Unsupervised Learning in Data Mining: Apriori Algorithm
Unsupervised learning in data mining for rule association via the Apriori Algorithm.
Join the DZone community and get the full member experience.
Join For FreeThis post will share my knowledge about unsupervised learning in data mining with the simplest algorithm, which we used to generate associated rules to determine the related grocery items customers bought from our e-commerce application/retail stores.
Before jumping ahead, Let’s understand a few terms which I will be using in this article.
- Frequent itemset — Meaning items that are bought together by customers.
- Unsupervised Learning — Predict something without having prior knowledge.
- Sampling — Statistical analysis technique used to select, manipulate and analyze a representative subset of data points to identify patterns
- Noise — Meaningless information Forex. 123 in the list of groceries, which is meaningless.
- Data discretization — converting a huge number of data values into smaller ones
- Pruned — change the model by deleting the nodes/transaction
The name of the algorithm is Apriori because it uses prior knowledge of frequent itemset properties. We apply an iterative approach or level-wise search where k-frequent itemsets are used to find k+1 item sets.
To improve the efficiency of level-wise generation of frequent itemsets, an important property is used called Apriori property which helps by reducing the search space.
Algorithm Says:
- Let k=1
- Generate frequent itemsets of length 1
- Repeat until no new frequent itemsets are identified
- Generate length (k+1) candidate itemsets from length k frequent itemsets
- Prune candidate itemsets containing subsets of length k that are infrequent
- Count the support of each candidate by scanning the DB
- Eliminate candidates that are infrequent, leaving only those that are frequent
Approach
- Sampling — Divide the provided dataset into N datasets either random or using some pattern or shuffling. Repeat execution with multiple random datasets. Compare the Rules generated
- Data processing — Apply Discretization, cleaning on the dataset to remove noisy transactions.
- Generate Item set for the provided transactions with 60% Min Support.
Support(A) = (Transactions containing (A))/(Total Transactions)
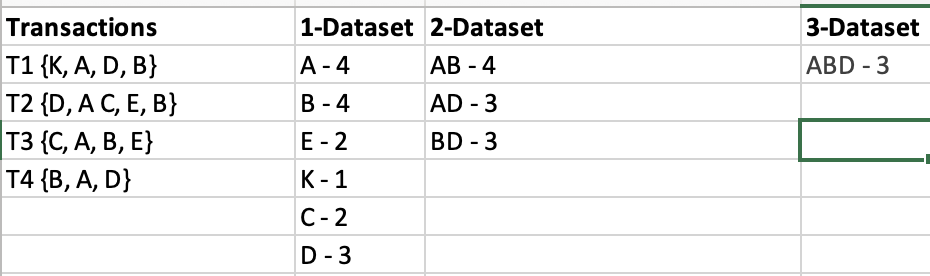
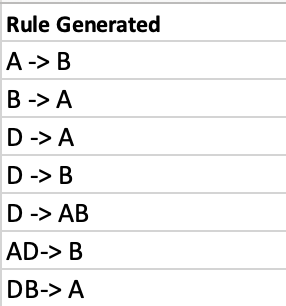
Pruned rules with confidence ≤75%
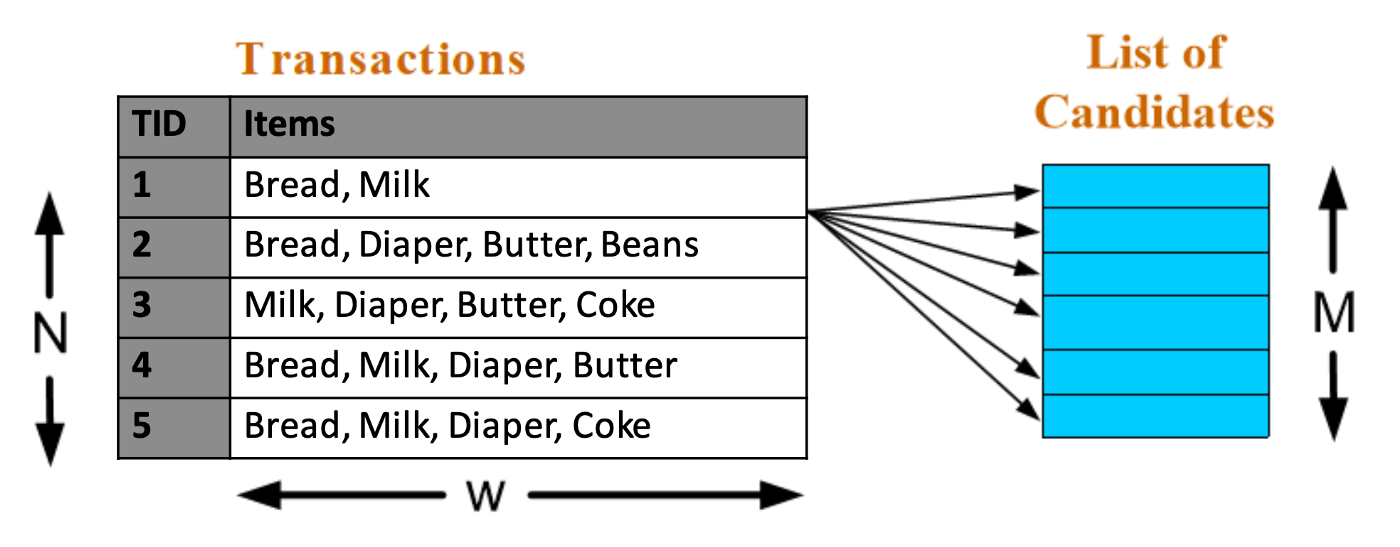
Time Complexity — of generating number of Frequent Itemset is O(NMw)
N — Number of transactions
M — Number of unique items
w — Max number of unique items in a single transaction
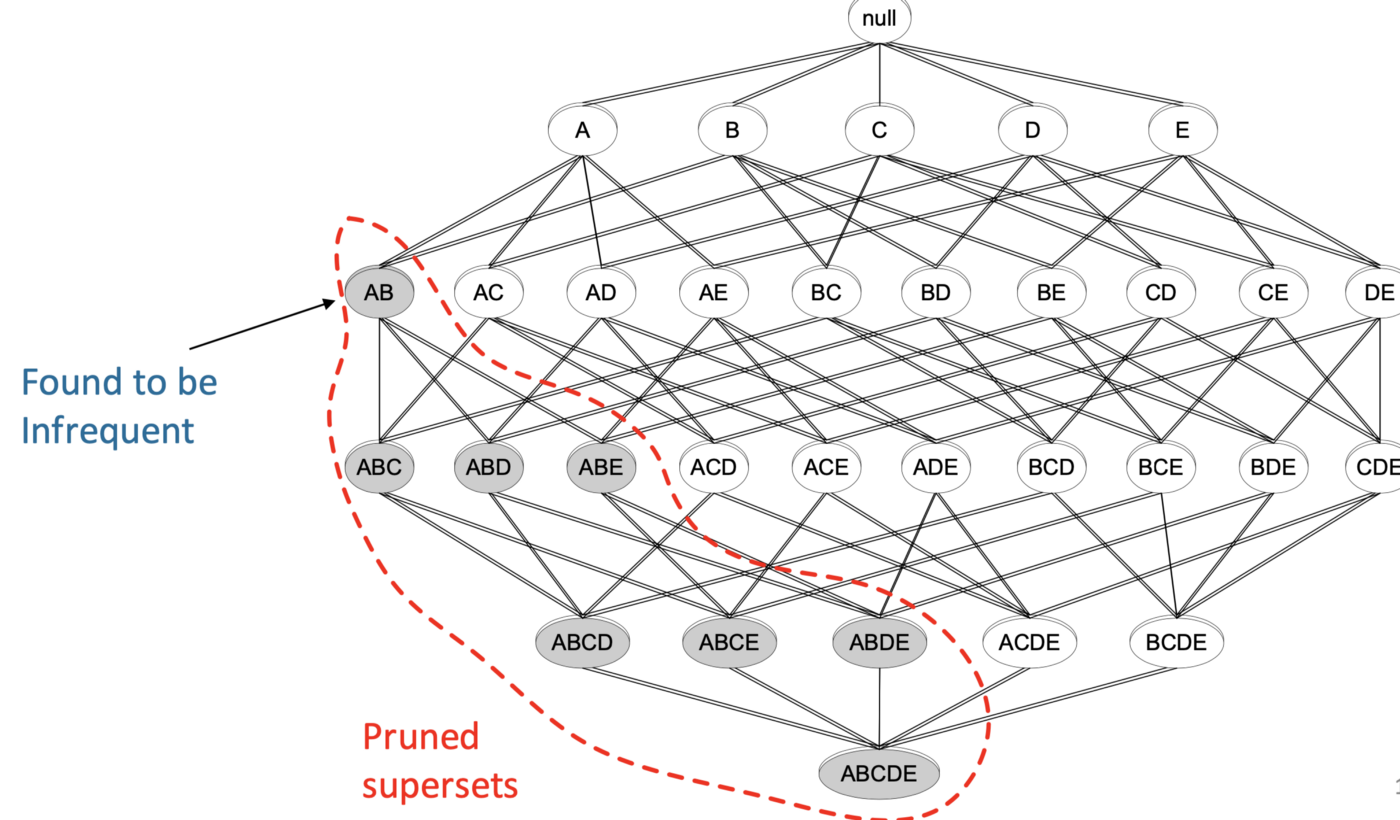
Apriori principle — If an item-set is frequent, then all of its subsets must also be frequent
Apriori property — Support of an item-set never exceeds the support of its subsets.
* Ideal way is to not use a single Minimum support threshold value as: **
- High Minimum Support — This would result in a less Frequent Item Set.
- Low Minimum Support — This would result in too many frequent Itemset and extra exponential processing.
Support count value depends on the nature of the application For ex:
- Medical domain — While building a recommendation engine about medicine based on patients' symptoms, prefer high value to get more accurate related values
- E-commerce recommendation engines — prefer low values, to get more related customers' data. It will definitely grow the sales.
There are multiple parameters to reduce the processing — confidence, lift.
Confidence(A→B) = (Transactions containing (A and B))/(Transactions containing only A)
Lift(A→B) = (Confidence (A→B))/(Support (B))
Published at DZone with permission of Ritresh Girdhar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments