When Databases Meet FPGA: Achieving 1 Million TPS With X-DB Heterogeneous Computing
Explore Alibaba Cloud's X-Engine and how to achieve 1 million TPS with X-DB heterogenous computing.
Join the DZone community and get the full member experience.
Join For FreeX-Engine is a new generation storage engine developed by Alibaba Database Department and is the basis of the distributed database X-DB. To achieve 10 times the performance of MySQL and 1/10 the storage cost, X-DB combines software with hardware to make full use of the most cutting-edge technical advantages in both software and hardware fields.
FPGA acceleration is our first attempt in the custom computing field. At present, the FPGA-accelerated X-DB has been subject to small-scale online grayscale release. FPGA will assist X-DB in the 6.18 and Double 11 shopping carnivals this year and will meet Alibaba's business departments' high database performance requirements.
Overview of Alibaba's X-Engine
Owning the world's largest online transaction website, Alibaba's OLTP (online transaction processing) database system needs to satisfy high-throughput service requirements. According to our statistics, several billion records get written into our OLTP database system on a daily basis. During the 2017 Double 11 (Singles' Day) shopping carnival, the system's peak throughput reached 10 million TPS (transactions per second). Alibaba's business database systems mainly have the following characteristics:
- High transaction throughput and low latency in write and read operations.
- Write operations make up a relatively high proportion in comparison to that of traditional databases; the read to write workload ratio usually is more than 10:1. However, the number for Alibaba's transaction system reached 3:1 on the day of the 2017 Double 11 shopping carnival.
- Data access hotspots are relatively concentrated. A newly written data record will be accessed mainly (99%) within the first seven days, and the possibility it may be accessed later is extremely low.
To meet Alibaba's stringent requirements on performance and cost, we have designed a new storage engine; it is called X-Engine. We have used many cutting edge database technologies in X-Engine; these include highly-efficient memory index structures, asynchronous write assembly-line processing mechanism, and optimistic concurrency control for in-memory databases.
To achieve the best write performance and facilitate the separation of cold and hot data for tiered storage, X-Engine has borrowed the design of LSM-Tree. X-Engine maintains multiple memtables in its memory. It appends all newly written data to these memtables, rather than directly replacing existing records. As the data storage is relatively large, it is impossible to store all data in memory.
When data in memory reaches a specified volume, we flush it to the persistent storage to form an SSTable. To reduce latency in read operations, X-Engine regularly schedules compaction tasks to compact SSTables in the persistent storage. X-Engine merges key-value pairs in multiple SSTables by keeping only the latest version of key-value pairs if multiple versions exist (all key-value pair versions currently referenced by transactions will also be kept).
Based on the characteristics of data access, X-Engine applies tiered storage to persistent data, where we store active data in relatively high data layers, and merge less active data (seldom accessed) with base-layer data and store it in the base-layer. It compresses base-layer data at a high compression rate and migrates it to storage media featuring large capacity but the relatively low price (such as SATA HDDs) to achieve the goal of storing a large quantity of data at a relatively low cost.
In this case, tiered storage creates a new problem: the system must frequently compact data, and the larger number of data writes requires more frequent compaction processes. Compaction is a compare and merge process which requires high consumption of CPU and storage I/O. In high-throughput write cases, a large number of compaction operations will occupy a large number of system resources. This can surely cause the performance of the entire system to drop tremendously thus leading to a huge impact on the application system.
The completely new X-Engine has extraordinary multi-core expansion capability to achieve very high performance. Its front-end transaction alone can almost completely consume all CPU resources, and it has a much higher resource using efficiency than InnoDB. We have shown the comparison between the two in the following figure:
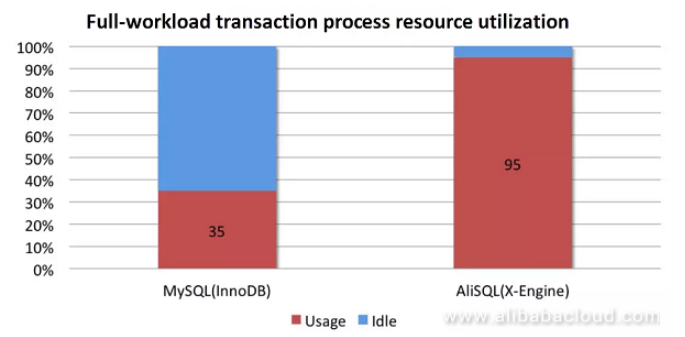
At such a performance level, the system does not have any other resources for compaction operations; otherwise, performance levels will drop.
Based on our testing results, in DbBench benchmark's write-only scenario, the system periodically suffers from performance jitter. When a compaction task occurs, the system performance drops by more than 40%, and when the compaction task ends, the system performance returns to normal. We have shown this behavior in the following figure:

However, if we do not conduct compaction promptly, the accumulation of multi-version data can seriously affect the read operations.
To solve the performance jitter caused by compaction, academic experts have put forward many structures such as VT-tree, bLSM, PE, PCP, and dCompaction. Although these algorithms can optimize the compaction performance across multiple aspects, they cannot reduce consumption of CPU resources by compaction. Based on relevant research statistics, when using SSD storage devices, the computing operations of compaction in the system consumes approximately 60% of computing resources. Therefore, no matter what optimizations we implement for compaction in the software layer, for all LSM tree-based storage engines, performance jitter caused by compaction is always an Achilles' heel.
Fortunately, special hardware opens a new door for solving performance jitter caused by compaction. In fact, it has become a trend to use special hardware in solving traditional databases' performance bottlenecks. We have already offloaded database operations such as Select and Where to FPGA, and more complex operations such as Group By are under research. However, the current FPGA acceleration solutions have a couple of drawbacks:
- The current acceleration solutions are designed for the SQL layer; FPGA is generally placed between storage and host and is used as a filter. Although, researchers have made numerous attempts to use FPGA to accelerate the OLAP system, the FPGA acceleration design for the OLAP system remains a challenge.
- While FPGA's chip size is getting smaller and smaller, FPGA's internal errors such as single event upset (SEU) pose greater and greater threats to FPGA reliability. For a single chip, the probability of internal error is 3-5 years. Therefore, the fault tolerance mechanism design becomes vitally important for systems in need of large-scale availability.
To ease the impact of compaction on X-Engine's system performance, we have used an asynchronous hardware device FPGA, rather than the CPU to complete the compaction operation. This approach is crucial for a storage engine that satisfies stringent service requirements by maintaining the overall system performance at a high-level and avoiding performance jitters. Here are the major design features:
- Highly efficient design and implementation of FPGA compaction: Using streamlined compaction operations, FPGA compaction achieves a processing performance 10 times the CPU single-thread processing performance
- Hybrid storage engine's asynchronous scheduling logic design: As FPGA can complete compaction's link requests in milliseconds, using a traditional synchronous scheduling method will block a large number of compaction threads and cause heavy thread-switching cost. Through asynchronous scheduling, we have successfully reduced the thread-switching cost and improved the system's engineering availability.
- Fault tolerance mechanism design: As limits of entered data and FPGA internal errors may cause a rollback of some compaction tasks, to ensure data integrity, all tasks that have been rolled back by FPGA will be re-executed by the equivalent CPU compaction threads. The fault tolerance mechanism design as described in this article meets Alibaba's actual business requirements and avoids FPGA's internal instability.
X-Engine Compaction
X-Engine's storage structure contains one or multiple memory buffer areas (memtable), and multilayer persistent storage L0, L1... Each layer contains multiple SSTables.
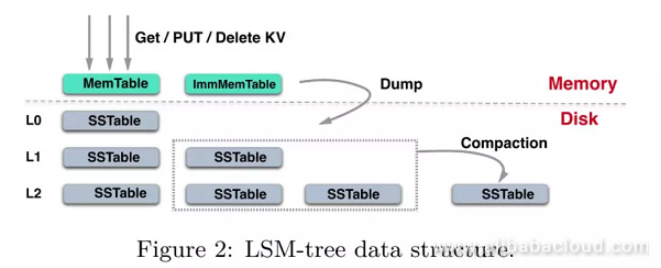
When memtable is full, it turns into an immutable memtable and then flushes to an SSTable to L0. Each SSTable contains multiple data blocks and one index block to index the data block. When it reaches the maximum number of L0 files, it triggers the merge of SSTables that have the overlapped key ranges; this process is called compaction. Likewise, when we reach the maximum number of SSTables at a layer, it merges with lower layer data. In this way, cold data constantly flows downward while hot data remains at a relatively higher layer.
We can specify a range of key-value pairs that merge during a compaction process and this range may contain multiple data blocks. Generally, a compaction process involves merging data blocks between two adjacent layers. However, we need to pay special attention to compaction tasks between L0 and L1. This is because as SSTables in L0 directly flushes from the memory, keys of SSTables in this layer may get overlapped. Therefore, a compaction task between L0 and L1 may involve merging multiple data blocks.
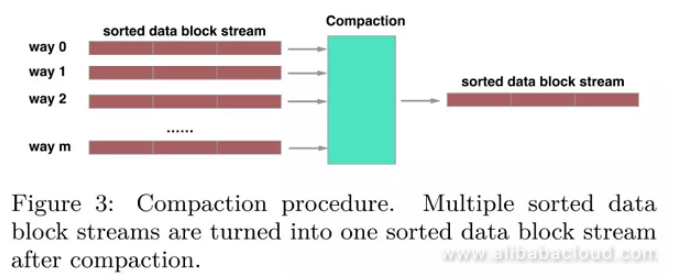
For read operations, X-Engine needs to search for the required data from all memtables. If it fails to find the data in memtables, it searches in the persistence storage, from higher to lower layers. As a result, timely compaction operations not only shorten the read path but also save the storage space. However, this method uses a lot of system computing resources and causes performance jitter. This is an urgent problem that X-Engine must solve.
FPGA Accelerated Database
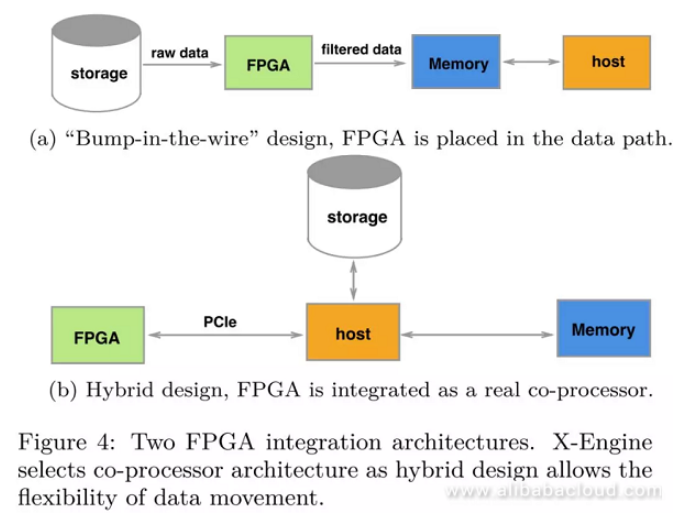
From the perspective of the existing FPGA accelerated databases' status quo, we can divide FPGA accelerated database architectures into two types; the bump-in-the-wire design and the hybrid design. In the early stage, because of the FPGA card's insufficient memory resources, the former type of architecture is relatively popular. In this architecture, we place FPGA on the storage data path and use the host as a filter. The advantage is that it requires zero data replication, while the drawback is that the acceleration operation must be a part of the streamlined process, therefore making it not flexible enough in terms of the design method.
The latter architecture design uses FPGA as a coprocessor, where we have connected FPGA to host via PCIe and use the DMA method for data transmission. As long as the offloading computation is intensive enough, data transmission costs are acceptable. The hybrid architecture design allows more flexible offloading methods. For complex operations such as compaction, data transmission between FPGA and host is necessary. Therefore, we have used the hybrid architecture design for hardware acceleration in our X-Engine.
System Design
In traditional LSM-tree-based storage engines, CPU is responsible for handling normal user requests, as well as the scheduling and execution of compaction tasks. In other words, CPU is both the producer and consumer of compaction tasks. However, in a CPU-FPGA hybrid storage engine, CPU is only responsible for producing and scheduling compaction tasks. In this method, we need to offload the execution of compaction tasks to the special hardware (FPGA).

For X-Engine, handling of normal user requests is similar to that of LSM-tree-based storage engines:
- A user submits a request to operate on a specified KV pair (Get/Insert/Update/Delete). In the case of a write operation, a new record appends to a memtable.
- When a memtable reaches its maximum size, it turns into an immutable memtable.
- The immutable memtable then turns into an SSTable and flushes to the persistent storage.
When L0 reaches the maximum number of SSTables, compaction gets triggered. We can divide offloading of a compaction task into the following steps:
- CPU splits Load SSTables (that need to be compacted from the persistent storage) into multiple compaction tasks at the granularity of data blocks following the metadata, and pre-allocates memory space for computation result of each compaction task. Consequently, it pushes each successfully created compaction task into the Task Queue for FPGA to execute.
- CPU reads the status of Compaction Units on FPGA and allocates compaction tasks from the Task Queue to available Compaction Units.
- It transmits Input data to FPGA's DDR via DMA.
- A Compaction Unit executes the compaction task and transmits the computation result via DMA back to the host; it attaches a return code to indicate the status of this compaction task (fail or success). Next, it pushes the compaction results of finished tasks to the Finished Queue.
- The CPU checks the compaction result status in the Finished Queue. If a compaction task fails, the CPU executes it again.
- It flushes the compaction results to storage.
Detailed Design
FPGA-Based Compaction
Compaction Units (CU) are the basic unit for FPGA to execute compaction tasks. An FPGA card can place multiple CUs, and each CU is composed of the following modules:
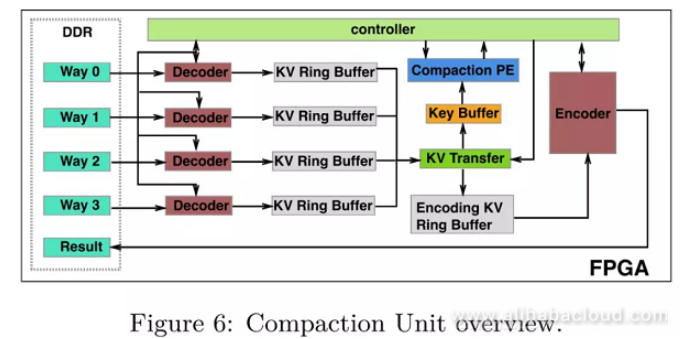
1. Decoder: In X-Engine, we store a KV in the data block after compression and encoding. The primary function of the Decoder module is to decode KV pairs. Each CU contains 4 Decoders, and a CU support a compression task of a maximum of 4 KV pairs. We need to split the compression tasks that require compression of more than 4 KV by the CPU. Based on our assessment, most compression tasks involve less than 4 KV pairs. We have placed 4 Decoders based on our considerations of performance and hardware resources. Comparing the configuration with 2 Decoders, we've increased 100% hardware consumption but obtained 300% performance improvement.
- KV Ring Buffer: KV pairs decoded by the Decoder module get temporarily stored in KV Ring Buffer. Each KV Ring Buffer maintains a read indicator (maintained by the Controller module) and a write indicator (maintained by the Decoder module). KV Ring Buffer maintains three signals to indicate the current status: FLAG_EMPTY, FLAG_HALF_FULL, and FLAG_FULL. If FLAG_HALF_FULL is at a low level, the Decoder module will continue decoding KV pairs. Conversely, the Decoder module will stop decoding KV pairs until downstream consumers in the pipeline have consumed the decoded KV pairs.
- KV Transfer: This module is responsible for transmitting keys to Key Buffer. Because merging KV pairs only involve comparison of key values, the values do not need to be transmitted. We can track the currently compared KV pairs by using the read indicator.
- Key Buffer: This module stores keys of each KV pair that need to be compared. When all keys that need to be compared have been transmitted to the Key Buffer, the Controller notifies the Compaction PE to compare them.
- Compaction PE: The Compaction Processing Engine (compaction PE) is responsible for comparing key values in Key Buffer. Comparison results are sent to the Controller, and then the Controller sends a notice to KV Transfer to transmit the corresponding KV pair to the Encoding KV Ring Buffer for the Encoder module to encode them.
- Encoder: The Encoder module is responsible for encoding KV pairs from the Encoding KV Ring Buffer into a data block. If the data block reaches its maximum size, then the current data block gets flushed to DDR.
- Controller: The Controller acts as a coordinator in CU. Although the Controller is not a part of the compaction pipeline, it plays a key role in each step of the compaction pipeline design.
A compaction process contains three key steps: decoding, merging, and encoding. The most significant challenge for designing a proper compaction pipeline is that the execution time for each step varies significantly. For example, because of parallel processing, the throughput of the decoder module is much higher than the encoder module. Therefore, we must suspend some fast modules to wait for downstream modules still in the pipeline. To match the throughput differences in each of the pipeline's modules, we have designed a Controller module to coordinate different steps in the pipeline. An additional benefit of this design is that it decouples each module in the pipeline and enables more flexible development and maintenance during engineering implementation.

When integrating FPGA compaction into X-Engine we hope to have independent CU throughput performance; the baseline of the experiment is the CPU.
Single-core compaction thread (Intel(R) Xeon(R) E5-2682 v4 CPU with 2.5 GHz)
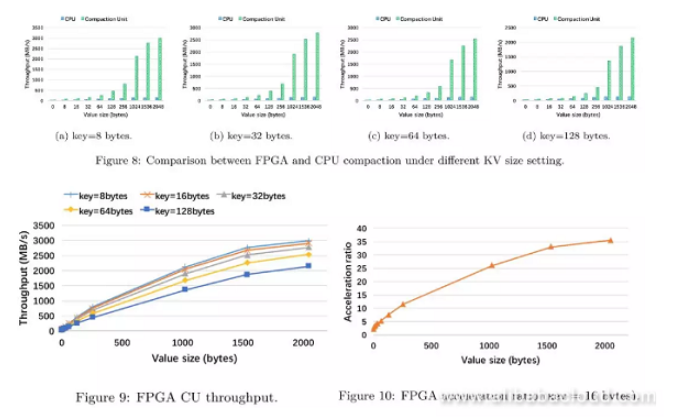
We can draw the following three conclusions from the experiment:
- n all KV lengths, FPGA compaction has a higher throughput than that of a single-thread CPU; this proves the feasibility of compaction offload;
- With the increase of KV lengths, FPGA compaction throughput reduces. This is because the lengths of bytes that need to be compared have increased, resulting in the increase of cost for comparison.
- The acceleration rate (FPGA throughput / CPU throughput) increases with the value length. This is because when the KV length is short, it requires frequent communication and status checking among different modules; this means a relatively high cost in comparison with normal pipeline operations.
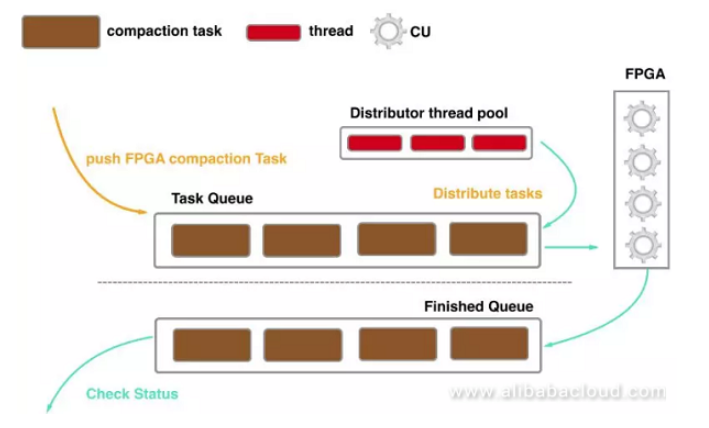
Asynchronous Scheduling Logic Design
Because a link request in FPGA is completed in milliseconds, using the traditional synchronous scheduling method will cause high thread switching costs. Based on FPGA's characteristics, we have redesigned an asynchronous scheduling compaction method, where:
- The CPU is responsible for building compaction tasks and pushing them into the Task Queue.
- A thread pool is maintained to distribute compaction tasks to specified CUs.
- When a compaction task is finished, it will be pushed to the Finished Queue.
- The CPU will then check the task execution status, and schedule CPU compaction threads to re-execute the failed compaction tasks.
Asynchronous scheduling significantly reduces the thread-switching cost of CPU.
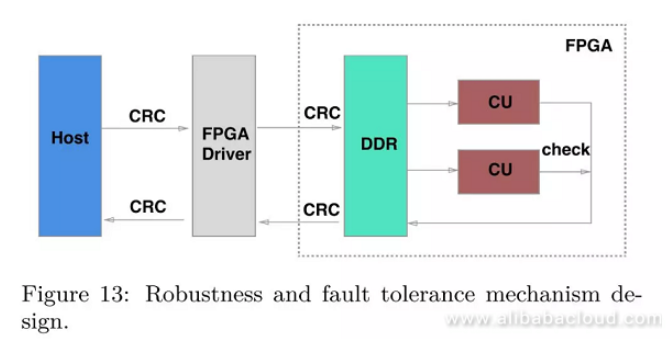
Fault Tolerance Mechanism Design
For FPGA compaction, the following three reasons can lead to the failure of compaction task:
- Data gets damaged during the transmission process: Calculate the CRC values of data before and after transmission, and compare the values. If these two CRC values are inconsistent, it means that the data is damaged.
- FPGA internal errors (bit upset): To solve this problem, we have attached an additional CU to each CU. We can compare the computation results of both CUs and any inconsistency in the results will indicate that a bit upset error has occurred.
- Input data of a compaction task is invalid: To facilitate FPGA compaction design, we have set a restriction on the length of KVs. The compaction tasks for KVs that exceed the maximum allowable length are identified as invalid tasks.
To ensure the data is correct, the CPU will conduct computation again on all failed tasks. As we mentioned earlier in the fault tolerance mechanism, we have addressed a small part of compaction tasks that exceed the limits and have avoided the risk of FPGA internal errors.
Experiment Results
Lab environment
- CPU: 64-core Intel (E5-2682 v4, 2.50 GHz) processor
- Memory: 128 GB
- FPGA card: Xilinix VU9P
- memtable: 40 GB
- block cache 40 GB
We compared the performance of two storage engines:
- X-Engine-CPU: compaction operation executed by CPU
- X-Engine-FPGA: compaction offloaded to FPGA for execution
DbBench
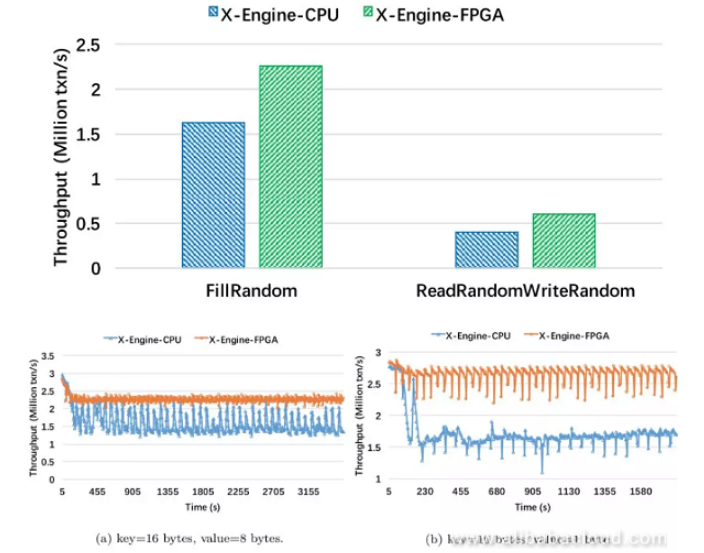
Result analysis:
- n a write-only scenario, X-Engine-FPGA sees a 40% throughput increase. From the performance curve we can tell that when compaction begins, the performance of X-Engine-CPU drops by 1/3.
- FPGA compaction has a higher throughput and is faster, so the read path is shortened faster. Therefore, in the read/write hybrid scenario, X-Engine-FPGA throughput increases by 50%.
- The throughput in the read/write hybrid scenario is smaller than that of the write-only scenario. Read operations require access to data stored in persistent layers which brings in I/O cost and affects the overall throughput performance.
- These two performance curves represent two different compaction statuses. In the left figure, the system performance jitters periodically meaning that the compaction operation is competing with normal transaction handling threads for CPU resources; while in the right figure, X-Engine-CPU's performance maintains at a low-level meaning that the compaction speed is smaller than the write speed, causing accumulation of SSTables. Compaction tasks are subject to constant scheduling at the backend.
- CPU schedules the Compaction tasks. That's why X-Engine-FPGA's performance also jitters and the curve is not smooth.
YCSB
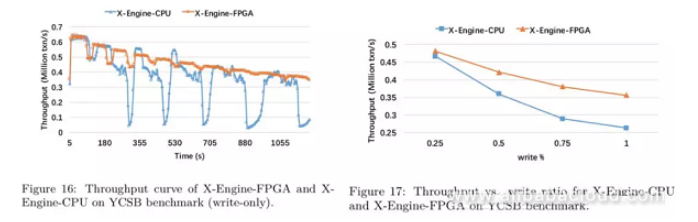
Result analysis:
- On YCSB benchmark, due to the influence of compaction, X-Engine-CPU's performance decreases by approximately 80%. However, for X-Engine-FPGA, its performance only sees a fluctuation of 20% due to the influence of the compaction scheduling logic.
- The check-unique logic introduces read operations. With the increase in pressure testing time, the read path becomes longer, and the performance of both storage engines decreases with time.
- In the write-only scenario, X-Engine-FPGA's throughput increases by 40%. However, with the increase in the read/write ratio, the acceleration effect of FPGA Compaction decreases gradually. When the read/write ratio becomes higher, the write pressure becomes smaller, and the SSTable accumulation becomes slower thus reducing the number of threads that handle compaction tasks. Therefore, X-Engine-FPGA sees a more obvious performance increase in write-intensive workloads.
- With the increase in the read/write ratio, the throughput increases. When write throughput is smaller than that of the KV interface, the cache miss ratio is relatively low, thus avoiding frequent I/O operations. With the increase in the proportion of write operations, the number of threads that handle compaction tasks also increases, thus reducing the system's throughput capability.
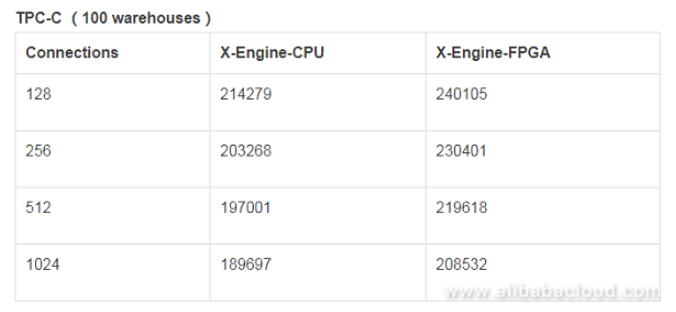
Result analysis:
- With FPGA acceleration, X-Engine-FPGA's performance improves by 10%–15% when the number of connections is increased from 128 to 1024. When the number of connections increases, the throughput of both systems gradually decreases because of the lock competition of hotspot rows increases.
- TPC-C's read/write ratio is 1.8 : 1. In the experiment, under the TPC-C benchmark, more than 80% of CPU resources were consumed on SQL resolution and lock competition of hotspot rows. The actual write pressure was not very heavy. Based on our observation in the experiment, the number of threads that execute compaction tasks in the X-Engine-CPU is no more than three (a total of 64 cores). Therefore, FPGA's acceleration effect is not as obvious as the previous instances.
SysBench
We have included testing for InnoDB in this experiment (buffer size = 80 GB)
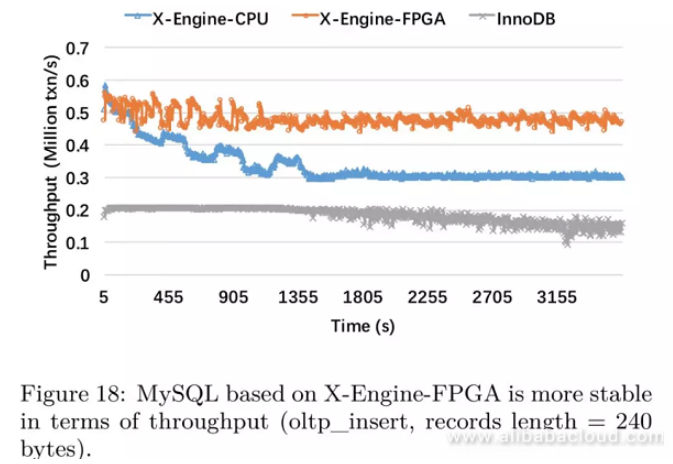
Result analysis:
- X-Engine-FPGA improves more than 40% of throughput performance. Because SQL resolution consumes a large number of CPU resources, the throughput of DBMS is smaller than that of the KV interface.
- X-Engine-CPU reaches a balance at a low level. Because the compaction speed is slower than the writing speed, SST files are accumulated, and compaction is constantly scheduled.
- X-Engine-CPU's performance is twice that of InnoDB, which shows the advantage of LSM tree-based storage engines in a write-intensive scenario;
- In comparison with the TPC-C benchmark, Sysbench is more similar to Alibaba's real transaction scenario. For a transaction system, most queries are data insertion queries and simple point queries and seldom involve range queries. A decrease in hotspot row conflicts causes the number of resources consumed in the SQL layer to decrease. During the experiment, we have observed that for X-Engine-CPU, when more than 15 threads are used to execute compaction tasks, the performance improvement brought by FPGA acceleration is very obvious.
Conclusion
In this article, the X-Engine storage engine accelerated by FPGA brings 50% performance improvement for the KV interface, and 40% performance improvement for the SQL interface. With the decrease in the read/write ratio, FPGA's acceleration effect becomes more obvious, thus meaning that FPGA compaction acceleration is suitable for write-intensive workloads. This is consistent with the intention of the LSM-tree design. Also, we have avoided FPGA's internal defects by designing a fault tolerance mechanism, and we've finally created a high-availability CPU-FPGA hybrid storage engine that meets Alibaba's real service requirements.
It is the first real project that uses a heterogeneous computing device introduced by X-DB to accelerate core database functions. Based on our experiences, FPGA can completely meet the computing demands raised by X-Engine's compaction tasks. At the same time, we have been researching to schedule more suitable computing tasks to FPGA for execution, such as compression, BloomFilter generation, and SQL JOIN operators. At present, the R&D for the compression function is completed, and it will be built into a set of IP together with Compaction to perform data compaction and compression operations simultaneously.
X-DB FPGA-Compaction hardware acceleration is an R&D project completed by three parties; these parties are respectively the Alibaba Database Department database kernel team, the Alibaba Server R&D Department custom computing team, and Zhejiang University. Xilinx's technical team has also made great contributions to the success of this project. We hereby extend our gratitude to them. We will post X-DB online for public beta this year. You will then be able to experience the significant performance improvement with FPGA acceleration to X-DB.
Published at DZone with permission of Leona Zhang. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments