Security Attacks: Analysis of Machine Learning Models
Want to learn more about security for machine learning models? Check out this post to learn more about ML, security, attacks, and more.
Join the DZone community and get the full member experience.
Join For FreeHave you wondered what would it be like to have your machine learning (ML) models under security attack? In other words, have you given much thought to what would happen if your machine learning models were hacked? And, have you thought through how to monitor such security attacks on your AI models? As a data scientist and machine learning researcher, it would be good to know some of the scenarios related to attacks on ML models.
In this post, we will address the following aspects related to security attacks (hacking) on machine learning models.
- Examples of security attacks on ML models
- Hacking machine learning (ML) models means…?
- Different types of security attacks
- Monitoring security attacks
Examples of Security Attacks on ML Models
Most of the time, in my opinion, it is the classification models that would come under the security attacks. The following are some of the examples:
- Spam messages’ filters are trained with adversary data sets to incorrectly classify spam messages as good messages, leading to compromising of system’s integrity. Alternatively, the Spam messages’ filter trained inappropriately to block the good messages, thereby, compromises a system’s availability.
- Classification models, such as loan sanction models, which could result in classifying the possible defaulter as a good one, could lead to the approval of loans that could later result in a business loss.
- Classification models, such as credit risk models, could be trained with adversary datasets to classify the business/buyer incorrectly and allow greater credit risk exposures.
- Classification models, such as insurance, could be trained inappropriately to offer greater discounts to a section of users, which would lead to business loss. Alternatively, models trained inappropriately to approve the insurance for those who are not qualified.
Hacking Machine Learning (ML) Models Means…?
The machine learning model can be hacked in the following scenarios:
- Compromising ML Models Integrity: In case that the ML models fail to filter one or more negative cases, the ML model can be hacked. This would mean that the integrity of the system gets compromised in the sense that negative cases sneak past the system. Consider an example of the SPAM filter. Attackers could devise messages that consist of spam words but do not get caught by the SPAM filter. This is achieved using exploratory testing. Once attackers gain success in identifying the spam messages, which bypass the SPAM filter, they could send regular messages that result in the inclusion of such messages in retraining of the model at a later date. After the updated model is deployed, attackers could then run a spam email campaign, which would bypass the SPAM filter and, thereby, compromise the SPAM filter integrity.
- Compromising ML Models Availability: In case the ML models start filtering out legitimate cases, the ML model can be said to be hacked. This would mean that the ML model is made unavailable. In other words, it is like a denial of service (DOS) attack where legitimate cases fail to pass through the system and compromise the system availability. For example, let’s say the attacker/hacker sends some benign words with spam messages that get filtered by the SPAM filter. In the future, the SPAM filter gets retrained with messages consisting of both SPAM and benign words, which result in the filtering of a certain class of benign email as SPAM messages.
Different Types of Security Attacks
The following diagram represents the flow of security attacks (Threat Model) on the ML models:
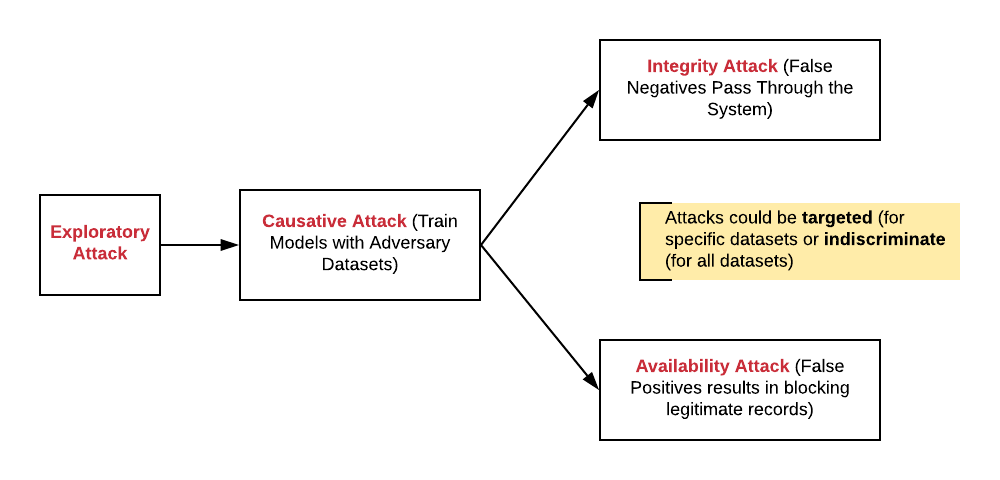
Fig. Threat Model: Security Attacks on Machine Learning Models
The following are different types of security attacks, which could be made on machine learning models:
- Exploratory attacks representing attackers trying to understand model predictions vis-a-vis input records. The primary goal of this attack would often go unnoticed by the system, which is to understand that model behavior vis-a-vis features vis-a-vis features value. The attack could be related to targeting a specific class of input values or targeting all kind of input values. The attack is to understand the input records values, which would result in compromising ML models integrity (false negatives) and devising input records that would result in compromising ML models availability (false positives).
- Exploratory attacks could be used to identify the model’s behavior in a specific class of data. This can also be termed as the targeted exploratory attack.
- Exploratory attacks could be used to identify the model’s behavior on all kinds of data. This can also be termed as the indiscriminate exploratory attack.
- Causative attacks resulting in altering training data and related model: Based on exploratory attacks, the attacker could create appropriate input records that pass through the system at regular intervals, resulting in a model either letting the bad records sneak in or blocking good records that pass through. Alternatively, attackers could hack the system and alter training data at large. When the model, later, gets trained with the training data, it allows attackers to either compromise the systems integrity or its availability, as described in the above section.
- Integrity attacks compromising system’s integrity: With the model trained with attackers’ data allowing the bad inputs to pass through the system, the attacker could, on a regular basis, compromise the systems’ integrity by having the system label bad input as good ones. This is similar to system labeling — the bad records are incorrectly labeled as negative, which can also be called a false negative.
- Availability attacks compromising system’s availability: With the model trained with attackers’ data, allowing the good inputs to get filtered through the system, the system would end up filtering out legitimate records by false terming them as positive. This is similar to system labeling the good input record as positive, which later turns out to be a false positive.
Monitoring Security Attacks
The following are some thoughts regarding how one could go about monitoring security attacks:
- Review the training data at regular intervals to identify the adversary data sets lurking in the training dataset. This could be done with both product managers/business analyst and data scientist taking part in the data review.
- Review the test data and model predictions
- Perform random testing and review the outcomes/predictions. This could also be termed as security vulnerability testing. Product managers/business analysts should be involved in identifying the test datasets for security vulnerability testing.
References
Summary
In this post, you learned about different aspects of security attacks/ hacking of machine learning models. Primarily, the machine learning models could be said to be compromised if it fails to label the bad input data accurately due to attackers/hackers exploring attacks scenario, and hacking the training data sets appropriate to alter the ML model performance. Machine learning models’ integrity gets compromised if it lets bad data pass through the system (false negative). Machine learning models’ availability gets compromised if it blocks or filters good data from passing through the system (false positive).
Published at DZone with permission of Ajitesh Kumar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments