Replicate Postgres Data to Kafka
This tutorial will teach you how to easily migrate data from a Postgres database to Apache Kafka using Airbyte open-source.
Join the DZone community and get the full member experience.
Join For FreeData engineers are tasked to move data from a source system to a destination system. For data to move between different systems, there should be a data integration tool that can effectively communicate with both the source and destination systems and ensure data is transferred between these systems.
For small-scale projects where large volumes of data are not being processed, the communication between these systems can be through a network protocol like TCP or IP. For large-scale projects where the processing of huge volumes of data and scalability is paramount, communication can be through a message broker.
Airbyte is an open-source data integration tool that enables you to move data between various systems effortlessly, with low latency and high throughput. This tutorial will teach you how to easily migrate data from a Postgres database to Apache Kafka using Airbyte open-source.

What Is a Message Broker?
Message broker systems came about as a result of the need for systems to communicate with each other effectively. Without message brokers, communication between multiple source and destination systems would be difficult. The diagram below shows six systems trying to communicate with each other.
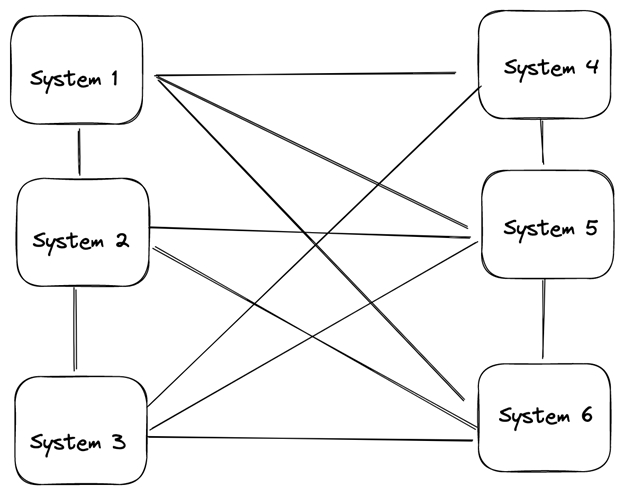
In the architecture shown above, this system can be very challenging to manage. If one system is unavailable at a point, data is lost for that system. Also, it can be very difficult to ensure that each of these systems is using the same data format or communicating via the same language.
Another problem arising from this architecture is that it cannot scale. When the number of source and destination systems increases rapidly, each system must maintain a separate connection with other systems, which can be difficult to manage.
This is one of the problems a message broker solves. Message brokers act as an intermediate between source systems and destination systems. Using message brokers, messages are transported from the source system to the message broker, and the message broker routes the appropriate messages to the appropriate destination.
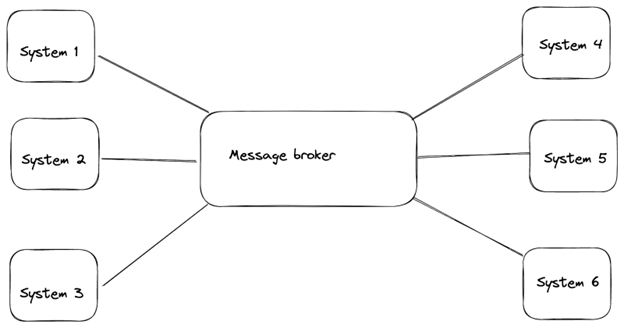
This architecture is easier to manage and scale compared to the one shown previously. If a system is down, the message broker stores the messages in a queue. When the system comes back up, the message broker pushes the messages to the system. In this way, data is preserved. Examples of message brokers are Apache Kafka, RabbitMQ, and Apache Qpid, amongst others.
What Is Apache Kafka?
Apache Kafka is a distributed publish-subscribe (pub-sub) messaging system. This pub-sub system decouples senders and receivers of messages. Here, producers send messages to a Kafka topic. Consumers can then subscribe to one or more Kafka topics and consume messages persisting on the topic. One of the advantages of Apache Kafka is the decoupled architecture. Producers only need to know the topic they will send messages. Similarly, consumers only need to know the topic they can subscribe to. The producers and consumers send and receive messages via the Apache Kafka topic.
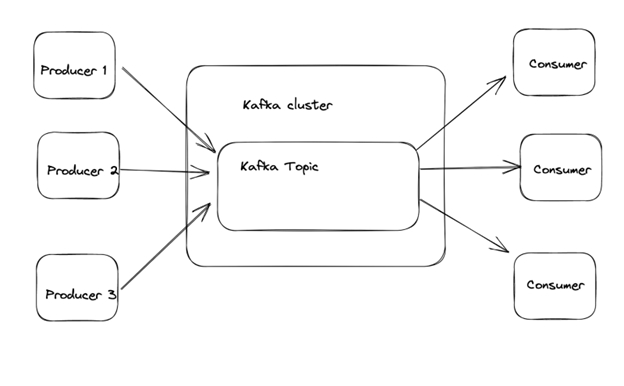
Why Replicate Data From Postgres to Kafka?
Now, you understand what message brokers are and why we need them. One question you might have in mind is, “Why do I need to replicate data from Postgres to Kafka?” There are numerous reasons why this is important. One of the reasons is fast and distributed data processing. Sometimes, data needs to be processed as soon as it is generated. One use case of this is fraud detection. Banking systems or e-commerce applications need to detect fraudulent transactions as soon as they happen. For this, data needs to be migrated from their transactional database system to Kafka.
Another reason data can be replicated from Postgres to Kafka is for data backup. Apache Kafka is a highly scalable, distributed, and fault-tolerant event streaming tool. Most times, large organizations need a backup mechanism to recover data in case of failure, downtime, or disaster. Apache Kafka ensures that the data is available even if your system is unavailable at a particular point in time.
Another reason to replicate data to Kafka is for increased scalability. The decoupled architecture of Apache Kafka makes it easy to distribute data across multiple consumers. This allows your data to scale horizontally across multiple nodes.
Prerequisites
Here are the tools you need to replicate data from a Postgres database to Apache Kafka.
- You will need to have docker and docker-compose installed locally.
- You will need a Postgres database instance you can connect to.
- You need to have Apache Kafka installed locally and configured.
Set up Airbyte Using Docker
You can install Airbyte locally by using just three simple commands. These commands can be run on your terminal.
When the command executes, you will see an Airbyte banner, as in the image below.
When this banner shows, you can navigate to the URL. At first login, you will be asked for a username and password. By default, the username is airbyte, and the password is password. You can change this in the .env file in your local Airbyte directory.
Set up Postgres
After installing Airbyte using Docker, the next step is to install Postgres. You can install Postgres for your operating system by using the link. After installing Postgres and configuring it, you will have to create a database. You can create a database by running the command shown below in your Postgres query editor or the psql terminal.
In this tutorial, the database that was created has the name postgres_kafka.
Create a Postgres Table and Populate the Table
In this section, you will create a table in Postgres and populate the table with data. The data used in this tutorial is an open-source dataset of credit card transactions. This dataset can be downloaded here. The dataset used in this tutorial contains 19,963 records and 15 attributes.
After downloading the dataset, you can create a schema and table for it by executing the command below.
The code block above creates a schema called postgres_kafka_schema and a table of name postgres_kafka_table. This table will be populated with the data in the CSV you just downloaded. To populate the table with the CSV file, you will head over to the psql terminal and run the command:
After executing this code block, the data will be successfully loaded into the Postgres database. You can preview the loaded data by executing the code:
You can also get information on the count of rows in the table by executing the command:
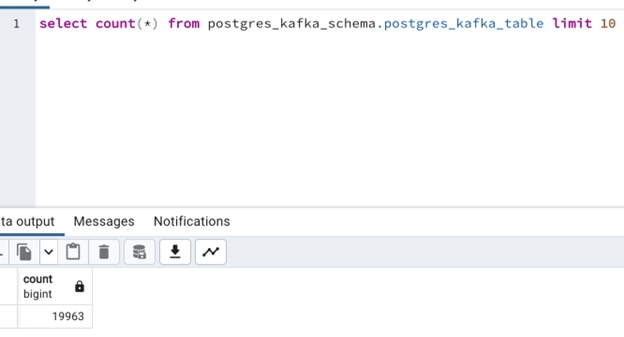
Set up Apache Kafka
In the previous section, you loaded the dataset into the Postgres database. This section will teach you how to spin up a Kafka broker locally.
To spin up a Kafka broker locally without using docker, you will have to go to the directory of your installed Kafka and run the command.
Apache Kafka uses Zookeeper to coordinate various components in the Kafka cluster. Zookeeper stores the configuration information for Apache Kafka, such as the location of partitions, topics configuration, etc. You can spin up a Zookeeper server by executing the command.
The commands shown above spins up both Kafka broker and Zookeeper cluster. Now, you have to create a Kafka topic. A Kafka topic receives messages from the producer(in this case, Postgres) and sends the messages to any consumer subscribed to it.
To create a Kafka topic, you can run the command.
An alternative to this is using Docker to spin up the Zookeeper and Kafka clusters. You can spin up the clusters by executing the command docker compose up on this GitHub repository.
You can then create your Kafka topic by executing the command.
In this case, the topic created has the name postgres_kafka_topic.
Set up Postgres Source Connection
To create the Postgres source, head over to Airbyte on localhost:8000 and create a new source. Enter the source name, host address, database name, the schema you created (postgres_kafka_schema), username, and password. All these details were used when creating your Postgres database.
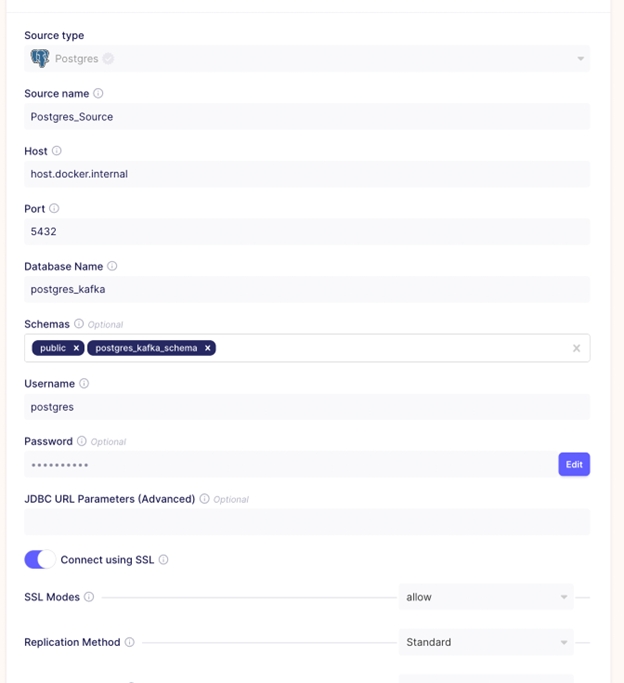
In the image above, you created a Postgres source connection. If you use the default SSL mode of disable, your test might fail. You will get an error message of Unsecured connection. To solve this error, you will have to set SSL Modes to require. SSL Modes are ways of ensuring a secure browser connection. All data connections in Airbyte are encrypted.
Set up Kafka Destination
In the previous section, you set up a Postgres source connection. In this section, you will set up a Kafka destination in Airbyte to stream records from Postgres. In the Airbyte UI, select Destinations > new destination, and Kafka as the type.
While selecting the Kafka destination, you put in your topic name bootstrap server, and for simplicity, leave the remaining values as the default.
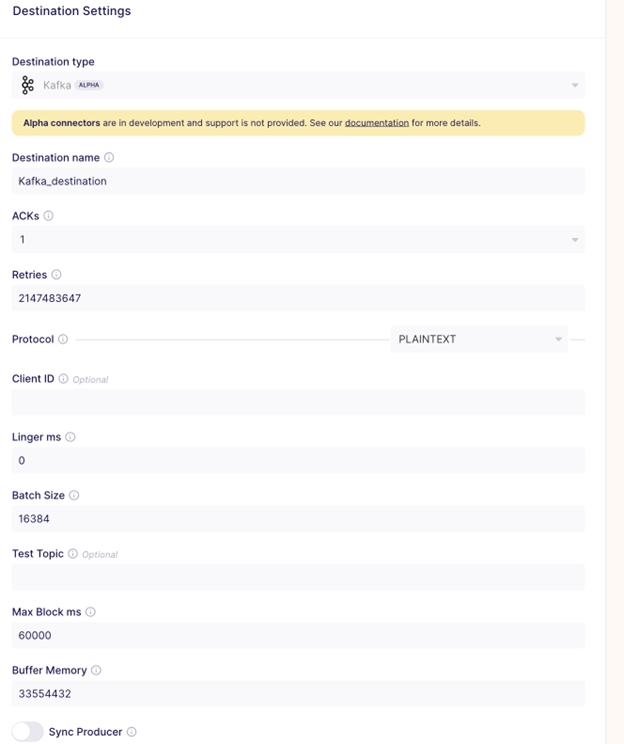
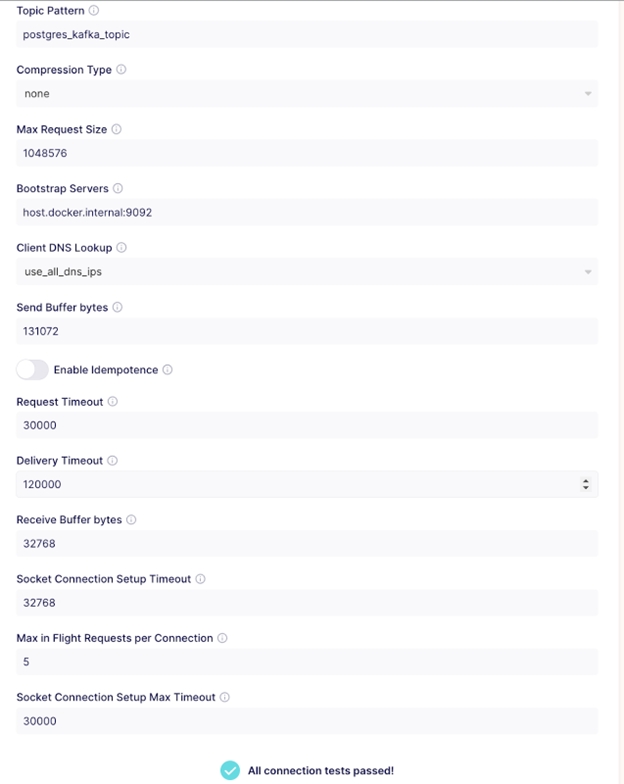
Set up a Postgres to Kafka Connection
Once the source and destination settings have been configured, the next thing to do is to go to Airbyte UI and set up a connection.
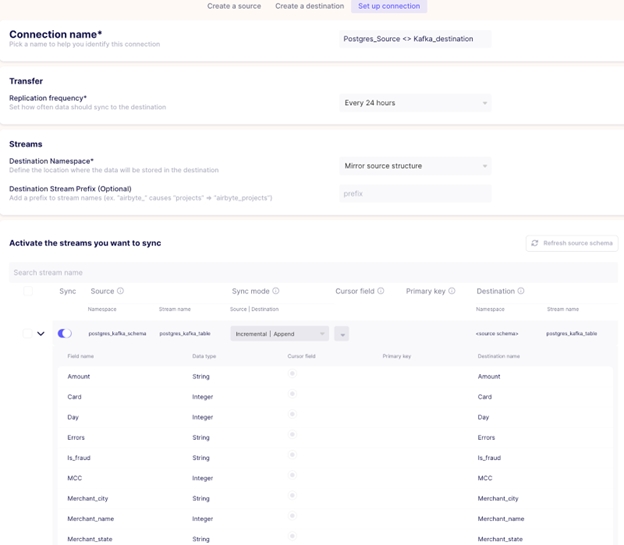
In this use case, incremental | append sync mode was used. There are various sync modes available in Airbyte. You can read more about sync modes by clicking here.
Verify the Results
After creating the Postgres to Kafka connection, the next thing you do is to run the sync.

From the image above, the sync was successful, and exactly 19,963 records were synced from the Postgres database to Apache Kafka. Recall previously, 19,963 records was the total number of records in the dataset. The time it took for this sync to run was exactly twenty-one seconds.
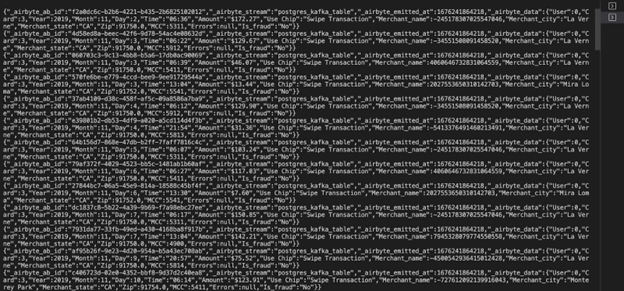
You see that Airbyte migrates data from a source to a destination in a very fast and optimized manner. To verify the results in Kafka, you can consume the messages in the Kafka topic by executing the command.
The image below is a snapshot of the data streamed to the Kafka topic.
Wrapping Up
In this tutorial, you have learned about message brokers and how easy it is to replicate data from a Postgres database to a Kafka topic using Airbyte.
Speed is vital for any organization. By transferring data to a distributed system like Kafka, organizations can improve their data processing speed and scalability. This can aid organizations in making better data-driven decisions. By making use of the right tools, organizations can unlock a realm of fast and reliable data processing.
Published at DZone with permission of John Lafleur. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments