Distributed Locking and Race Condition Prevention in E-Commerce
Learn how implementing distributed locking mechanisms with best practices can significantly enhance the robustness and performance of e-commerce platforms.
Join the DZone community and get the full member experience.
Join For FreeIn distributed systems, race conditions occur when multiple processes or threads attempt to modify shared data concurrently, leading to unpredictable outcomes. E-commerce platforms, which handle numerous simultaneous transactions, are particularly susceptible to race conditions. Implementing distributed locking mechanisms is essential to ensure data consistency and integrity. This article explores distributed locking and demonstrates how to prevent race conditions in an e-commerce setting.
Understanding Distributed Locking
Distributed locking is a synchronization mechanism used to control access to shared resources in a distributed environment. It ensures that only one process can modify a resource at a time, thereby preventing race conditions.
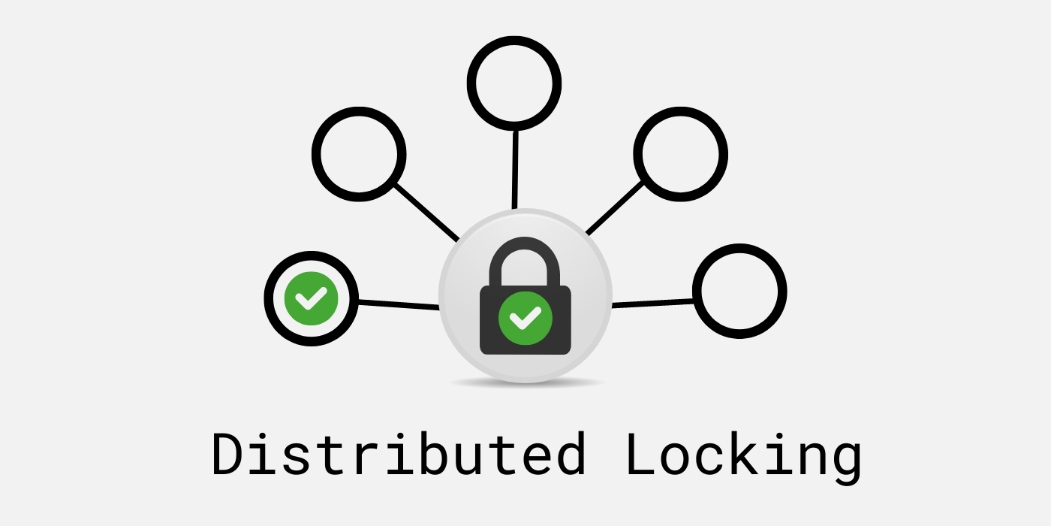
Distributed Locking
- Nodes: Each circle represents a node in a distributed system (Node 1, Node 2, Node 3, etc.).
- Central lock: The lock in the center represents the distributed lock service, ensuring that only one node can access the shared resource at a time.
- Green checkmarks: Indicate that the node has successfully acquired the lock and can safely access the shared resource
Accessing Data Without Locking
- Nodes: Multiple nodes trying to access the same data
- Data store: A central data store
- Concurrency issues: Arrows from nodes to the data store, with potential conflicts highlighted
Concurrent Access Issues Diagram
- Nodes: Circles labeled as "Node 1", "Node 2", "Node 3", etc.
- Shared data store: The central data store is accessed by multiple nodes.
- Conflict arrows: Arrows from each node to the data store, indicating concurrent access and potential conflicts
Why Traditional Locking Does Not Work in Distributed Systems
Traditional Locking Mechanisms
Traditional locking mechanisms (e.g., mutexes, semaphores) are designed for single-node environments, where threads within the same process need to coordinate access to shared resources.
Challenges in Distributed Systems
1. Network Latency
Nodes in a distributed system communicate over a network, introducing latency. Traditional locks assume low latency, which is not feasible across networked nodes.
2. Failure Detection
Accurately detecting node failures is difficult in distributed systems. A node holding a traditional lock might crash, leaving the lock in an indeterminate state.
3. Scalability
Traditional locks are not designed to scale across multiple nodes. Distributed systems often require coordination among many nodes, which traditional locks cannot handle efficiently.
4. Consistency
Maintaining consistency across multiple nodes is challenging. Traditional locks do not account for scenarios where nodes might be partitioned or fail independently.
Example
Issue With Traditional Locking
Imagine Node A acquires a lock and then crashes. The lock remains in a locked state, preventing other nodes from accessing the shared resource.
Distributed Locking Solution
Distributed locks use consensus algorithms (like Paxos or Raft) to ensure that locks can be reassigned or released even if a node crashes, maintaining the system’s reliability and availability.
Distributed locking mechanisms are essential for maintaining data consistency and system reliability in distributed environments. They address the limitations of traditional locking methods by handling network latency, node failures, scalability, and consistency across multiple nodes. The diagrams provided visually illustrate the concept of distributed locking and the challenges of concurrent access without proper locking mechanisms.
Key Properties of Distributed Locks
- Mutual exclusion: Only one process can hold the lock at any given time.
- Deadlock-free: The system must avoid situations where processes are stuck waiting for locks indefinitely.
- Fault tolerance: The locking mechanism should handle failures gracefully, ensuring that locks are released if a process crashes.
In the modern e-commerce landscape, distributed systems are the backbone of operations, enabling high availability, scalability, and reliability. However, distributed systems introduce complexities, one of which is the race condition — a situation where the system's behavior depends on the sequence or timing of uncontrollable events. Preventing race conditions is crucial for maintaining data consistency, especially in e-commerce, where inventory management, order processing, and user transactions need to be reliable and accurate.
Understanding Race Conditions
A race condition occurs when two or more processes access shared data simultaneously and the final outcome depends on the sequence of access. In an e-commerce context, race conditions can lead to problems like overselling, incorrect inventory levels, and inconsistent order states. For instance, if two users try to purchase the last item in stock simultaneously, without proper synchronization, both transactions might proceed, resulting in overselling.
Example Scenario
Imagine an e-commerce platform where a customer attempts to purchase the last item in stock. Without proper locking, the following sequence of events might occur:
- Customer A checks the inventory for the item.
- The system confirms that the item is in stock.
- Customer B also checks the inventory.
- The system again confirms that the item is in stock.
- Both customers proceed to purchase the item almost simultaneously.
- The inventory is updated incorrectly, possibly resulting in negative stock or an oversell.
Distributed Locking
Distributed locking is a mechanism to control access to a shared resource in a distributed system. It ensures that only one process can access the resource at a time, thus preventing race conditions. There are several approaches to implementing distributed locks, with common techniques including:
- Database locks
- Cache-based locks (e.g., using Redis)
- Coordination services (e.g., using ZooKeeper)
- Lease-based locks
1. Database Locks
Database locks can be implemented using transactions and row-level locking mechanisms provided by relational databases. For example, using SQL, you can create a locking mechanism to handle inventory updates:
BEGIN;
-- Lock the row containing the inventory information
SELECT * FROM inventory WHERE item_id = 123 FOR UPDATE;
-- Check inventory level
SELECT stock FROM inventory WHERE item_id = 123;
-- Update inventory if the stock is sufficient
UPDATE inventory SET stock = stock - 1 WHERE item_id = 123 AND stock > 0;
COMMIT;In this scenario, the FOR UPDATE clause locks the row until the transaction is completed, ensuring that other transactions cannot modify the same row simultaneously.
2. Cache-Based Locks (e.g., Redis)
Redis, an in-memory data store, is commonly used for distributed locking due to its simplicity and performance. Redis provides the SET command with the NX and PX options to implement locks.
import redis
import time
r = redis.Redis(host='localhost', port=6379, db=0)
lock_key = "item:123:lock"
lock_value = str(time.time())
# Acquire lock
if r.set(lock_key, lock_value, nx=True, px=10000):
try:
# Critical section: check and update inventory
stock = r.get("item:123:stock")
if int(stock) > 0:
r.decr("item:123:stock")
print("Stock updated successfully")
else:
print("Out of stock")
finally:
# Release lock
if r.get(lock_key) == lock_value:
r.delete(lock_key)
else:
print("Could not acquire lock, try again later")In this example, the SET command with NX ensures that the lock is set only if it does not already exist, and PX sets an expiration time to avoid deadlocks.
3. Coordination Services (e.g., ZooKeeper)
Apache ZooKeeper is a distributed coordination service that can be used to implement distributed locks. ZooKeeper's zNodes (ZooKeeper nodes) can act as locks:
from kazoo.client import KazooClient
from kazoo.exceptions import LockTimeout
zk = KazooClient(hosts='127.0.0.1:2181')
zk.start()
lock = zk.Lock("/lockpath/item_123")
try:
lock.acquire(timeout=10)
# Critical section: check and update inventory
stock = zk.get("/inventory/item_123/stock")[0]
if int(stock) > 0:
zk.set("/inventory/item_123/stock", str(int(stock) - 1).encode('utf-8'))
print("Stock updated successfully")
else:
print("Out of stock")
finally:
lock.release()
zk.stop()In this case, the Lock class provides methods to acquire and release locks, ensuring that only one process can modify the inventory at a time.
4. Lease-Based Locks
Lease-based locks involve acquiring a lock with a time-bound lease, ensuring that the lock is automatically released after the lease expires. This approach can be implemented using services like AWS DynamoDB with its conditional writes and TTL (time-to-live) attributes:
import boto3
from time import time
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('Inventory')
lock_item = {
'item_id': '123',
'lock_expiration': int(time()) + 10
}
# Acquire lock
response = table.put_item(
Item=lock_item,
ConditionExpression='attribute_not_exists(item_id) OR lock_expiration < :now',
ExpressionAttributeValues={':now': int(time())}
)
if response['ResponseMetadata']['HTTPStatusCode'] == 200:
try:
# Critical section: check and update inventory
response = table.get_item(Key={'item_id': '123'})
stock = response['Item']['stock']
if stock > 0:
table.update_item(
Key={'item_id': '123'},
UpdateExpression='SET stock = stock - :val',
ConditionExpression='stock > :zero',
ExpressionAttributeValues={':val': 1, ':zero': 0}
)
print("Stock updated successfully")
else:
print("Out of stock")
finally:
# Release lock
table.delete_item(Key={'item_id': '123'})
else:
print("Could not acquire lock, try again later")ConditionExpression='stock > :zero',
ExpressionAttributeValues={':val': 1, ':zero': 0}
)
print("Stock updated successfully")
else:
print("Out of stock")
finally:
# Release lock
table.delete_item(Key={'item_id': '123'})
else:
print("Could not acquire lock, try again later")This approach ensures that the lock will be automatically released if the process fails to release it manually.
Applications in E-commerce
Inventory Management
In e-commerce, maintaining accurate inventory levels is critical. Using distributed locks, we can ensure that inventory updates are atomic and consistent. For example, when multiple users attempt to purchase the same item, a lock can prevent race conditions by ensuring that only one transaction updates the inventory at a time.
Order Processing
Order processing involves multiple steps, such as payment processing, inventory deduction, and order confirmation. Distributed locks ensure that these steps are executed sequentially and consistently, preventing issues like double charging or incorrect order statuses.
User Transactions
User transactions, such as adding items to a cart or applying discounts, can benefit from distributed locks to maintain data integrity. Locks can prevent simultaneous updates that might lead to incorrect pricing or cart contents.
Best Practices for Implementing Distributed Locks
- Avoid long-held locks: Minimize the duration for which a lock is held to reduce contention and improve system performance.
- Use timeouts and leases: Implement timeouts and leases to ensure that locks are released even if the process holding the lock fails.
- Monitor and handle failures: Monitor the lock status and handle failures gracefully to avoid deadlocks and ensure system resilience.
- Test thoroughly: Thoroughly test the locking mechanism under various conditions to ensure its reliability and performance.
Conclusion
Distributed locking is an essential technique for preventing race conditions in e-commerce systems. By using database locks, cache-based locks, coordination services, and lease-based locks, we can ensure data consistency and reliability in scenarios like inventory management, order processing, and user transactions. Implementing these locking mechanisms with best practices can significantly enhance the robustness and performance of e-commerce platforms, providing a seamless experience for users and maintaining trust in the system.
Opinions expressed by DZone contributors are their own.
Comments