Token-Efficient RAG: Using Query Intent to Reduce Cost Without Losing Accuracy
Retrieval-Augmented Generation (RAG) optimization technique to reduce the number of tokens required to generate a response while maintaining response accuracy.
Join the DZone community and get the full member experience.
Join For FreeIn this article, we will examine the RAG optimization technique to reduce the number of tokens required to generate a response while maintaining response accuracy. Before we dig deeper into RAG, let us review a few basic terms.
What Is an LLM (Large Language Model)?
Large language models (LLMs) are very large deep learning models that are pre-trained on vast amounts of data. They are capable of performing tasks ranging from simple to complex, such as content generation, text classification, text mining, and summarization.
What Is RAG (Retrieval-Augmented Generation)?
Retrieval-Augmented Generation (RAG) is the process of optimizing an LLM’s output by referencing a knowledge base beyond its training data before generating a response. This approach is useful in several scenarios, including accessing a knowledge base, personalizing responses based on user details, and building a search engine.
It works in combination with an LLM to generate responses in a human-readable format. Below are two reference use cases that demonstrate how RAG works.
Vectorization Process Illustration
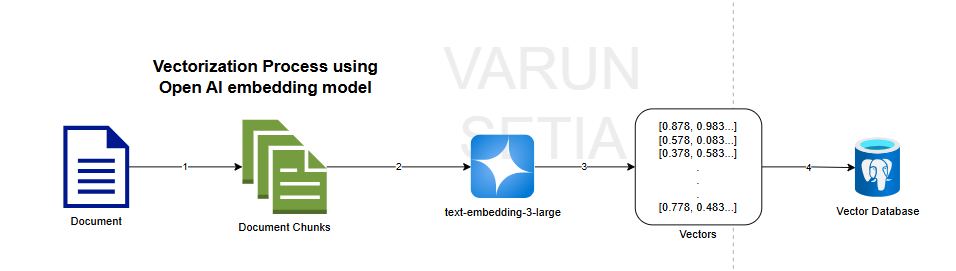
This diagram illustrates the vectorization workflow using an OpenAI embedding model. First, a raw document is taken as input. In step one, the document is split into smaller, manageable chunks to preserve context and improve processing efficiency. In step two, each chunk is sent to the OpenAI embedding model (text-embedding-3-large). The model converts textual meaning into high-dimensional numerical vectors that capture semantic relationships.
In step three, these vectors mathematically represent the document content. Finally, in step four, the generated vectors are stored in a vector database, enabling fast semantic search, similarity matching, and retrieval for downstream AI applications.
Search Engine Working Illustration
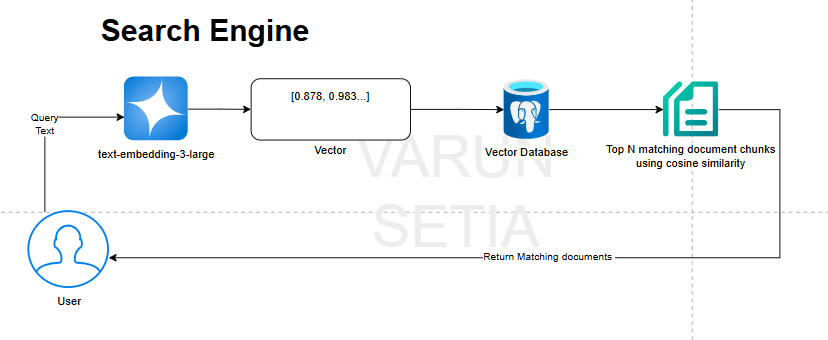
This diagram shows how a semantic search engine works using embeddings. A user enters a query as plain text. The query is converted into a numerical vector using the text-embedding-3-large model, capturing its semantic meaning. This query vector is sent to a vector database that already stores embeddings of document chunks.
The database compares the query vector with stored vectors using cosine similarity to find the most relevant matches. The top N matching document chunks are selected based on similarity scores. Finally, these matching documents are returned to the user as search results, enabling meaning-based search rather than keyword matching.
RAG with LLM Illustration
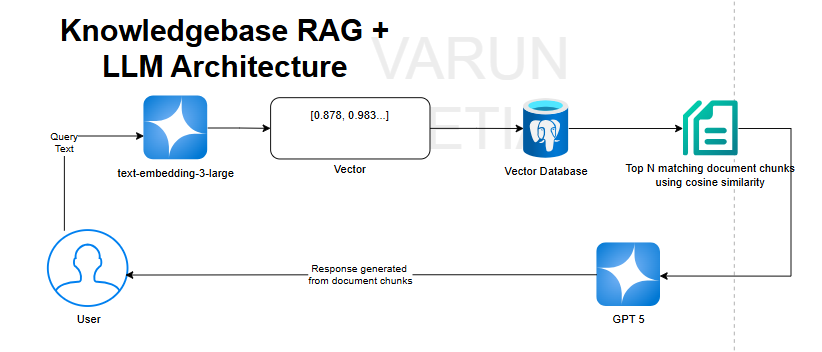
This diagram explains a knowledge base–driven RAG architecture. A user submits a query, which is converted into a semantic vector using the text-embedding-3-large model. This vector is used to search a vector database that stores embeddings of document chunks.
Using cosine similarity, the system retrieves the top N most relevant chunks from the knowledge base. These retrieved chunks are then passed as context to the GPT-5 large language model. Finally, GPT-5 generates a grounded, context-aware response based strictly on the retrieved documents and returns it to the user, combining accurate retrieval with natural language generation.
Key Takeaway
The key insight from the above is that RAG is essentially a modified implementation of how a search engine works. We are simply processing the retrieved response one step further by using an LLM to summarize and generate the final answer.
Optimization Approach
In the above implementation, every time we make a query, we receive N document chunks in response. If we examine this concept more deeply, the number of documents retrieved entirely depends on the nature of the user’s query.
Below are a few examples to better understand this based on query type:
| Query | Nature of Query | Relevant document chunks | Traditional chunks |
Saving |
|---|---|---|---|---|
| What is Microsoft? | Generic | 7 | 7 | 0% |
|
What was the profit margin of Microsoft in Year 2025? |
Contextual |
4 | 7 |
~42% |
|
What was the profit margin of Microsoft in first quarter of Year 2025? |
Very Specific Contextual |
2 | 7 | ~71% |
Based on the nature of the query, we categorize documents into three types — Generic, Contextual, and Very Specific Contextual — and assign maximum document counts of 7, 4, and 2 respectively.
Since the number of retrieved documents varies by query type, the percentage of token savings also varies. The optimal configuration can be achieved by analyzing the specific nature of the use case.
To implement this, we introduce another LLM that determines the nature of the query. We then maintain a dictionary that maps the query type to the corresponding number of relevant documents.
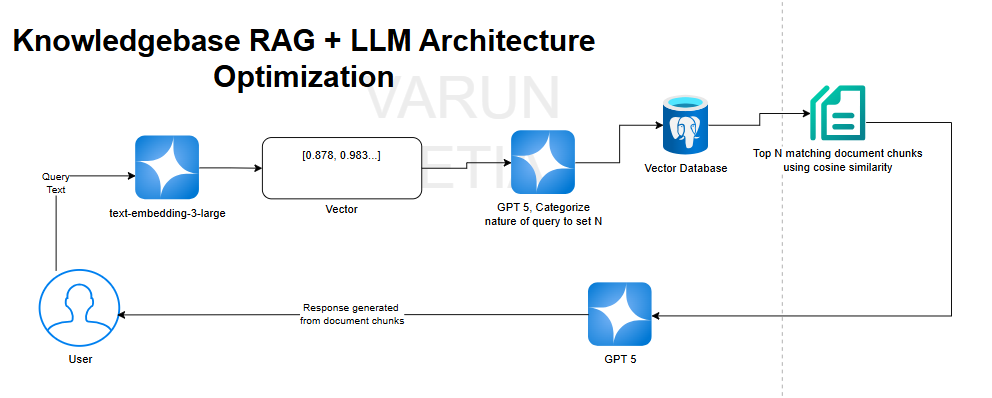
Prompt-Based Classification
To achieve this implementation, we define a system prompt. Let’s focus on the prompt implementation, keeping it relevant to the optimization context of this article. If you’d like a complete working example, feel free to comment, and I can write a detailed code walkthrough.
System Prompt
You are an AI assistant that classifies user input into exactly one of the following three categories: Generic, Contextual, or Very Specific Contextual.
- Generic: The input is broad, high-level, and does not rely on any specific background, constraints, or prior context.
- Contextual: The input includes some background, role, or situational details that guide the response, but still allows flexibility.
- Very Specific Contextual: The input contains detailed constraints such as strict rules, format requirements, tone, role, audience, or explicit do’s and don’ts.
Your task is to analyze the input and return only one category name that best matches it. Do not provide explanations, examples, or additional text. Return only the category label.
Examples:
- Example 1 — What is Microsoft? → Generic
- Example 2 — What was the profit margin of Microsoft in Year 2025? → Contextual
- Example 3 — What was the profit margin of Microsoft in the first quarter of Year 2025? → Very Specific Contextual
Testing Results
I tested this prompt with a few inputs, and the outputs were impressive. The tests were performed using the Gemini 2.5 Flash model.
Input: What is Honda?
Output: Generic
Input: Tell me a few places that I can visit in Paris
Output: Generic
Input: Tell me about the capital city of the United States of America
Output: Contextual
Since the output always falls into one of the three categories, we can easily create a Python dictionary to map each category to the appropriate number of documents.
Below is a simple example demonstrating how this optimization works by combining the classification prompt with a dictionary lookup.
from dotenv import load_dotenv
load_dotenv()
import osdef get_relevantdocs_count(input):
relevant_docs_count_map = {
"Generic":7,
"Contextual":4,
"Very Specific Contextual": 2
}
import requests
import json url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-2.5-flash:streamGenerateContent?alt=sse" payload = json.dumps({
"contents": [
{
"parts": [
{
"text": "Tell me about the capital city of United States of America"
}
]
}
],
"systemInstruction": {
"parts": [
{
"text": "You are an AI assistant that classifies user input into exactly one of the following three categories: Generic, Contextual, or Very Specific Contextual. Generic: The input is broad, high-level, and does not rely on any specific background, constraints, or prior context. Contextual: The input includes some background, role, or situational details that guide the response, but still allows flexibility. Very Specific Contextual: The input contains detailed constraints such as strict rules, format requirements, tone, role, audience, or explicit do’s and don’ts. Your task is to analyze the input and return only one category name that best matches it. Do not provide explanations, examples, or additional text. Return only the category label. Below are 3 examples for reference: Example 1 - What is Microsoft?, Output 1 - Generic; Example 2 - What was the profit margin of Microsoft in Year 2025?, Output 2 - Contextual; Example 3 - What was the profit margin of Microsoft in first quarter of Year 2025?, Output 3 - Very Specific Contextual"
}
]
}
})
headers = {
'x-goog-api-key': os.environ("GOOGLE_API_KEY"),
'Content-Type': 'application/json'
} response = requests.request("POST", url, headers=headers, data=payload)
sanatized_raw = response.text.replace("data: ","")
response = json.loads(sanatized_raw)
category_name = response["candidates"][0]["content"]["parts"][0]["text"]
return relevant_docs_count_map[category_name]relevantdocs_count = get_relevantdocs_count('Tell me about the capital city of United States of America')
print(relevantdocs_count) #Output: 4Conclusion
RAG optimization is not just about better retrieval — it is about retrieving smarter. By understanding the nature of a user’s query before fetching context, we can dynamically control how much information is passed to the LLM, significantly reducing token usage without compromising response accuracy.
Classifying queries into Generic, Contextual, and Very Specific Contextual allows the system to adapt retrieval depth based on intent rather than applying a one-size-fits-all approach. This intent-aware RAG design mirrors how humans search for information and delivers meaningful cost, performance, and latency benefits.
As LLM-powered systems scale, such optimizations will move from being “nice to have” to essential — enabling more efficient, accurate, and production-ready AI applications.
Let me know how you feel about this approach in the comments section.
Thanks for reading till the end! I hope you enjoyed it!!
Published at DZone with permission of Varun Setia. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments