Modernizing Testing With Data Pipelines
Learn how data synthesis together with data pipelines can offer a scalable solution to create consistent data resembling real-world needs for testing systems.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Data Pipelines Trend Report.
For more:
Read the Report
Organizations today are buried in data. They collect data from a vast array of sources and are attempting to find ways to leverage this data to advance their business goals. One way of approaching this is to use data pipelines as a way of connecting to data sources and transforming the data through a pipeline into some form that is usable at the endpoint.
While this is part of the ongoing struggle to operationalize data for an organization, there is always a continuous need to find ways to provide good datasets for testing. Organizations need these datasets for testing both applications and systems throughout their architecture landscape. They also have needs for datasets to focus on testing aspects of their organization such as security and quality assurance.
There is a very real need for creating synthetic data. What this really means, in simple terms, is that we need to find a way to create fictitious or fake data. We want to create consistent data resembling real-world needs for testing systems. Let’s take a look at data pipelines and explore how this can be used to start creating your own synthetic data for testing in your organization.
Data Pipelines and Testing
A very simple definition of a data pipeline is "a set of data processing elements connected in series, where the output of one element is the input of the next one." More simply put, these are the fundamental connections used to bring data from a data source, back to the level where it can be analyzed, transformed, and then used by an organization.
Data pipelines start by retrieving data. They can pull the needed data from within a platform, such as SQL (DB) data sources, through a programmable interface such as an application programming interface (API), or through data streaming and event processing interfaces.
Once the data has been retrieved, a decision can be made to transform the data for end-user needs. This can be done with data generation APIs, data building by cleaning or changing the structure of the data retrieved, and finally, the data can be anonymized for security reasons before being presented to the end-users.
These are but a few examples of what a data pipeline can be used for as part of the testing process, and Figure 1 is a simple example of a data pipeline from sources to a final data warehouse location for further use.
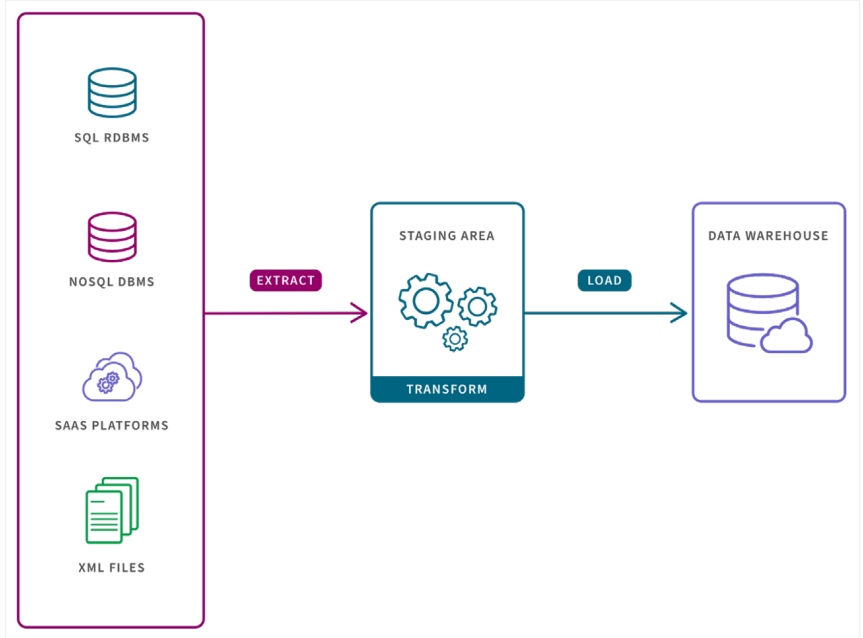
Testing requires us to provide a dataset to a system, application, or piece of code that is being tested. This set of data can be created manually, copied from an existing set of data, or generated for use by the testing team.
Manually creating test data can be useful when dealing with very small datasets, but it becomes very cumbersome when the need for huge datasets arises. Copying datasets from existing (production to test) environments comes with security and privacy issues if data contains sensitive elements. Generating data based on existing data can provide a good outcome.
What if we want to generate data at scale, with security in mind to provide for anonymized results, and ensure flexibility with regards to what is being generated? This is where data synthesis comes in. It allows you to generate data with the flexibility you might need.
Data Synthesis for Beginners
Generating synthetic data can provide massive amounts of data while addressing sensitive data elements. Synthetic data can be based on critical data dimensions like names, address, phone numbers, account numbers, social security, credit cards, identifiers, driver's license numbers, and more.
Synthetic data is defined as fake or created data, but it’s often based on real data that is used to expand to create larger, realistic datasets for testing. The data generated for testing is then made available across the organization for business users and developer needs in a secure and scalable manner.
There is a vast array of uses for this synthetic data across any organization, such as healthcare, finance, manufacturing, and any other domains that are adopting new technologies for various business needs. Its direct usage is in ongoing testing, security, and quality assurance practices to help with implementation, application development, integration, and data science efforts.
Not only are you able to provide datasets at scale with data synthesis, but it also ensures support for data consistency across multiple domains in an organization while providing viable data representing real-world formats. It provides a consistent approach across any organization for developers, architects, and data architects to leverage data for testing.
Getting Started With Data Synthesis
The best way to discover what data synthesis can do for you is to explore the most common usage patterns and then dive into an open-source project to jump-start your experience. There are two simple patterns for getting started with data synthesis: in cloud-native environments and with cloud-native APIs, as shown in Figure 2.
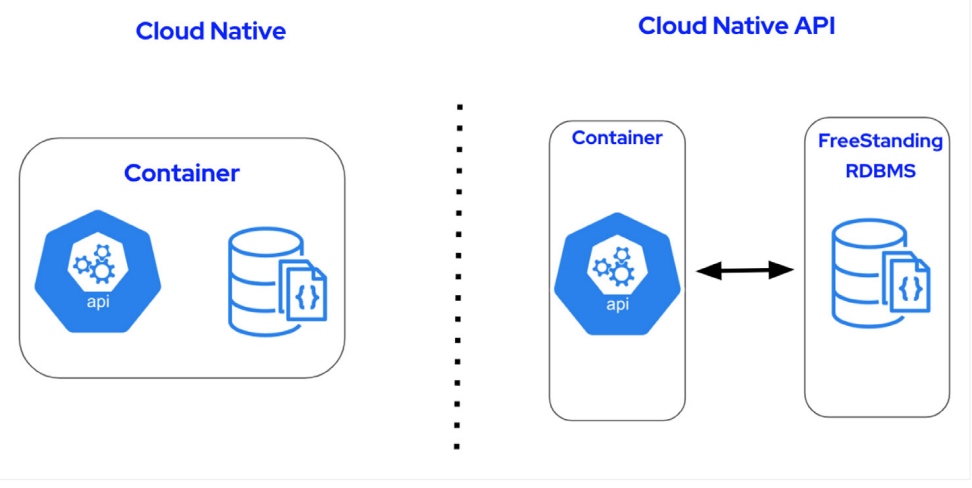
Figure 2
The first pattern is where you run the data synthesis platform within a single container on a cloud platform of your choice and leverage the API to pull data from sources in the container, such as applications or databases. The second is where you can deploy the data synthesis platform on a cloud platform of your choice and leverage cloud-native APIs to pull data from any source, such as external free-standing data sources.
Data synthesis shines in the following use cases:
- Retrieving needed data within the platform (SQL)
- Data retrieval (APIs)
- Data generation (APIs)
- Building more fictitious data on-demand or scheduled
- Data building
- Building more structured data based on fictitious data on-demand or scheduled
- Creating structured or unstructured data that meets your needs
- Streaming industry-centric data
- Using the data pipeline to process various industry-standard data
- De-identification and anonymization by parsing and populating from real-time systems to provide real-world attributes
Covering each of these use cases goes beyond the scope of this article, but this list gives the reader a good idea of the fields of applicability for data synthesis and testing. For an overview of the data synthesis data tier, we present the following figure:
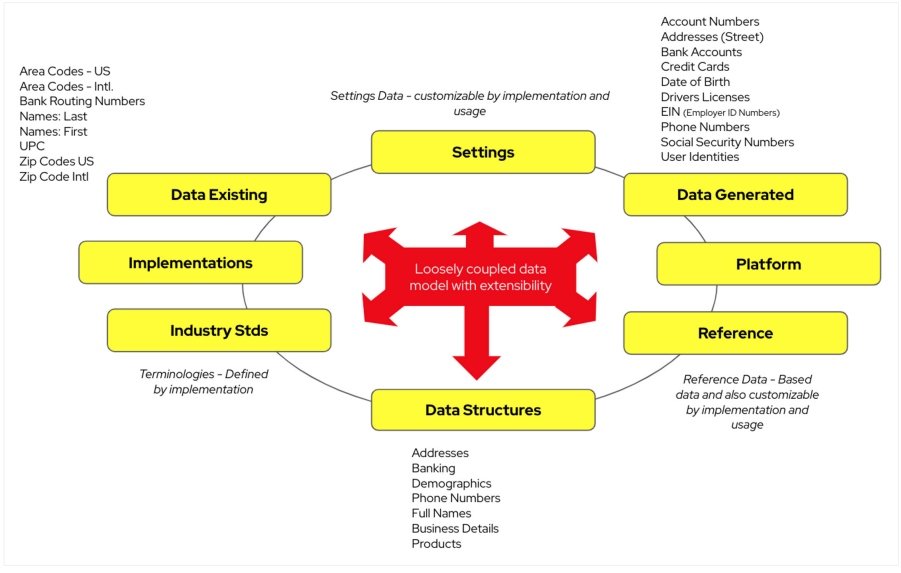
Figure 3
This is an overview of the data tier and how the platform ties it all together using United States location data fields (zip codes and area codes) as an example. In the center, you can see your loosely coupled data models that can be extended as needed. They form the core basis for accessing from existing data, implementation data, and industry-standard data. This can be adjusted using data settings and based on existing data structures in your organization. The output is the generated data, reference data, and platform-specific data.
After this short tour of data synthesis, the next step is to start exploring the open-source project known as Project Herophilus, where you can get started with the data synthesis platform.
You will find the key beginning areas for data synthesis:
- Data tier – Designed to be extensible and support all the needs for the platform.
- Data tier APIs – Supporting the needs of user requests are the data tier APIs; this API set is about being able to both generate data and persist it to the data tier.
- Web UI(s) – Intended to be minimum viable usable products that can be used to look at the data synthesis data tier you implement.
The three modules in the data synthesis project should get you well on your way as a quick start to developing your testing datasets.
Conclusion
As organizations collect, explore, transform, and try to leverage their data, testing is a constantly growing challenge. While generating testing datasets can solve some of these issues, it often fails when the process needs to scale. Data synthesis, together with data pipelines, can offer a scalable solution to create consistent data resembling real-world needs for testing systems. You can get started by exploring the open-source project known as Herophilus, which offers three modules to kickstart your first data synthesis project.
This is an article from DZone's 2022 Data Pipelines Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments