Why Text2SQL Alone Isn’t Enough: Embracing TAG
Table-augmented generation (TAG) and LOTUS bridge AI and databases, enabling complex queries using LLMs. They address the limits of Text2SQL and RAG models.
Join the DZone community and get the full member experience.
Join For FreeImagine you’re trying to understand why your company’s sales dropped last quarter. You query your database with a simple natural language question: “Why did sales drop last quarter?” The ideal scenario would be that the AI system instantly provides you with a context-rich, insightful answer — something that ties together all relevant data points, trends, and market insights. However, the reality is far from ideal.
Current AI methods for querying databases, such as Text2SQL and retrieval-augmented generation (RAG), fall significantly short. These models are limited by their design, either only interpreting natural language as SQL queries or relying on simple lookups that fail to capture the complexity of real-world questions.
Why Does This Matter?
Using natural language to query SQL databases has been the new norm ever since LLMs started capturing the limelight! Businesses today are drowning in data but starving for insights. The inability of existing methods to effectively leverage both AI’s semantic reasoning and databases’ computational power is a major bottleneck in making data truly actionable. It’s clear that we need a new approach — one that can understand and answer the wide range of questions real users want to ask.
But using natural language in such a scenario comes with challenges:
- Text2SQL. This approach is designed to convert natural language questions into SQL queries. While it works well for straightforward questions like “What were the total sales last quarter?” it fails when questions require more complex reasoning or knowledge that is not explicitly stored in the database. For example, a question like “Which customer reviews of product X are positive?” requires sentiment analysis over text data — a capability outside the scope of SQL queries.
- Retrieval-augmented generation (RAG). RAG models attempt to use AI to find relevant data records from a database, but they are limited to point lookups and cannot handle complex computations. They often fail to provide accurate answers when data volume is high, or when the question requires reasoning over multiple data points.
Consider a business scenario where you need to understand trends from customer reviews, sales data, and market sentiment all at once. Text2SQL cannot handle free-text data. And do not forget hallucinations! RAG addresses this to some extent, but it is inefficient with large datasets and can provide inaccurate or incomplete answers, especially when it doesn’t have the knowledge of the target database or it cannot exactly translate the user intent into a functioning SQL!
And so, these approaches leave a large portion of potential user queries unanswered, leading to a critical gap in real-world applicability.
So, what is table-augmented generation (TAG), and how does it address some of these challenges?
Table-Augmented Generation (TAG)
TAG is a new augmentation approach that researchers from Stanford and Berkeley are proposing to address the limitations in Text2SQL approach. Here’s a link to their paper: https://arxiv.org/abs/2408.14717.
Here’s how it works:
1. Query Synthesis
First, the user’s natural language request is translated into an executable database query. Unlike Text2SQL, TAG can generate more than just SQL queries; it can synthesize complex queries that combine multiple data sources and types. For example, notice this image that the researchers provided in their paper.
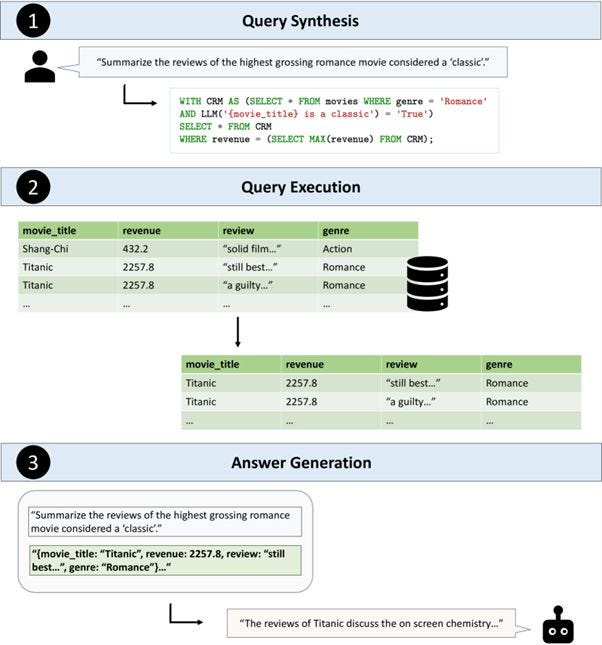
Notice how the user query “Summarize the reviews of the highest-grossing romance movie considered a “classic” has been translated into:
WITH CRM AS (SELECT * FROM movies WHERE genre = 'Romance'
AND LLM('{movie_title} is a classic') = 'True')
SELECT * FROM CRM
WHERE revenue = (SELECT MAX(revenue) FROM CRM);TAG introduced a new LLM call using the line LLM(‘{movie_title} is a classic’) = ‘True’). This is the “Augmentation” step. The SQL query or, more specifically, the table retrieval step has been augmented with this step because the table does not provide the context about when a movie is considered “classic.”
2. Query Execution
Once the query is synthesized, it is executed against the database. TAG leverages the computational power of databases to efficiently handle large-scale data retrieval and exact computations, which language models struggle to perform.
3. Answer Generation
In this final step, the AI model uses the retrieved data to generate a context-rich answer. The model combines world knowledge, semantic reasoning, and domain-specific understanding based on the augmentation in Step 1 to produce a comprehensive response to the user’s question.
Another key component that enables TAG to function effectively is the LOTUS framework.
LOTUS: The Framework Powering TAG’s Capabilities
As I mentioned above, in order for TAG to work, we need a robust framework that can seamlessly integrate AI capabilities with traditional database systems. This is where LOTUS (LLMs Over Tables of Unstructured and Structured Data) comes into play. LOTUS is designed to bridge the gap between the reasoning power of large language models (LLMs) and the computational strength of databases, enabling more complex and meaningful data queries.
What Is LOTUS?
LOTUS is a novel framework that empowers TAG by enabling semantic queries over tables containing both structured and unstructured data. It integrates LLMs directly into the database query processing pipeline, combining the best of both worlds — high-performance data management from databases and advanced reasoning and natural language understanding from AI models.
Key Features of LOTUS
1. Semantic Operators for AI-Enhanced Queries
LOTUS introduces a range of semantic operators — AI-based functions that can perform tasks such as filtering, ranking, and aggregation using natural language processing. For instance, instead of a traditional SQL filter, a LOTUS query might use a language model to determine which rows contain positive sentiment or relevant entities, bringing a whole new level of sophistication to querying.
2. Optimized Query Execution
3. Flexibility and Customization
4. Enabling the TAG Framework
Conclusion
There are some excellent examples in the GitHub link on how to use LOTUS for performing semantic joins. I’m planning to try it out soon — stay tuned for more in a future post!
Thanks for reading. :)
Opinions expressed by DZone contributors are their own.
Comments