Loading Streaming Data Into Cassandra Using Spark Structured Streaming
In this demo, learn how streaming data can be compatible with Cassandra and with Spark Structured Streaming as an intermediary.
Join the DZone community and get the full member experience.
Join For FreeWhen creating real-time data platforms, data streaming is a low-latency, high-throughput method of moving data. Where batch processing methods necessarily introduce delays in order to gather a batch worth of data, stream processing methods act on steam events as they occur, with as little delay as possible. In this blog and associated repo, we will discuss how streaming data can be compatible with Cassandra, with Spark Structured Streaming as an intermediary. Cassandra is designed for high-volume interactions and, thus, a great resource for streaming workflows. For simplicity and speed, we are using DataStax’s AstraDB in this demo.
Introduction
Streaming data is normally incompatible with standard SQL and NoSQL databases since they can consist of differently structured data with messages only differentiated by timestamp. With advances in database technologies and continuous development, many databases have evolved to better accommodate streaming data use cases. Additionally, there are specialized databases, such as time-series databases and stream processing systems, that are designed explicitly for handling streaming data with high efficiency and low latency.
AstraDB, however, is neither of those things. In order to overcome these hurdles, we need to make sure that the specific data stream we are working with has a rigid schema and that the timestamps associated with adding the individual messages to the stream are either all stored or all thrown out.
The Basics
We will create our example stream from the Alpha Vantage stock API, ensuring that all stream messages will have the same format. Inside those messages is a timestamp corresponding to when the data was generated, which we will use to organize the data so that we can ignore the timestamp associated with adding the message to the stream.
An API by itself is not a stream, so we turn it into one. We push this stream to Astra Streaming, Astra’s managed version of Apache Pulsar, but this does not mirror our data into Astra DB. So we set up a Spark cluster with the Spark Pulsar connector and the Spark Cassandra connector and write a program that ingests the stream, transforms the data to match the AstraDB table schema, and loads it into the database.
The Alpha Vantage API
The Alpha Vantage API is a REST API that provides historical data on stock values and trades over time intervals. We can query this API for the recent history of a specific stock symbol.
Astra Streaming
Astra Streaming is Astra’s managed Apache Pulsar instance. It can be used to read or write data streams and can be connected to in a variety of ways. In this demo, we use the Python driver and the spark pulsar connector.
Apache Spark
Spark is a distributed data processing tool. It is mostly known for batch processing capabilities, but Spark Streaming is one of its core components. Spark streaming allows spark users to process stream data using the same functions and methods that are used to process batch data. It does this by turning an incoming stream into a series of micro-batches and manages to process those in a low latency manner compatible with data streams.
Astra is a managed database based on Apache Cassandra. It retains Cassandra's horizontal scalability and distributed nature and comes with a number of other advantages. Today, we will use Astra as the final destination for our data.
Here’s a quick look at what will be happening in this demo.
Prerequisites
For this tutorial, you will need the following:
- An Astra Account from DataStax, or to be familiar enough with Cassandra to use an alternative Cassandra database.
- A tenant in Astra Streaming or access to an Apache Pulsar cluster
- An environment in which to run Python code. Make sure that you can install new pip modules in this environment. We’d recommend a Gitpod or your local machine.
- A Spark cluster. This demo contains the files and instructions necessary to create a single worker cluster.
- An Alpha Vantage API key.
For an effortless setup, we have provided a Gitpod quickstart option– though you’ll still need to fill in your own credentials before it will run seamlessly. Simply click on the “Open in Gitpod” button found in our GitHub repository to get started. Alternatively, go to this link to open the repo in Gitpod. When creating the workspace for this project, it is advantageous to select a large class of machines in order to ensure that enough memory exists on the machine to run the Spark cluster.
Before you can proceed further, you will need to set up your Astra database. After creating a free account, you will need to create a database within that account and create a Keyspace within that database. You will also need to create a tenant and topic within Astra Streaming. All of this can be done purely using the Astra UI.
Reminder: for this demo, the assumed name of the keyspace is spark_streaming.
Establishing the Schema
Once the Keyspace has been created, we need to create the Table that we will be using. That table’s name is stock_data. Open the CQL Console for the database and enter these lines to create your tables.
CREATE TABLE spark_streaming.stock_data (
symbol text,
time timestamp,
open decimal,
high decimal,
low decimal,
close decimal,
volume int,
PRIMARY KEY ((symbol), time));Next, we need to create the resources we need to connect to the Astra database. Hit the Connect button on the UI and download the Secure Connect Bundle (SCB). Then, hit the “Create a Token” button to create a Database Administrator token and download the text that it returns.
Load the SCB into the environment and put the path to it in the auth.py files' second line between the single quotes. Put the generated ID (Client_ID) for the Database Admin token in the third line. Put the generated secret (Client_Secret) for the token in the fourth line.
Creating Your Astra Streaming Topic
From the homepage of Datastax Astra, select streaming in the sidebar on the left.
Select the Create Tenant button and fill out the form to create a tenant.
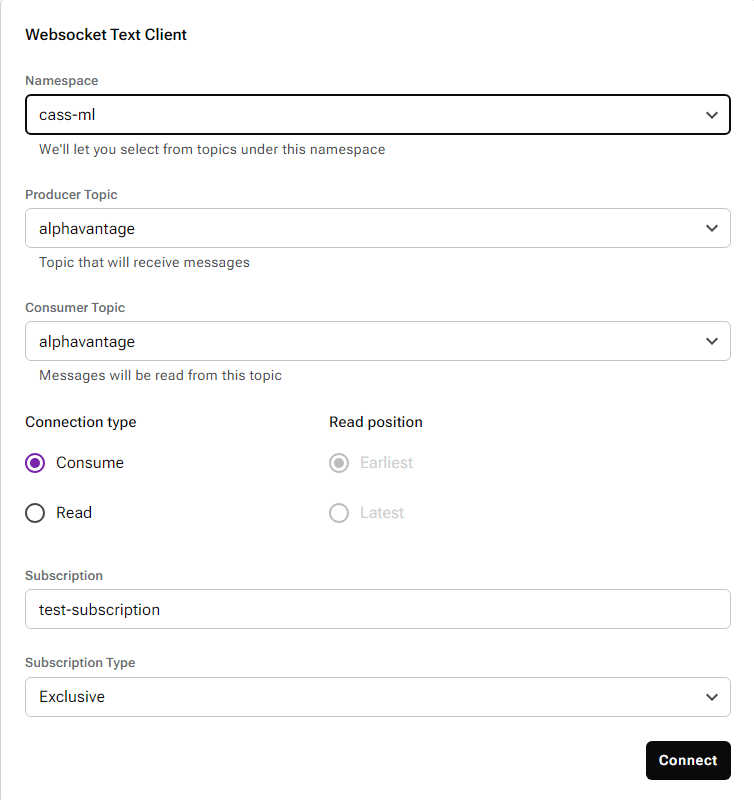
Open your tenant immediately, scroll down within the connect screen, and copy out the Broker Service URL and Web Service URL. Then go to settings on the top bar and scroll to Token Management. Copy your token and paste it into auth.py on line 8. You can then go back to Namespace and Topic and create a namespace and a topic within it. Then go to the Try Me tab and consume from your created topic. You will see the stream data here once our program reads it from Alpha Vantage.
Connecting to the Alpha Vantage API
Go to alphavantage.co and click to get a free API key.
Sign up for an API key. When it arrives, paste your key into auth.py on line 6.
Starting Your Spark Cluster
In your environment, run the script file ./spark-3.4.1-bin-hadoop3/sbin/start-master.sh to create the Spark Master. Open up port 8080 and copy the Spark Master address. Use that address as the argument and run the script ./spark-3.4.1-bin-hadoop3/sbin/start-worker.sh to create the Spark worker.
Running the Code
Once all of the setup is complete, you can run create_raw_stream.py to get data from the Alpha Vantage API and send it to Astra Streaming as a stream. You should be able to see the results in the Try Me tab within the Astra UI. Then, in order to process and upload that stream to AstraDB, you need to run the following Spark submit command.
./spark-3.4.1-bin-hadoop3/bin/spark-submit \
--master <Spark Master Address> \
--packages io.streamnative.connectors:pulsar-spark-connector_2.12:3.1.1.3,com.datastax.spark:spark-cassandra-connector_2.12:3.4.0 \
--conf spark.files=<bundle filepath> \
--conf spark.cassandra.connection.config.cloud.path=<bundle file name> \
--conf spark.cassandra.auth.username=<astra client id> \
--conf spark.cassandra.auth.password=<astra client secret> \
--conf spark.dse.continuousPagingEnabled=false \
<path to pyspark_stream_read.py>This command submits the file pyspark_stream_read.py to the Spark cluster while also telling Spark to download the Spark-cassandra-connector, and Pulsar-spark-connectors from Maven. We then pass the connection information for Astra, including the secure connect bundle, client id, and client secret.
After those have been run, we should be able to see the results in AstraDB. Open up your Database’s CQL console and type:
SELECT * FROM spark_streaming.stock_data limit 10;Conclusion
In this demo, you learned how to use Pulsar/Astra Streaming, Spark, SparkSQL, and AstraDB to turn an API into a stream, format the stream using Astra Streaming, and then write it to AstraDB.
While this demo focuses on using the Alpha Vantage API, you can use this stack to use a wide variety of data in an extract, transform, and load workflow. How you use the data once you get it is up to your imagination!
Getting Help
You can reach out to us on the Planet Cassandra Discord Server to get specific support for this demo. You can also reach out to the Astra team through the chat on Astra’s website. Enhance your enterprise’s data ingest by incorporating streaming data with Pulsar, Spark, and Cassandra. Happy Coding!
Published at DZone with permission of Patrick McFadin. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments