The Key Differences Between SLI, SLO, and SLA in SRE
In this blog, let's explore the key differences between these basic site reliability metrics and their implications for building a sustainable and reliable product.
Join the DZone community and get the full member experience.
Join For FreeFraming SRE metrics for building or scaling a product is quite a daunting task.
In an SRE journey, the process of embracing risks and resolving them by proper service-level metrics are known to be the best way to achieve reliability.
In this blog, let's explore the key differences between these basic site reliability metrics and their implications for building a sustainable and reliable product.
What Are the Differences Between SLIs, SLOs, and SLAs?
SRE practices are now becoming more prevalent and much sought after best practices. And the prerequisite of success in SRE is availability.
These acronyms — SLIs, SLOs, and SLAs — are the primary metrics of Site Reliability Engineering (SRE).
Service Level Indicators (SLIs)
SLI, as defined in Google’s SRE Handbook, is 'A carefully defined quantitative measure of some aspect of the level of service that is provided.'
SLIs are measurements of the characteristics of a service. SLI’s directly gauge those behaviours that have the greatest impact on the customer experience. The most common SLIs or Four Golden signals are:
Latency
Traffic
Error rate
Saturation
Other variations are USE (Utilization, Saturation, and Errors) and RED (Rate, Error, and Durability).
The formula used to calculate SLI is:
SLI = Good Events * 100 / Valid Events
If the value of SLI is 100, the performance of the system is ideal and if it drops to 0, the system is broken.
It is Product (Service) - Centric, which means it always revolves around measuring the capabilities or characteristics of a product or service.
Service Level Objectives (SLOs)
SLOs are key threshold values for each SLI that quantify the availability and quality of service. They are an objective measure of your product’s reliability, or performance goals.
SLOs as explained in Google’s SRE workbook, 'Service level objectives (SLOs) specify a target level for the reliability of your service. Because SLOs are key to making data-driven decisions about reliability, they’re at the core of SRE practices.'
These are numerical reliability or performance targets that a developer or an SRE should maintain while building and scaling a product. Any changes in the product or service must fall under these defined target values.
You can implement small changes in defining your SLOs by adopting the SMART (Specific, Measurable, Achievable, Relevant, and Time-bound) strategy in crafting the right SLOs for your business.
SLOs should be Customer-centric, they should be directly related to the customer experience. The core purpose of SLOs is to quantify the customer reliability of the product and services.
SLOs can also be used to drive other improvements. For example, you could set an SLO for the backup duration if you wanted to maintain or improve it.
Service Level Agreement (SLA)
SLA is an agreement between the service provider and customer about service deliverables.
With an SLA, the consumer would have a clear idea about the proposed product or service in terms of functionality, reliability, and performance.
Google’s CRE Life lessons define SLA as 'An SLA normally involves a promise to someone using your service that its availability should meet a certain level over a certain period, and if it fails to do so then some kind of penalty will be paid.'
SLAs are Vendor-User agreement and a Customer-centric metric that defines the committed functionality, performance, and reliability of a product or service as well as the penalty for non-compliance. It also helps in establishing transparency and trust between the company and its customers. And if the company breaches the terms agreed in the SLA then it is liable to reimburse the loss incurred for its customers.
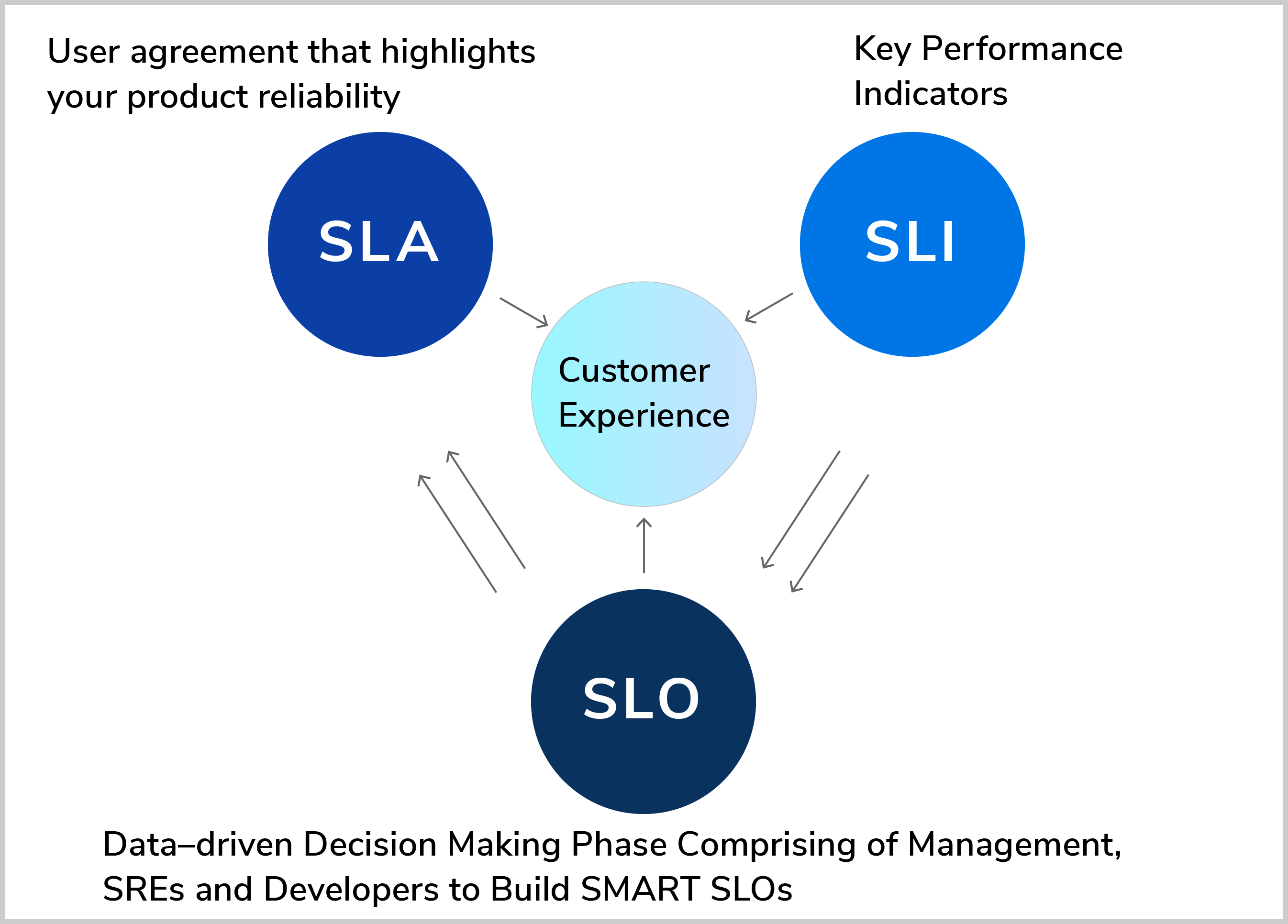
How These SRE Metrics Help in Drafting System Performance and Reliability
If you are a business that sells any product or service to your customers and assures them about your product capabilities, then you should draft your SLI, SLO, and SLA now!
These service-level metrics would help you gain customer trust and improve your system reliability and performance.
As a service provider/vendor, you should start by coming up with key performance indicators that measure your product's performance, which forms your SLIs. Remember these are a direct measure of your system’s behaviour in every stage of your business.
Secondly, you have to set targets of availability for achieving these indicators, which forms your SLOs. This is a completely data-driven phase where you have to accumulate the data from customer queries, stakeholders' expectations, find the insights, and finalize the target/threshold values to achieve better reliability.
As the final step, you should create your SLAs. Here you have to list out the reliability values and help them understand your product's capabilities.
Thus, SLIs are the foundational blocks that help in building SLOs which in turn helps with the overall reliability mentioned in your SLAs.

How to Improve Customer Experiences With Right Target Values (SLOs)
Customer experience plays an important part in deciding key SRE metrics. SLOs are the focus points in deciding the assured system reliability the company would offer to the end-users.
Choosing the Target Values
Choosing the appropriate SLOs or target values is in itself a complex technique!
Here are few key practices that can help you in deciding the right SLOs.
The target value of a service level is always measured only by an SLI.
There is an intricate dependency between SLIs and SLOs. This forms as a controlling characteristic while measuring and monitoring the entire system architecture. So, according to Google,
'A natural structure for SLOs is thus SLI ≤ target, or lower bound ≤ SLI ≤ upper bound.'
Lower bound SLOs ≤ SLI ≤ Upper bound SLOs.
What Should You Do While Choosing the Right SLOs?
Never choose targets/SLOs based on the current performance of your systems, choose from your historic performances.
Keep it simple — Don't specify absolute target values as SLOs.
Don't aim for over-achievement or perfection, reliability cannot be 100%.
Always keep a safety margin in SLOs, say like setting a historical average of your availability SLOs.
Only choose SLOs that are sufficient to cover attributes of the system, which means have only a few SLOs.
While drafting SLAs, always remember; Reliability values in SLAs < Historical Average of your availability SLOs.
Defining the Target Values (SLOs) in Practice
Google emphasizes the importance of defining the objectives in practice:
'SLOs should specify how they’re measured and the conditions under which they’re valid.'
SLOs can never be 100%. But we can specify the limit of up to which constraint of time we can achieve the assured reliability. For example, you can specify the SLO targets in the performance curve as,
99.9% of SLO would complete a task in less than 100ms.
99% of SLO would complete a task in less than 10ms.
90% of SLO would complete a task in less than 1 ms.
This is where Error budgets in SRE come in handy, a rate at which SLOs can be missed. This provides a clear, objective metric that helps determine how unreliable service is allowed for a specific time. It also helps to establish a balance between reliability and innovation. According to Google's SRE book, 'An error budget is just an SLO for meeting other SLOs!'
Error Budgets
Google's Motivation for Error Budgets, defines Error Budget as,
'the tool SRE uses to balance service reliability with the pace of innovation.'
'the amount of error that your service can accumulate over a certain period before your users start being unhappy.'
SLI is expressed as a percentage, and the objectives derived from SLIs are the SLOs. Now, the error budget is the remainder value of the SLOs mentioned.
The formula for error budget is,
Error Budget = [100 - Internal Availability SLOs] (in %)
So, in the above example, if the internal availability SLO is 99.95%, then the corresponding error budget would be (100-99.5) 0.05%. That is, you can serve up to or below the error of 0.05%.
According to Google's SRE blog, you have to measure every service you offer with an availability SLO, without which you cannot decide on making your systems more reliable. And if you assure the services to be more reliable, then the cost to operate will be expensive. So, by quantifying your services with availability SLOs you can either allow greater momentum for product development (but less reliable) or make your systems more reliable (but slow in product development).
And to improve your services you can build 'deemed SLIs' or approximate SLIs to measure customer reliability of your platform at a very granular level. This contributes to measuring low-level outages and drives the operational response with which you can refine your customer expectations. This, in turn, helps you in scaling your product for a better customer experience.
Setting SLOs according to Customer Expectations
Set an SLO buffer, which would help in accommodating the maintenance window, improve the performance of the system without disappointing the users
Restrict over-dependence between the services that which drags down other services and takes a longer time to load
While drafting an SLA, business and legal teams are required to pick appropriate consequences and penalties, in the event the agreement is breached. An SRE in the team helps them understand the likelihood and difficulty of meeting the SLOs contained in the SLA.
Be smart and conservative while you advertise your services’ SLOs because you cannot delete any of the SLAs that are not achievable
Key Takeaways
You should prioritize setting up your availability SLOs than your SLAs.
Make sure you mention the value of reliability in the SLAs slightly lower than the historical average of your availability SLOs. This is to safeguard against the average being high because a failure has not occurred yet.
If your MTBF (mean time between failures) is 18 months and your service is only 6 months old then the measured SLA will be artificially high.
Also, if you ensure the reliability value greater than or equal to your availability SLO, then your team would lose the buffer between your goal and the penalty level.
Your accumulated errors for a certain period should fall within the Error budget calculated. If not then you will be breaching the SLAs and that would correspond to financial loss.
Conclusion
Delivering product value solely depends on the performance and reliability of your services. Service level metrics act as a key tool to measure and quantify the capabilities of your product/service.
And, yes, it is necessary to define the path of how you are going to deliver the commitment towards 'always-on' services. Appropriate SLOs and SLIs will help you define that path.
Hope that this article has helped you understand SLIs, SLOs, and SLAs in a better way so that you can use them in improving your customer experience and overall product and service capabilities.
Published at DZone with permission of Merlyn Shelley. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments