Infrastructure as Code: How Automation Evolved to Power AI Workloads
Learn about how Infrastructure as Code progressed in 2025 and how it helped automation, particularly for provisioning AI infrastructure.
Join the DZone community and get the full member experience.
Join For FreeIf you read my articles published on DZone this year, you would have sensed that I love automation and that Infrastructure as Code (IaC) is my buddy for automating infrastructure provisioning. Recently, I started exploring and learning about the major shifts happening in the IaC landscape.
As part of my weekend readings in the last couple of months, I came across several exciting announcements from HashiConf 2025, Pulumi's new AI capabilities, and a revolutionary platform called Formae. In this article, let's learn about how IaC progressed in 2025 and how it helped automation, particularly for provisioning AI infrastructure.
Infrastructure-as-Code has transformed how we manage cloud resources, yet 2025 brought innovations that fundamentally changed the game. From AI-powered agents that write and deploy infrastructure code to stateless platforms that eliminate drift detection complexity, this year marked a turning point in infrastructure automation.
The State of IaC: Where We Stand Today
Before diving into specific tools and announcements, let's understand the current landscape. According to the State of IaC 2025 report, cloud complexity has grown for 65% of organizations. Only 6% achieved full cloud codification, meaning most infrastructure is still managed manually. Less than 33% continuously monitor drift, taking a reactive approach to infrastructure changes.
The report makes it clear that manual provisioning is legacy. Declarative configuration files are table stakes. The automation-first pipeline emerged as the gold standard, where infrastructure changes are treated the same way as code deployments: version-controlled, tested, reviewed, and automated.
HashiConf 2025: Major Announcements That Matter
September 2025 marked HashiConf's 10th anniversary in San Francisco. HashiCorp, now part of IBM, had several announcements that caught my attention.
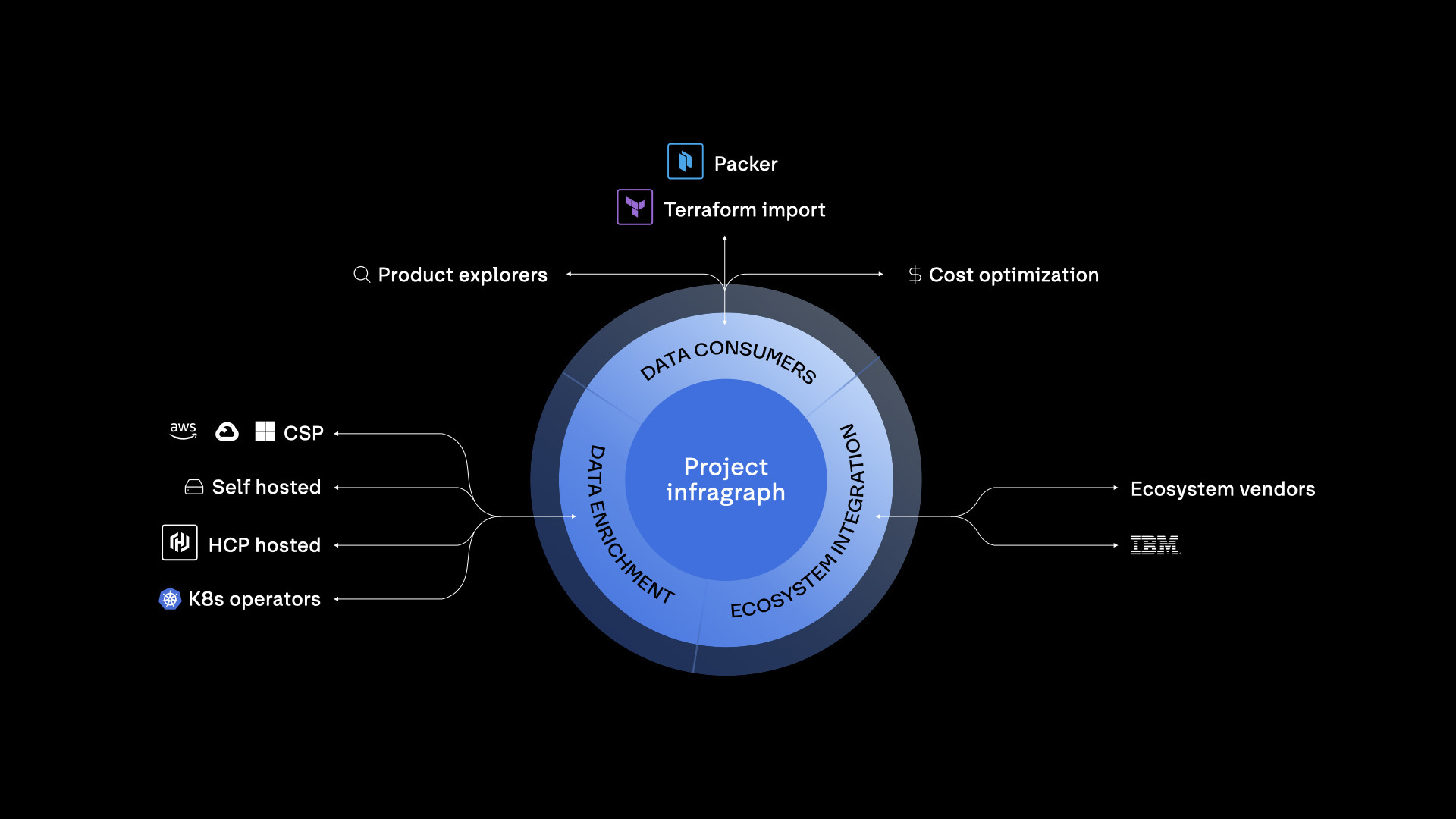
Project Infragraph: Real-Time Infrastructure Intelligence
Project Infragraph represents a fundamental shift in infrastructure observability. Instead of piecing together data from multiple monitoring tools, teams get a unified view that understands relationships between resources.
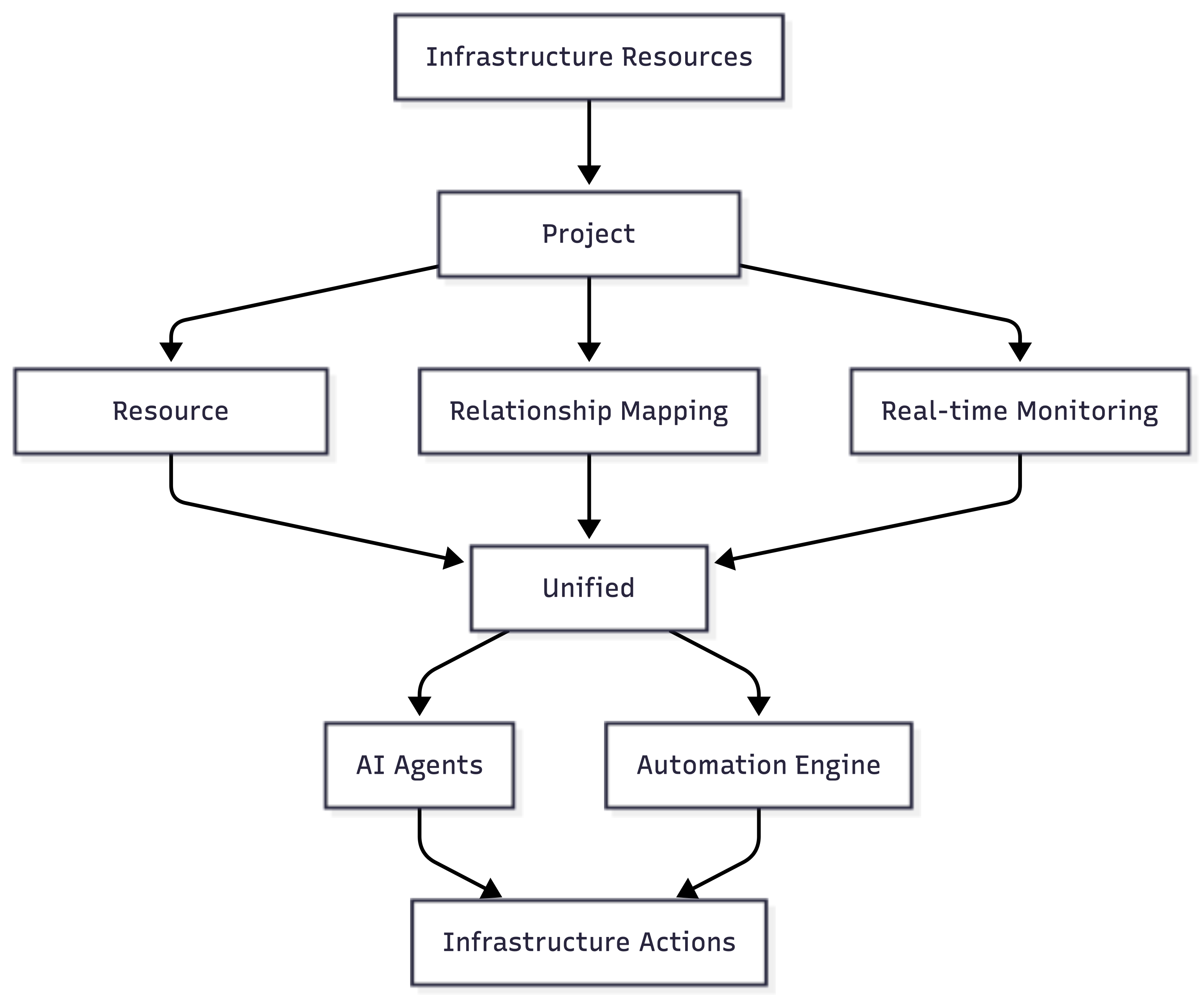
Project Infragraph enables infrastructure that can observe its own state, reason about optimal configurations, and act autonomously. The private beta launches in December 2025.
Terraform Stacks: General Availability
After months in public beta, Terraform Stacks reached general availability with backward-compatible APIs. The concept addresses a pain point I've experienced countless times: coordinating deployments across different teams, each managing their own state files.
Stacks use a component-based architecture. Here's a simple example showing how you define reusable components:
# stack.tfcomponent.hcl
component "vpc" {
source = "./modules/vpc"
inputs = {
region = var.region
environment = var.environment
}
}
component "eks_cluster" {
source = "./modules/eks"
inputs = {
vpc_id = component.vpc.vpc_id
region = var.region
}
depends_on = [component.vpc]
}What Changed in the GA Release?
All configuration files now use the .tfcomponent.hcl extension instead of .tfstack.hcl, providing a standardized naming convention. Deployment groups support new orchestration rules for better control over deployment order. Destroy operations work through code instead of UI-only, giving teams version-controlled teardown workflows. Most importantly, Terraform manages dependency resolution automatically, eliminating manual orchestration.
What used to require careful orchestration and multiple deployment windows now happens with one action. Terraform handles orchestration, dependency resolution, and change propagation automatically. This makes managing complex multi-component infrastructures significantly simpler.
MCP Servers: Bridging AI and Infrastructure
HashiConf introduced Model Context Protocol servers for Terraform, Vault, and Vault Radar. These MCP servers act as bridges between AI agents and existing infrastructure tools.
Here's a simple example of how you might use MCP to interact with Terraform through natural language:
# Example: Using MCP to trigger Terraform workspace runs
from mcp_client import MCPClient
client = MCPClient("terraform")
# Natural language request
response = client.execute(
"Trigger a workspace run for the production environment and notify the team on Slack when complete"
)
# MCP translates this to Terraform API calls
# No need to write complex API integration code
print(f"Workspace run initiated: {response.run_id}")You can now tell your AI assistant to trigger workspace runs, query secrets, or discover unmanaged resources without switching contexts or writing complex scripts. This dramatically reduces the friction in infrastructure operations.
Additional Features Worth Noting
HashiConf also announced several other features that reached general availability. Terraform search helps teams discover and import resources in bulk more efficiently. Azure Copilot with Terraform integration simplifies adoption without requiring deep Terraform knowledge. Hold Your Own Key gives organizations ownership of encryption keys used to access sensitive data in HCP Terraform. HCP Waypoint provides application template catalogs, shielding developers from code-level infrastructure details.
Pulumi Neo: AI-Powered Infrastructure Agent
While Terraform continued its market dominance, Pulumi made serious waves with Neo, their AI infrastructure agent. After a long journey with Terraform, when HCL2 came out, I started exploring alternatives where I could use the programming language of my choice. That's when I found Pulumi.
Why Pulumi Matters
Pulumi is a modern Infrastructure as Code platform that enables developers to create, deploy, and manage cloud resources using familiar programming languages instead of domain-specific languages. Instead of learning HCL, you can use TypeScript, Python, Go, C#, Java, or even YAML. This means full IDE support with code completion, error checking, and refactoring capabilities that come naturally with general-purpose programming languages.
Here's a comparison of the same infrastructure in Terraform vs Pulumi. First, the Terraform approach:
Terraform:
resource "aws_s3_bucket" "data_bucket" {
bucket = "my-data-bucket"
tags = {
Environment = "Production"
}
}Pulumi:
import pulumi_aws as aws
data_bucket = aws.s3.Bucket(
"data-bucket",
bucket="my-data-bucket",
tags={"Environment": "Production"}
)
pulumi.export("bucket_name", data_bucket.id)Neo: The AI Infrastructure Agent
Neo represents Pulumi's answer to the "velocity trap," where AI coding assistants make developers faster, but infrastructure teams can't keep up.

Neo offers progressive autonomy. Development environments might permit fully autonomous operation, like daily waste cleanup and weekly drift reconciliation. Production changes may require human approval. When Neo encounters unexpected states or errors, it can self-diagnose or loop in a human for assistance. As confidence builds, the autonomy boundary expands.
Formae: Rethinking IaC Fundamentals
In October 2025, Platform Engineering Labs launched Formae, challenging fundamental assumptions about how IaC should work. Let's learn about how it uses PKL and introduces a stateless approach.
The Problems Formae Solves
State file corruption and drift detection have plagued infrastructure teams forever. You know the scenario: someone makes a manual change in the console, your Terraform state drifts, and now you're spending hours reconciling reality with what your code thinks exists.
Traditional IaC tools require importing existing resources through a painful manual process, maintaining state files with corruption risk, detecting drift reactively, and reconciling manual changes in a time-consuming manner. Formae eliminates these issues by making reality itself the state.
Metastructure: A New Concept
Formae introduces "Metastructure," which combines infrastructure configuration with operational logic. Traditional IaC uses static configuration and planned state files, requires manual imports, performs periodic drift detection, and only manages tool-specific resources. Formae's Metastructure combines configuration with operational logic, uses reality as state, provides automatic discovery, performs continuous synchronization, and discovers all resources regardless of creation method.
Here's a PKL configuration example:
// infrastructure.pkl
module infrastructure
import "pkl:aws"
vpc: aws.VPC {
cidrBlock = "10.0.0.0/16"
tags {
["Name"] = "production-vpc"
}
}
instances: Listing<aws.EC2.Instance> {
new {
instanceType = "t3.large"
vpcId = vpc.id
}
}Brownfield Environments
Formae excels in brownfield environments where existing infrastructure needs code management. For existing AWS resources, traditional approaches require manually importing each resource, while Formae simply runs formae extract --target aws. For resources created via the console, traditional tools show drift detection alerts, but Formae automatically codifies and merges them. When using multiple management tools, traditional approaches face import conflicts, but Formae co-exists with all tools. The team learning curve is steep with tool-specific import syntax, but Formae makes it automatic with no imports needed.
Example workflow:
# Discover existing infrastructure
formae extract --target aws --output current-infrastructure.pkl
# Review and modify
vim current-infrastructure.pkl
# Apply changes
formae apply current-infrastructure.pklFormae automatically discovers and codifies existing infrastructure, eliminating painful import processes.
AI Infrastructure Provisioning: The Driving Force
Much of the IaC innovation in 2025 came from one driving force: provisioning and managing AI infrastructure at scale. Training frontier AI models requires coordination that makes traditional deployments look simple.
The AI Infrastructure Challenge
Let's understand the complexity through a diagram showing the full AI training infrastructure stack:
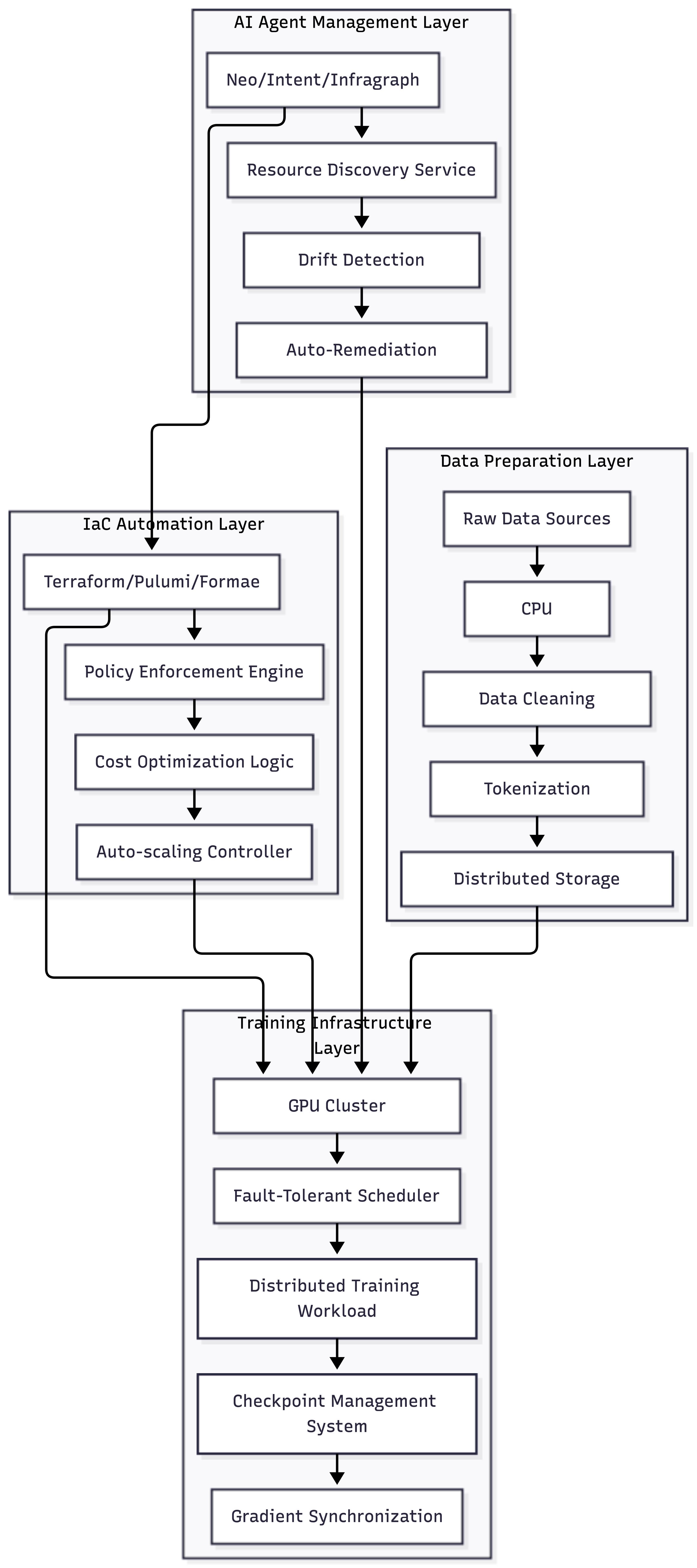
You're dealing with petabytes of data preparation across thousands of CPU cores. Massive GPU clusters running hot for months. Checkpoint management, where you lose hours of training because you didn't save state properly, costs real money. Gradient synchronization across hundreds of GPUs. Fault-tolerant scheduling where hardware failures become statistical certainties rather than edge cases.
Traditional applications use CPU-based compute running for minutes to hours, dealing with gigabytes of data, using standard retry logic for fault tolerance, having predictable costs, and scaling horizontally. AI training requires GPU clusters with hundreds of GPUs, runs for days to months, handles petabytes of data, needs checkpoint-based recovery with resumption on failure, has extremely high costs requiring constant optimization, and uses specialized distributed training approaches.
If you are new to the processing units world, learn about CPUs vs GPUs vs TPUs in this article.
Here's provisioning a GPU training environment with Pulumi:
import pulumi_gcp as gcp
cluster = gcp.container.Cluster(
"ai-training-cluster",
initial_node_count=1,
remove_default_node_pool=True,
location="us-central1-a"
)
gpu_node_pool = gcp.container.NodePool(
"a100-node-pool",
cluster=cluster.name,
location=cluster.location,
node_count=10,
node_config=gcp.container.NodePoolNodeConfigArgs(
machine_type="a2-highgpu-8g",
guest_accelerators=[
gcp.container.NodePoolNodeConfigGuestAcceleratorArgs(
type="nvidia-tesla-a100",
count=8
)
]
)
)
pulumi.export("cluster_name", cluster.name)Platform Engineering: The Abstraction Layer
Platform engineering emerged as a discipline providing self-service infrastructure catalogs. Instead of learning Terraform or Pulumi directly, developers select pre-built templates for common use cases, customize a few parameters, and get infrastructure that meets organizational standards.
The platform engineering stack consists of multiple layers working together. The self-service portal layer uses tools like Backstage, Port, and Humanitec to provide the developer interface. The IaC templates layer leverages Terraform modules and Pulumi components as reusable infrastructure patterns. Policy enforcement happens through OPA, Sentinel, or CrossGuard for governance and compliance. Deployment automation uses ArgoCD, Flux, or HCP Waypoint for GitOps workflows. Cost management relies on tools like Cloudability and Kubecost for spending visibility.
Here's a self-service database template:
import pulumi_aws as aws
class DatabaseService(pulumi.ComponentResource):
def __init__(self, name, args, opts=None):
super().__init__('custom:database:Service', name, None, opts)
self.db = aws.rds.Instance(
f"{name}-db",
engine="postgres",
instance_class=args.get("instance_class", "db.t3.medium"),
allocated_storage=args.get("storage_gb", 100),
storage_encrypted=True,
multi_az=args.get("environment") == "production",
opts=pulumi.ResourceOptions(parent=self)
)Developers use this without understanding RDS details:
user_database = DatabaseService(
"user-service-db",
args={
"database_name": "users",
"team": "backend-team",
"environment": "production"
}
)Security and Compliance in the AI Era
With AI tools generating more infrastructure code than ever, security validation has become critical. Google reports that 25% of its new code comes from AI, making automated security validation non-negotiable.
Essential security tools include Checkov for static analysis of misconfigurations, tfsec for Terraform-specific security scanning, Terrascan for policy-as-code security, OPA for runtime policy enforcement, and Sentinel as HashiCorp's policy framework. These tools integrate at different points: Checkov and tfsec run in pre-commit hooks and CI/CD pipelines, OPA validates at runtime, and Sentinel enforces policies within HCP Terraform.
Here's an example of how you might configure Checkov for your infrastructure repository:
# .checkov.yml
branch: main
download-external-modules: true
framework:
- terraform
- terraform_plan
- cloudformation
soft-fail: false
check:
- CKV_AWS_20 # S3 bucket encryption
- CKV_AWS_21 # S3 bucket versioning
- CKV_AWS_19 # S3 bucket logging
- CKV_AWS_18 # S3 bucket access logging
- CKV_AWS_145 # S3 bucket KMS encryption
- CKV2_AWS_6 # S3 bucket public access block
skip-check:
- CKV_AWS_23 # Skip unencrypted S3 for public static assets
output: cli
quiet: falseComprehensive IaC Platform Comparison
OpenTofu, the open-source fork created after HashiCorp's license change, continued gaining traction in 2025 under the Linux Foundation. Organizations appreciated having a community-driven alternative without vendor lock-in concerns.
Terraform uses the Business Source License, which is proprietary, while OpenTofu uses the Mozilla Public License 2.0. Governance differs significantly: Terraform is controlled by HashiCorp, which is now owned by IBM, while OpenTofu operates under the Linux Foundation with community governance. Terraform includes proprietary additions in its feature set, while OpenTofu maintains community-driven development. Enterprise support for Terraform comes through HCP Terraform, while OpenTofu relies on third-party vendors. Both maintain robust provider ecosystems, though Terraform's is officially backed by HashiCorp while OpenTofu's is community-maintained.
Terragrunt also announced its own Stacks feature reaching GA in May 2025, providing orchestration capabilities for teams in the OpenTofu ecosystem. Gruntwork built Terragrunt Stacks through extensive community engagement, with the RFC gathering dozens of positive reactions and hundreds of comments from participants.
After exploring the major developments in 2025, here's a comprehensive comparison of leading IaC platforms:
| Feature | Terraform | OpenTofu | Pulumi | Formae | CloudFormation | Crossplane |
|---|---|---|---|---|---|---|
| Language | HCL (proprietary) | HCL (open) | TypeScript, Python, Go, C#, Java | PKL | YAML/JSON | YAML (CRDs) |
| License | BSL (proprietary) | MPL 2.0 (open) | Apache 2.0 | FSL → Apache 2.0 | Proprietary (AWS) | Apache 2.0 |
| State Management | Local/remote files | Local/remote files | SaaS backend | Stateless (reality = state) | AWS-managed | Kubernetes etcd |
| Resource Discovery | Manual import | Manual import | Manual import | Automatic | Manual import | Kubernetes-native |
| Drift Detection | Periodic checks | Periodic checks | Periodic checks | Continuous sync | AWS-only | Controller-based |
| Testing Support | Limited | Limited | Native unit/integration | Built-in | Limited | Kubernetes tests |
| IDE Support | Basic | Basic | Full (LSP, completion) | PKL tooling | Basic | YAML validation |
| Learning Curve | Learn HCL DSL | Learn HCL DSL | Use existing language | Learn PKL | Learn CFN syntax | Learn K8s + CRDs |
| Multi-Cloud | Excellent | Excellent | Excellent | Growing | AWS only | Good |
| Provider Ecosystem | 3000+ providers | Community-maintained | 150+ packages | Early stage | AWS services | 80+ providers |
| AI Capabilities | MCP servers | None | Neo agent | None | None | None |
| Governance | HashiCorp/IBM | Linux Foundation | Pulumi Corp | Platform Eng Labs | AWS | CNCF |
| Best For | Mature ecosystems | Open governance | Developer teams | Brownfield envs | AWS-only shops | K8s-centric orgs |
| Brownfield Support | Manual process | Manual process | Manual process | Excellent | Manual process | K8s resources only |
| Enterprise Features | HCP Terraform | Third-party | Pulumi Cloud | Coming | AWS Orgs | Enterprise distros |
| Cost | Free/Enterprise | Free | Free/Team/Enterprise | Open source | Free (AWS costs) | Free |
| Deployment Speed | Moderate | Moderate | Fast | Fast | Moderate | Moderate |
| Community Size | Very large | Growing | Medium | Small | AWS community | Growing |
The Challenges That Remain
Despite progress, significant challenges persist. Only 6% achieved full codification. Configuration drift continues to plague teams. Multi-cloud complexity affects 65% of organizations. The human element remains crucial for defining policies, setting guardrails, and making architectural decisions.
Conclusion
The infrastructure community stands at an inflection point. Manual provisioning is legacy. The next frontier involves infrastructure that can observe its own state, reason about optimal configurations, and act autonomously.
Project Infragraph represents this future. AI agents will reason about infrastructure state and act across the application lifecycle. These agents won't replace infrastructure engineers, but they'll handle repetitive tasks that currently burn out teams.
As we close out 2025, one thing seems certain: infrastructure automation will only accelerate. The organizations that embrace these tools, invest in platform engineering, and leverage AI while maintaining proper guardrails will move faster than competitors still manually clicking through cloud consoles.
The infrastructure has become code. Now the code is becoming intelligent.
Opinions expressed by DZone contributors are their own.
Comments