Simple Efficient Spring/Kafka Datastreams
Datastreams from Souce via Kafka to Sink done simple, easy to code, efficient to run. Deployed in Kubernetes and written in Java and Kotlin.
Join the DZone community and get the full member experience.
Join For FreeI had the opportunity to work with Spring Cloud Data Flow streams and batches. The streams work in production and perform well. The main streams used Debezium to send the database deltas to Soap endpoints or provided Soap endpoints to write into the database. The events where send via Kafka. Spring Cloud Data Flow also provides a application to manage the streams and jobs.
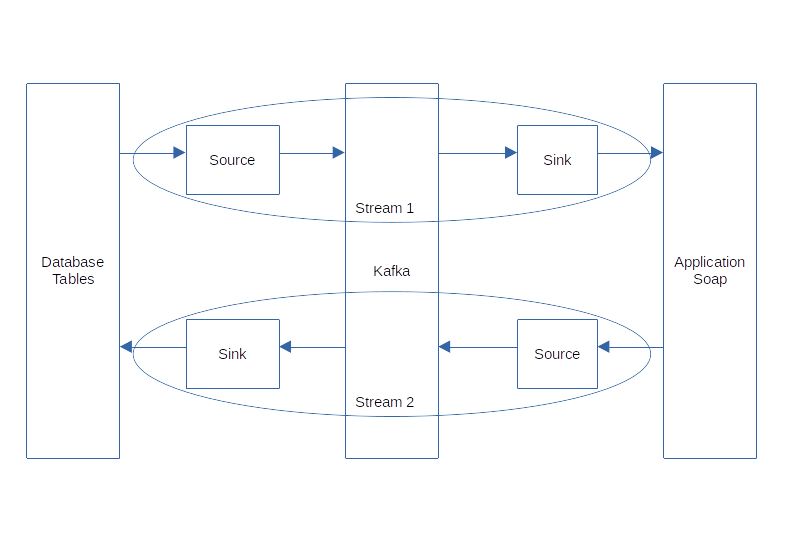
The streams are build with a data source and a data sink that are separate applications and are decoupled by the events send via Kafka. Stream 1 has a Debezium source and sends the database deltas via Kafka to the sink that transforms the event into a soap request to the application. Stream 2 receives a soap request from the application and sends an event to Kafka. The sink receives the event and creates the database entries for the event.
Experiences
Spring Cloud Data Flow is more of an application platform than a framework. It provides Debezium sources that just need to be configured and Kafka needs only to be configured to provide the event content. The management application is able to deploy/start/stop sources and sinks in the Kubernetes cluster. The amount of functionality provided is quite impressive.
The downside is that the configuration becomes complex and dependencies of the configuration properties are hard to understand. The configuration consists of property files for all streams that have to provide the parameters for Db, Kafka, Filter functions and Soap interfaces. The parameter of the property files need to be injected with in environment variables that are set at deployment time. The property files are not type checked and become hard to understand. The stack traces are hard to read due to the reactor based architecture. That makes debugging the configuration complicated and hard to debug. An extreme example was a stream that occasionally has to process more than 100000 changed database rows at once. The source just stopped. Finding the right configuration of Spring Cloud Data Flow properties took days. One of the problems is that Spring Cloud Data Flow is that it is based on Spring Reactor. That makes it very efficient and fast but it is very hard to debug because of its asynchronous nature and hard to read stack traces.
Conclusion
With Spring Cloud Data Flow the provided flexibility needs a lot of configuration and little coding is needed. The configuration is hard to debug because of hard to read stack traces caused by Spring Reactor. Because of that I ask the question:
Is this the right architecture for medium sized use cases?
New Architecture
First, the basic ideas of a new approach to create data flow streams:
- Use Virtual Threads instead of Spring Reactor.
- Use one Spring Boot application for source and sink to save memory.
- Keep Kafka as the streaming platform.
- Use more Java code than configuration to integrate data sources and sinks.
Since Java 21 LTS, Virtual Threads are stable, and with Java 25 LTS the synchronized issues will be solved. They are already addressed in Java 24, but that is not an LTS version. Virtual Threads provide efficient thread use like Spring Reactor while offering readable stack traces and an easier programming model.
A Spring Boot application with the JVM uses quite a bit of memory (384 MB or more). Having separate applications for source and sink would require twice the amount and provide little benefit. Therefore, a single Spring Boot application is created for source and sink. The JVM with Virtual Threads ensures efficient thread usage.
Kafka is used to decouple the processing speed of the source from the processing speed of the sink. This decoupling is necessary if the sink cannot keep up with the source. In that case, Kafka stores the events until the sink has caught up.
The Spring Boot application uses the Spring projects Spring for Kafka, Spring Data JPA, Spring Web (REST), and Spring Web Services. Integration of Kafka, SOAP, REST, and the database (JPA, Debezium) is handled via Java code. Using code enables the use of annotations and library functions that are type-checked, making debugging much easier than a configuration-based approach. This means that the code for sending and receiving Kafka events exists in every stream; the alternative would be far more complex. This trade-off is accepted for simplicity.
Deployment to Kubernetes is done with a Helm chart instead of a graphical application. This approach simplifies deployment. With Helm, the streams can be easily parameterized, enabling flexible adaptation and use of this architecture.
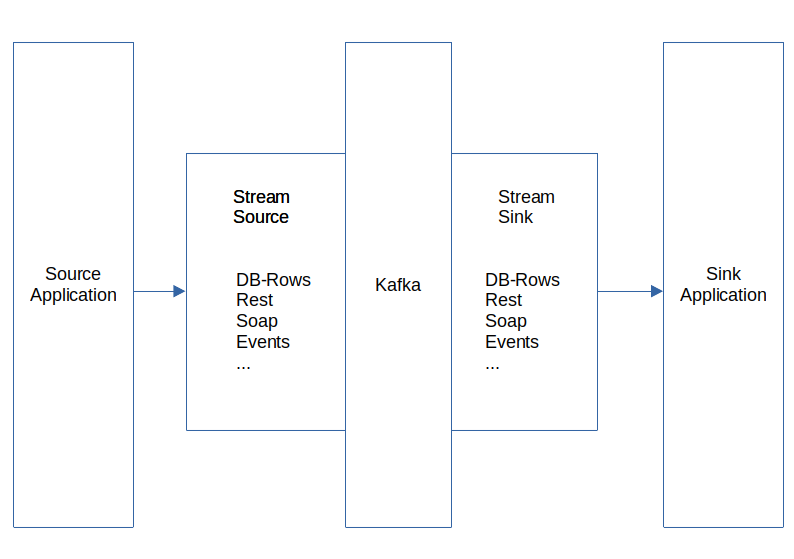
Conclusion
The new architecture has its own trade offs. Simplicity is prioritized and some code duplication is accepted to be able to use native Spring for Kafka. A Kubernetes node will be able to run more streams because sources and sinks now share a Jvm and use less memory. Virtual Threads solve the thread starvation issues. The performance will be bound to Kafka or the application that the sink calls -> IO bound.
Implementation
To demonstrate this, the SimpleDataStreamPipelines project is created. It has 4 parts:
SourceSink
This SourceSink Spring Boot application serves as source and sink for the DataStreamPipelines. It can generate database rows, SOAP requests, and other events for the SimpleDataStreamPipelines.
DatabaseToRest
This Spring Boot application is a DataStreamPipeline that uses Debezium to monitor changed rows of a database via Kafka to a Rest interface. It contains the source and the sink of the DataStream.
Datastream Source
The source of the DataStream uses Debezium to watch a table and turn the row changes into events in the DebeziumRunner class:
@EventListener
public void onEvent(ApplicationReadyEvent event) {
...
try{
this.engine = DebeziumEngine.create(Json.class)
.using(props)
.notifying(myRecord -> {
this.dbChangeSourceService.sendChange(new DbChangeDto(myRecord.key(),
myRecord.value(), myRecord.destination(), myRecord.partition()));
}).build();
this.executor.execute(this.engine);
} catch (Exception e) {
throw new RuntimeException(e);
}
}The onEvent(...) method is called when the Spring Boot application is ready to run. Then the properties for Debezium are set (omitted here). Next, the Debezium engine is started, and the method notifying(...) is used to create a DbChangeDto record and send it to the DbChangeSourceService method sendChange(...). The Debezium engine needs an Executor and is run in a SingleThreadExecutor because multithreading is not needed in this case.
The DbChangeSourceService sends the DTOs to Kafka:
@Service
@Transactional
public class DbChangeSourceService {
private static final Logger LOGGER =
LoggerFactory.getLogger(DbChangeSourceService.class);
private final KafkaProducer kafkaProducer;
public DbChangeSourceService(KafkaProducer kafkaProducer) {
this.kafkaProducer = kafkaProducer;
}
public void sendChange(DbChangeDto dbChangeDto) {
this.kafkaProducer.sendDbChangeMsg(dbChangeDto);
}
}The sendChange(...) method sends the DbChangeDto with the KafkaProducer to Kafka.
The KafkaProducer sends the DTOs to Kafka:
@Component
public class KafkaProducer {
private static final Logger LOGGER =
LoggerFactory.getLogger(KafkaProducer.class);
private final KafkaTemplate<String, String> kafkaTemplate;
private final ObjectMapper objectMapper;
private final AdminClient adminClient;
public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate,
AdminClient adminClient, ObjectMapper objectMapper) {
this.adminClient = adminClient;
this.kafkaTemplate = kafkaTemplate;
this.objectMapper = objectMapper;
}
public void sendDbChangeMsg(DbChangeDto dbChangeDto) {
try {
String msg = this.objectMapper.writeValueAsString(dbChangeDto);
CompletableFuture<SendResult<String, String>> listenableFuture =
this.kafkaTemplate.send(KafkaConfig.ORDERPRODUCT_TOPIC,
dbChangeDto.key(), msg);
listenableFuture.get(15, TimeUnit.SECONDS);
} catch (Exception e) {
throw new RuntimeException("Send OrderProduct failed.", e);
}
LOGGER.info("send OrderProduct msg: {}", dbChangeDto.toString());
}
}The method sendDbChangeMsg(...) first turns the DTO into a JSON string using the ObjectMapper. Then a CompletableFuture is created to send the message to the ORDERPRODUCT_TOPIC topic. The CompletableFuture is then used to send the message with a timeout of 2 seconds.
The sink of the data stream receives the Kafka events and sends them to a REST endpoint of the SourceSink application.
Datastream Sink
The sink of the data stream uses the KafkaConsumer to receive the Kafka events:
@Component
@Transactional
public class KafkaConsumer {
private static final Logger LOGGER =
LoggerFactory.getLogger(KafkaConsumer.class);
private final ObjectMapper objectMapper;
private final DbChangeSinkService dbChangeSinkService;
private final KafkaTemplate<String,String> kafkaTemplate;
public KafkaConsumer(ObjectMapper objectMapper,
DbChangeSinkService dbChangeSinkService,
KafkaTemplate<String,String> kafkaTemplate) {
this.objectMapper = objectMapper;
this.dbChangeSinkService = dbChangeSinkService;
this.kafkaTemplate = kafkaTemplate;
}
@RetryableTopic(kafkaTemplate = "kafkaRetryTemplate", attempts = "3",
backoff = @Backoff(delay = 1000, multiplier = 2.0),
autoCreateTopics = "true", topicSuffixingStrategy =
TopicSuffixingStrategy.SUFFIX_WITH_INDEX_VALUE)
@KafkaListener(topics = KafkaConfig.ORDERPRODUCT_TOPIC)
public void consumerForCountryTopic(String message) {
try {
DbChangeDto dto = this.objectMapper.readValue(message,
DbChangeDto.class);
this.dbChangeSinkService.handleDbChange(dto);
} catch (Exception e) {
LOGGER.warn("send failed orderproduct-topic [{}]", message);
this.sendToDefaultDlt(new KafkaEventDto(KafkaConfig.DEFAULT_DLT_TOPIC,
message));
}
}
@DltHandler
public void consumerForDlt(String in,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic) {
LOGGER.info(in + " from " + topic);
}
private boolean sendToDefaultDlt(KafkaEventDto dto) {
try {
CompletableFuture<SendResult<String, String>> listenableFuture =
this.kafkaTemplate.send(KafkaConfig.DEFAULT_DLT_TOPIC,
UUID.randomUUID().toString(),
this.objectMapper.writeValueAsString(dto));
listenableFuture.get(3, TimeUnit.SECONDS);
} catch (InterruptedException | ExecutionException | TimeoutException |
JsonProcessingException e) {
throw new RuntimeException(e);
}
LOGGER.info("Message send to {}. {}", KafkaConfig.DEFAULT_DLT_TOPIC,
dto.toString());
return true;
}
}The method consumerForCountryTopic(...) is called for Kafka events sent to the ORDERPRODUCT_TOPIC topic. It includes retry logic with incremental backoff in case of failure to process the event. The ObjectMapper is used to convert the message into a DTO, and then the method handleDbChange(...) of the DbChangeSinkService is called to process the DTO.
In case of failure to process the event, the method sendToDefaultDlt(...) is called, which sends the DTO to the Dead Letter Topic. The method consumerForDlt(...) handles the messages from the Dead Letter Topic and logs them.
The DbChangeSinkService sends the DTOs to the REST endpoint:
@Service
public class DbChangeSinkService {
private static final Logger LOG =
LoggerFactory.getLogger(DbChangeSinkService.class);
private final ObjectMapper objectMapper;
private final RestClient restClient = RestClient.create();
@Value("${rest.endpoint.url}")
private String restEndpointUrl;
public DbChangeSinkService(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
}
public void handleDbChange(DbChangeDto dbChangeDto) {
Wrapper wrapper;
try {
wrapper = this.objectMapper.readValue(dbChangeDto.value(),
Wrapper.class);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
this.restClient.post().uri(this.restEndpointUrl.trim()
+ "/rest/orderproduct").contentType(MediaType.APPLICATION_JSON)
.body(wrapper).retrieve().toBodilessEntity();
}
}The method handleDbChange(...) maps the DTO to the REST DTO and posts it using the RestClient to the REST endpoint of the SourceSink application.
SoapToDb
This Spring Boot application is a DataStreamPipeline that uses the jaxb2-maven-plugin Maven plugin to create a SOAP interface and send the received messages via Kafka to a sink that stores the data in the database. It contains both the source and the sink of the DataStream.
DataStream Source
The Maven plugin is configured in the pom.xml file:
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>jaxb2-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<id>xjc</id>
<goals>
<goal>xjc</goal>
</goals>
</execution>
</executions>
<configuration>
<sources>
<source>
${project.basedir}/src/main/resources/xsd/countries.xsd
</source>
</sources>
</configuration>
</plugin>
</plugins>
</build>The plugin creates classes to use for the interface and places them in the target directory based on the countries.xsd file.
To configure the SOAP endpoint, the WebServiceConfig class is used:
@EnableWs
@Configuration
public class WebServiceConfig extends WsConfigurerAdapter {
@Bean
public ObjectMapper createObjectMapper() {
ObjectMapper mapper = new ObjectMapper();
mapper.registerModule(new JavaTimeModule());
mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
return mapper;
}
@Bean
public ServletRegistrationBean<MessageDispatcherServlet>
messageDispatcherServlet(ApplicationContext applicationContext) {
MessageDispatcherServlet servlet = new MessageDispatcherServlet();
servlet.setApplicationContext(applicationContext);
servlet.setTransformWsdlLocations(true);
return new ServletRegistrationBean<>(servlet, "/ws/*");
}
@Bean(name = "countries")
public DefaultWsdl11Definition defaultWsdl11Definition(XsdSchema
countriesSchema) {
DefaultWsdl11Definition wsdl11Definition = new DefaultWsdl11Definition();
wsdl11Definition.setPortTypeName("CountriesPort");
wsdl11Definition.setLocationUri("/ws");
wsdl11Definition.setTargetNamespace(
"http://www.baeldung.com/springsoap/gen");
wsdl11Definition.setSchema(countriesSchema);
return wsdl11Definition;
}
@Bean
public XsdSchema countriesSchema() {
return new SimpleXsdSchema(new ClassPathResource("xsd/countries.xsd"));
}
}First, the web services are enabled by annotation. The method messageDispatcherServlet(...) creates and configures the MessageDispatcherServlet used to process the SOAP requests. The method defaultWsdl11Definition(...) sets up the XML schema, URI, and namespace for this endpoint. The method countriesSchema() returns the SimpleXsdSchema wrapper for the schema XSD file.
The SOAP endpoint is created with the CountryEndpoint class:
@Endpoint
public class CountryEndpoint {
private static final Logger log =
LoggerFactory.getLogger(CountryEndpoint.class);
private static final String NAMESPACE_URI =
"http://www.baeldung.com/springsoap/gen";
private final CountrySourceService countryService;
public CountryEndpoint(CountrySourceService countryService,
KafkaProducer kafkaProducer) {
this.countryService = countryService;
}
@PayloadRoot(namespace = NAMESPACE_URI, localPart = "getCountryRequest")
@ResponsePayload
public GetCountryResponse getCountry(
@RequestPayload GetCountryRequest request) {
GetCountryResponse response = new GetCountryResponse();
var country = countryService.sendCountry(request.getName());
response.setCountry(country);
return response;
}
}First, the endpoint is created by annotation. The method getCountry(...) processes SOAP requests based on @PayloadRoot with the namespace and the localPart in the annotation. The @ResponsePayload annotation is needed for the SOAP response. The @RequestPayload annotation is used to map the request parameter into the request variable. Within the method, the response variable is created, and the CountryService is used to convert the country name into a country object for the response.
The CountrySourceService class creates the responses and sends the events:
@Service
@Transactional
public class CountrySourceService {
private static final Logger log =
LoggerFactory.getLogger(CountrySourceService.class);
private static final Map<String, Country> countries = new HashMap<>();
private final KafkaProducer kafkaSender;
public CountrySourceService(KafkaProducer kafkaClient) {
this.kafkaSender = kafkaClient;
}
@PostConstruct
public void initData() {
Country spain = new Country();
spain.setName("Spain");
spain.setCapital("Madrid");
spain.setCurrency(WsCurrency.EUR);
spain.setPopulation(46704314);
countries.put(spain.getName(), spain);
...
}
public Country sendCountry(String name) {
Assert.notNull(name, "The country's name must not be null");
var country = countries.get(name);
var myCountry = new CountryDto(country);
this.kafkaSender.sendCountryMsg(myCountry);
return country;
}
}The method initData() creates response objects and stores them in a HashMap. The @PostConstruct annotation ensures it runs before any request is processed.
The method sendCountry(...) first checks that the country name is not null. Then the response DTO and Kafka event DTO are created. The Kafka event is sent with the KafkaProducer and the response DTO is returned.
Datastream Sink
The Kafka event is received by the KafkaConsumer and behaves the same as in the DatabaseToRest stream. The CountrySinkService class is called by the KafkaConsumer:
@Service
@Transactional
public class CountrySinkService {
private static final Logger log =
LoggerFactory.getLogger(CountrySinkService.class);
private final CountryRepository countryRepository;
public CountrySinkService(CountryRepository countryRepository) {
this.countryRepository = countryRepository;
}
@EventListener
public void init(ApplicationReadyEvent event) {
this.countryRepository.deleteAll();
}
public void handleReceivedCountry(CountryDto countryDto) {
log.info("CountryDto: {}", countryDto.toString());
this.countryRepository.save(this.map(countryDto));
}
private Country map(CountryDto dto) {
var entity = new Country();
entity.setCapital(dto.getCapital());
entity.setCurrency(dto.getCurrency().value());
entity.setPopulation((long) dto.getPopulation());
entity.setName(dto.getName());
return entity;
}
}The method init(...) uses the @EventListener annotation to run when the application is up and ready. It then deletes all country entries written in previous runs.
The method handleReceivedCountry(...) is called by the KafkaConsumer and logs the DTO. It then maps the DTO to the country entity and stores it in the database with the CountryRepository.
EventToFile
This Spring Boot application is a DataStreamPipeline that uses a Kafka Topic as the data source to demonstrate how to handle messages as input for a DataStream. The source receives the messages, turns them into events, and sends them to Kafka. The sink receives the events and turns them into JSONs that are stored as files. It contains both the source and sink of the DataStream.
Datastream Source
The messages are received by the KafkaConsumer. Compared to the other DataStreams, it has a second KafkaListener:
@RetryableTopic(kafkaTemplate = "kafkaRetryTemplate", attempts = "3",
backoff = @Backoff(delay = 1000, multiplier = 2.0),
autoCreateTopics = "true", topicSuffixingStrategy =
TopicSuffixingStrategy.SUFFIX_WITH_INDEX_VALUE)
@KafkaListener(topics = KafkaConfig.FLIGHT_SOURCE_TOPIC)
public void consumerForFlightSourceTopic(String message) {
try {
var dto = this.objectMapper.readValue(message, FlightSourceDto.class);
this.flightSourceService.handleFlightSourceEvent(dto);
} catch (Exception e) {
LOGGER.warn("send failed consumerForFlightSourceTopic [{}]", message);
this.sendToDefaultDlt(new KafkaEventDto(KafkaConfig.DEFAULT_DLT_TOPIC,
message));
}
}The method consumerForFlightSourceTopic(...) is a Kafka event listener that retries the events on failure. The event is then turned into a DTO, and the FlightSourceService method handleFlightSourceEvent(...) is called to process the event. If event processing fails, the event is sent to the Dead Letter Queue.
The FlightSourceService handles the messages:
@Transactional
@Service
public class FlightSourceService {
private static final Logger log =
LoggerFactory.getLogger(FlightSourceService.class);
private final KafkaProducer kafkaProducer;
private final ObjectMapper objectMapper;
public FlightSourceService(KafkaProducer kafkaProducer,
ObjectMapper objectMapper) {
this.kafkaProducer = kafkaProducer;
this.objectMapper = objectMapper;
}
public void handleFlightSourceEvent(FlightSourceDto flightSourceDto) {
this.kafkaProducer.sendFlightMsg(this.map(flightSourceDto));
}
private FlightDto map(FlightSourceDto dto) {
return new FlightDto(dto.id(), dto.from(), dto.to(), dto.length(),
dto.airline(), dto.price());
}
private void logDto(FlightSourceDto flightSourceDto) {
try {
log.info(this.objectMapper.writeValueAsString(flightSourceDto));
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
}The method handleFlightSourceEvent(...) maps the message DTO into a Kafka event and sends it with the KafkaProducer method sendFlightMsg(...).
DataStream Sink
The FlightSinkService is used to handle the Kafka events:
@Transactional
@Service
public class FlightSinkService {
private static final Logger log =
LoggerFactory.getLogger(FlightSinkService.class);
private final ObjectMapper objectMapper;
public FlightSinkService(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
}
@PostConstruct
public void init() {
var tempDir = new File(System.getProperty("java.io.tmpdir"));
var filesToDelete = tempDir.listFiles(((dir, name) ->
name.matches("Flight-.+")));
Stream.of(filesToDelete).forEach(File::delete);
log.info("Deleted {} files.", filesToDelete.length);
}
public void handleFlightEvent(FlightDto flightDto) {
var tempDirectory = System.getProperty("java.io.tmpdir")+File.separator;
try {
BufferedWriter writer = new BufferedWriter(
new FileWriter(tempDirectory+"Flight-"+flightDto.id().toString()));
writer.write(this.objectMapper.writeValueAsString(flightDto));
writer.close();
log.info("File written: {}",
tempDirectory+"Flight-"+flightDto.id().toString());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}The method init() is called after the service is ready because of the @PostConstruct annotation. It deletes all the files left by the previous run of the stream.
The method handleFlightEvent(...) is called by the KafkaConsumer to handle the events. It first finds the tmp directory, then creates a buffered file writer that writes files in the format ${tempDir}/Flight-${flightUUID}. The ObjectMapper is used to turn the DTO into a JSON string, which is then written to the file and logged.
Because of the UUID in the filename, writing with multiple threads is safe: file name collisions are extremely unlikely, and each file is separate instead of appending to a single file.
Conclusion Implementation
The Streams look like this:
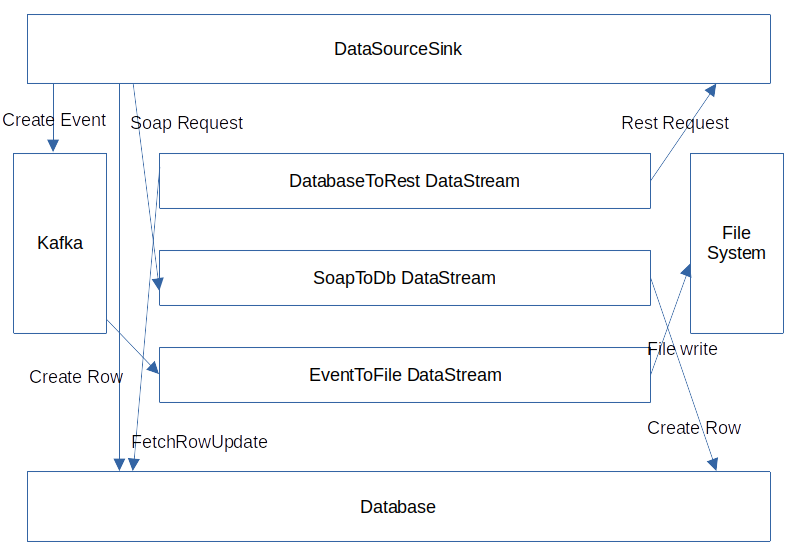
The DatabaseToRest DataStream shows how to listen to table row changes and write them to a REST endpoint.
The SoapToDb DataStream shows how to listen for SOAP requests and write them to a database.
The EventToFile DataStream shows how to listen to events/messages and write them to the file system.
The implementation of the streams is simple because it uses standard Spring with Java. The configuration of Kafka is duplicated in the DataStreams to enable the use of readable annotations and code. These annotations and code are type-checked by the compiler to detect issues. Performance and efficiency are handled by virtual threads. The use of JPA for database writes makes the DataStream portable across different databases and fast enough for all use cases that do not require detailed performance profiling (performance issues usually have an unexpected cause).
Helm Deployment in Kubernetes
The components of the DataStream system are deployed in Minikube, a locally runnable Kubernetes cluster that is easy to use on a single computer. The system is deployed to Kubernetes using a Helm chart. A Helm chart was chosen because it provides all the necessary features and is easy to understand and extend.
The Helm chart handles parameterization and scripting required to deploy all Docker images of the system. Each system component has a Dockerfile to create its Docker image, and the images are hosted on DockerHub. The deployed pods include:
Kafka(using KRaft)PostgreSQLSourceSinkapplicationDatabaseToRestDataStreamEventToFileDataStreamSoapToDbDataStream
Infrastructure
The KRaft-based Kafka Docker image is used because it can be deployed without Zookeeper. This means that for development, a single Docker image is sufficient, and in Kubernetes, one less image needs to be configured.
PostgreSQL is a free, performant relational database that is mature, easy to use, and has a well-maintained Docker image. To work with Debezium, the wal_level must be set to logical, which can be provided as a runtime parameter to the Docker image.
The SourceSink Spring Boot application generates the database changes, SOAP requests, and events that the DataStreams receive. It also provides the endpoint for REST requests. The application includes the actuator starter to support Kubernetes probes.
DataStreams
The DataStreams are Spring Boot applications that include the actuator starter to support Kubernetes probes. Their Docker images are used to deploy the applications to Kubernetes.
Helm Chart
The Helm chart is located in the helm directory of the project. Commands to set up the Minikube cluster can be found in the minikube.sh file. Commands to install and delete the Helm chart are provided in the helm.sh file.
The values.yaml:
sourceSinkAppName: sourcesinkapp
dbName: postgresserver
...
dbImageName: postgres
dbImageVersion: 16
volumeClaimName: postgres-pv-claim
persistentVolumeName: task-pv-volume
dbServiceName: postgresservice
...
databaseToRestAppName: databasetorestapp
databaseToRestImageName: angular2guy/dbtorest
databaseToRestImageVersion: latest
databaseToRestServiceName: databasetorestservice
...
kafkaName: kafkaapp
kafkaImageName: bitnami/kafka
kafkaImageVersion: latest
kafkaServiceName: kafkaservice
secret:
nameSourceSink: source-sink-env-secret
nameDb: db-env-secret
nameKafka: kafka-env-secret
nameSoapToDb: soap-to-db-env-secret
nameDatabaseToRest: database-to-rest-env-secret
nameEventToFile: event-to-file-env-secret
envKafka:
normal:
KAFKA_CFG_NODE_ID: 0
KAFKA_CFG_PROCESS_ROLES: controller,broker
KAFKA_CFG_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093
KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP:
CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
KAFKA_CFG_CONTROLLER_QUORUM_VOTERS: 0@kafkaservice:9093
KAFKA_CFG_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_SERVER_NAME: kafkaserver
KAFKA_SERVICE_NAME: kafkaservice
envDb:
normal:
POSTGRES_URL: "jdbc:postgresql://postgresservice:5432/datastream"
POSTGRES_DB: datastream
POSTGRES_SERVER: postgresservice
secret:
POSTGRES_USER: dbuser
POSTGRES_PASSWORD: passwordtoreplace
...
envDatabaseToRest:
normal:
JPA_SHOW_SQL: false
SHUTDOWN_PHASE: 10s
SPRING_PROFILES_ACTIVE: "prod"
KAFKA_SERVICE_NAME: kafkaservice
secret:
POSTGRES_USER: dbuser
POSTGRES_PASSWORD: passwordtoreplace
POSTGRES_SERVER: postgresservice
POSTGRES_DB: datastream
POSTGRES_URL: "jdbc:postgresql://postgresservice:5432/datastream"
REST_ENDPOINT_URL: "http://sourcesinkservice:8080"The file has been shortened to avoid repetitions. First, the variables are declared. Then, secret entries are defined for the sensitive values in the environments. After that, the environments are configured. They provide the applications with both public and secret parameters as environment variables.
- The
envKafkaenvironment contains the public variables required for Kafka with KRaft to operate. - The
envDatabaseToRestenvironment contains the public and secret variables required for theDatabaseToRestDataStream to function.
The file _helpers.tpl contains the scripts used by the Helm templates.
...
{{/*
Create databaseToRestApp values
*/}}
{{- define "helpers.list-env-database-to-rest-variables"}}
{{- $secretName := .Values.secret.nameDatabaseToRest -}}
{{- range $key, $val := .Values.envDatabaseToRest.secret }}
- name: {{ $key }}
valueFrom:
secretKeyRef:
name: {{ $secretName }}
key: {{ $key }}
{{- end}}
{{- range $key, $val := .Values.envDatabaseToRest.normal }}
- name: {{ $key }}
value: {{ $val | quote }}
{{- end}}
{{- end }}
...The file has been shortened to avoid repetitions. This script demonstrates helpers.list-env-database-to-rest-variables, which converts the values in values.yaml into secretKeyRef entries for secret variables and into name/value pairs for public variables. Each environment has a similar script.
The file kubTemplate.yaml contains the Helm template used to deploy the system.
...
---
apiVersion: v1
kind: Secret
metadata:
name: {{ .Values.secret.nameDatabaseToRest}}
type: Opaque
data:
{{- range $key, $val := .Values.envDatabaseToRest.secret }}
{{ $key }}: {{ $val | b64enc }}
{{- end}}
---
...
---
kind: PersistentVolume
apiVersion: v1
metadata:
name: {{ .Values.persistentVolumeName }}
labels:
type: local
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
capacity:
storage: 1Gi
hostPath:
path: /data/postgres{{ .Values.dbImageVersion }}
type: DirectoryOrCreate
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: {{ .Values.volumeClaimName }}
labels:
app: postgrespv
spec:
accessModes:
- ReadWriteOnce
# storageClassName: local-storage
storageClassName: manual
resources:
requests:
storage: 1Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.dbName }}
labels:
app: {{ .Values.dbName }}
spec:
replicas: 1
selector:
matchLabels:
app: {{ .Values.dbName }}
template:
metadata:
labels:
app: {{ .Values.dbName }}
spec:
containers:
- name: {{ .Values.dbName }}
image: "{{ .Values.dbImageName }}:{{ .Values.dbImageVersion }}"
env:
{{- include "helpers.list-envDb-variables" . | indent 10 }}
args:
- "-c"
- "wal_level=logical"
resources:
limits:
memory: "2G"
cpu: "1.5"
requests:
memory: "1G"
cpu: "0.5"
ports:
- containerPort: 5432
volumeMounts:
- name: hostvol
mountPath: /var/lib/postgresql/data
volumes:
- name: hostvol
persistentVolumeClaim:
claimName: {{ .Values.volumeClaimName }}
---
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.dbServiceName }}
labels:
app: {{ .Values.dbServiceName }}
spec:
ports:
- port: 5432
protocol: TCP
selector:
app: {{ .Values.dbName }}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.kafkaName }}
labels:
app: {{ .Values.kafkaName }}
spec:
replicas: 1
selector:
matchLabels:
app: {{ .Values.kafkaName }}
template:
metadata:
labels:
app: {{ .Values.kafkaName }}
spec:
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
containers:
- name: {{ .Values.kafkaName }}
image: "{{ .Values.kafkaImageName }}:{{ .Values.kafkaImageVersion }}"
resources:
limits:
memory: "1G"
cpu: "0.7"
requests:
memory: "768M"
cpu: "0.1"
env:
{{- include "helpers.list-envKafka-variables" . | indent 10 }}
ports:
- containerPort: 9092
---
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.kafkaServiceName }}
labels:
app: {{ .Values.kafkaServiceName }}
spec:
ports:
- name: tcp-client
port: 9092
protocol: TCP
- name: tcp-interbroker
port: 9093
protocol: TCP
targetPort: 9093
selector:
app: {{ .Values.kafkaName }}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.sourceSinkAppName }}
labels:
app: {{ .Values.sourceSinkAppName }}
spec:
replicas: 1
selector:
matchLabels:
app: {{ .Values.sourceSinkAppName }}
template:
metadata:
labels:
app: {{ .Values.sourceSinkAppName }}
spec:
containers:
- name: {{ .Values.sourceSinkAppName }}
image: "{{ .Values.sourceSinkImageName }}:{{ .Values.sourceSinkImageVersion }}"
imagePullPolicy: Always
resources:
limits:
memory: "384M"
cpu: "1"
requests:
memory: "256M"
cpu: "0.5"
env:
{{- include "helpers.list-env-source-sink-variables" . | indent 10 }}
ports:
- containerPort: 8080
livenessProbe:
httpGet:
path: "/actuator/health/livenessState"
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
startupProbe:
httpGet:
path: "/actuator/health/readinessState"
port: 8080
failureThreshold: 60
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.sourceSinkServiceName }}
labels:
run: {{ .Values.sourceSinkServiceName }}
spec:
type: NodePort
ports:
- port: 8080
protocol: TCP
selector:
app: {{ .Values.sourceSinkAppName }}
---
...
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.databaseToRestAppName }}
labels:
app: {{ .Values.databaseToRestAppName }}
spec:
replicas: 1
selector:
matchLabels:
app: {{ .Values.databaseToRestAppName }}
template:
metadata:
labels:
app: {{ .Values.databaseToRestAppName }}
spec:
containers:
- name: {{ .Values.databaseToRestAppName }}
image: "{{ .Values.databaseToRestImageName }}:{{ .Values.databaseToRestImageVersion }}"
imagePullPolicy: Always
resources:
limits:
memory: "384M"
cpu: "1"
requests:
memory: "256M"
cpu: "0.5"
env:
{{- include "helpers.list-env-database-to-rest-variables" . | indent 10 }}
ports:
- containerPort: 8081
livenessProbe:
httpGet:
path: "/actuator/health/livenessState"
port: 8081
initialDelaySeconds: 5
periodSeconds: 5
startupProbe:
httpGet:
path: "/actuator/health/readinessState"
port: 8081
failureThreshold: 60
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: {{ .Values.databaseToRestServiceName }}
labels:
run: {{ .Values.databaseToRestServiceName }}
spec:
ports:
- port: 8081
protocol: TCP
selector:
app: {{ .Values.databaseToRestAppName }}
---
...The file has been shortened to avoid repetitions. First, the Secrets are created that are used in the scripts for the Deployments. Then, the PersistentVolume and PersistentVolumeClaim are created for the PostgreSQL Deployment. The PostgreSQL Deployment/Service is created with its environment variables, PersistentVolumeClaim, and a runtime parameter to set wal_level=logical to enable Debezium.
Next, the Kafka platform is created with its Deployment/Service, including environment variables and Services for local communication. Kafka with KRaft requires an extra Service but no longer needs Zookeeper.
Then, the SourceSink Spring Boot application is deployed with its Deployment/Service, environment variables, actuator-based probes, and resource limits. It generates the changes to be processed by the DataStreams and provides an endpoint for the DataStreams.
After that, the DatabaseToRest DataStream is deployed with its Deployment/Service, environment variables, actuator probes, and resource limits. It processes table row changes with Debezium and sends the deltas via Kafka to the Rest endpoint of the SourceSink application. The secrets required by the Deployment are stored in values.yaml, which must be kept in a secure location.
Conclusion
Deployment
The Helm chart provides the deployment of the Kubernetes system with a clear structure that is easy to change and adapt. Parameters are in values.yaml, the deployment template is in kubTemplate.yaml, and supporting scripts are in _helpers.tpl. This structure supports simplicity. The Helm chart can be extended to support more DataStreams, datasources, and datasinks. Kubernetes probes, supported by the Spring Actuator starter, enable automatic restarts if a DataStream encounters a problem. Kubernetes resource limits enable efficient use of hardware resources.
System Design
The Simple DataStreams demonstrate how to create DataStreams with minimal complexity while providing an easy growth path. Features can be added incrementally, and resources are only used as required. Scalability can be handled via Kubernetes resource limits or horizontal scaling if needed.
Compared to Spring Cloud Data Stream, the architecture goal is different:
Less configuration, more implementation, and lower complexity.
Published at DZone with permission of Sven Loesekann. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments