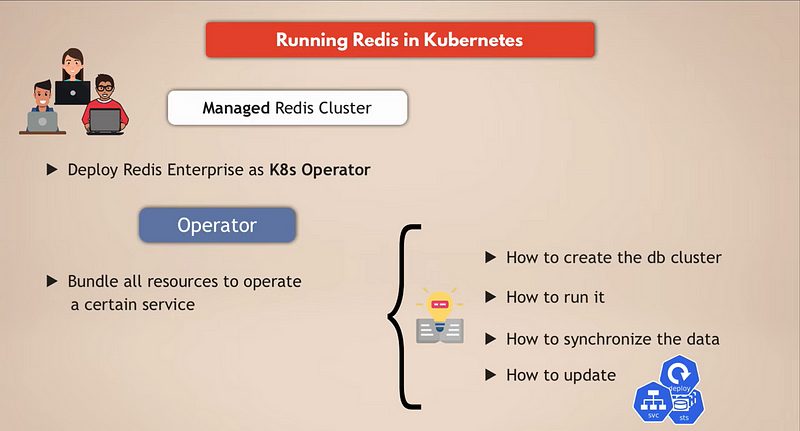
If you don’t know operators, an operator in Kubernetes is basically a concept where you can bundle all the resources needed to operate a certain application or service so that you don’t have to manage it yourself or you don’t have to operate it yourself. Instead of a human operating a database, you basically have all this logic in an automated form to operate a database for you. Many databases have operators for Kubernetes, and each such operator has, of course, its own logic based on who wrote them and how they wrote them.
The Redis Enterprise on Kubernetes operator specifically automates the deployment and configuration of the whole Redis database in your Kubernetes cluster. It also takes care of scaling, doing the backups, and recovering the Redis cluster if needed, etc. So, it takes over the complete operation of the Redis cluster inside the Kubernetes cluster.
Conclusion
I hope you learned a lot in this blog and that I was able to answer many of your questions. If you want to learn more similar technologies and concepts, then make sure to follow me because I write blogs regularly about AI, DevOps, and cloud technologies.
Also, comment below if you have any questions regarding Redis or any new topic suggestions. And with that, thank you for reading, and see you in the next blog.
Let’s connect on LinkedIn!
Published at DZone with permission of Mohammed Talib. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments