Loop Engineering: The Layer After Prompt, Context, and Harness Engineering
This article walks through all four layers side by side, with comparison tables for when to use each one and which agent architecture fits which job.
Join the DZone community and get the full member experience.
Join For FreeA few weeks ago, I read a line from Boris Cherny, the person behind Claude Code, that stuck with me. He said he does not prompt Claude anymore. He has loops running, and those loops are the ones prompting Claude and deciding what to do next.
I sat with that for a while. For two years, every guide on working with AI agents told us to get better at writing instructions. Then it told us to get better at feeding the model the right information. Then it told us to build proper scaffolding around the agent so that it behaves like trustworthy software. Now there is a fourth layer, and it is less about talking to the agent and more about building a small system that talks to the agent for you. People are calling it loop engineering.
This piece walks through how we got here, what loop engineering actually means in plain terms, and where it fits next to the three ideas that came before it: prompt engineering, context engineering, and harness engineering. I have written about the first two before, so I will link back to those pieces where it helps rather than repeat myself.
How we got here:
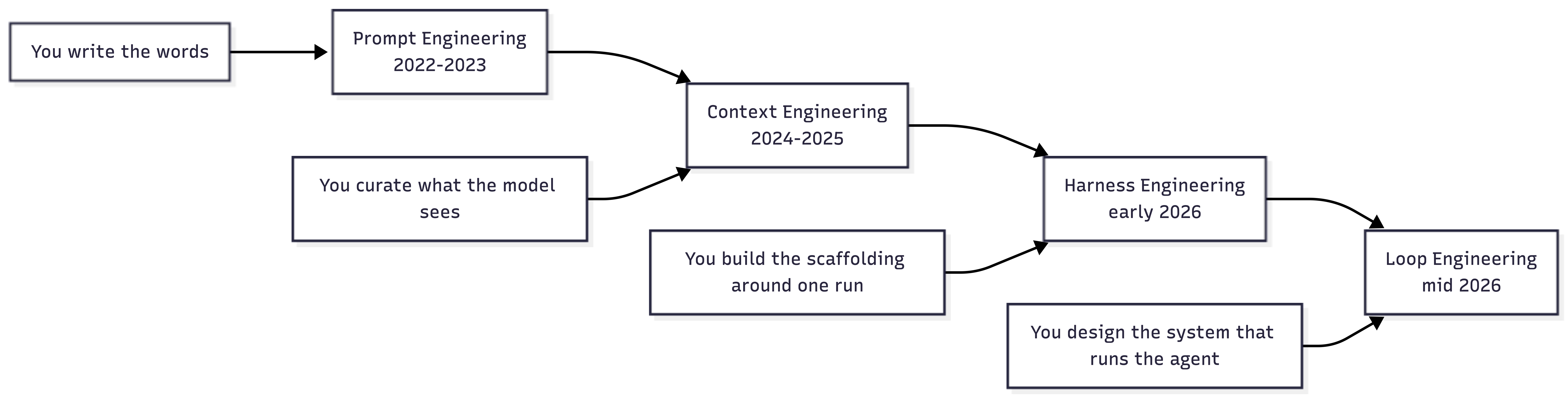
Each layer did not replace the one before it. It sat on top of it. You still write prompts. You still manage context. You just stopped being the one doing it by hand for every single turn.
Here is the short version, side by side, before we go into each one in detail:
| Layer | What you are actually doing | Where the skill lives | Good fit for | Weak fit for | What breaks if you skip it |
|---|---|---|---|---|---|
| Prompt engineering | Writing clear instructions for one turn | The words in the message | One-off questions, demos, quick scripts, learning a new model | Repeated workflows, anything that touches production data | Inconsistent answers, works once and fails the next ten times |
| Context engineering | Choosing what the model gets to see before it answers | The data, documents, and tool outputs around the prompt | RAG systems, chatbots over live data, anything where the model needs facts it was not trained on | Tasks where the prompt alone is already enough | Confident, well-written, wrong answers |
| Harness engineering | Building the scaffolding that checks the agent's work | The system around one agent run: tools, evals, guardrails, logs | Coding agents, multi-step automations, anything running without a human reading every step | Simple single-call requests with no follow-up actions | Agents that quietly do the wrong thing and nobody notices until later |
| Loop engineering | Designing the system that decides what to run next, on its own | The control loop sitting above the agent and its harness | Long-running or unattended work, backlog grooming, overnight batches, anything with a clear goal and a way to prove it is done | Tasks with a vague goal or no real way to check success | Loops that run for hours, spend budget, and produce work nobody asked for |
This table is the map for the rest of the piece. Each section below goes one layer deeper.
Prompt Engineering: Where It All Started
Prompt engineering was the first skill anyone associated with getting good output from a language model. Phrase the question well, give an example or two, ask the model to think step by step, and the answer gets better. It worked, and it still works for one-off tasks. The problem showed up once people tried to run the same model on a real workflow, again and again, across different inputs. A clever sentence that worked once does not hold up across a thousand runs with messy, real-world data.
The short version is this: prompt engineering is great for experiments and demos, but production systems need something steadier than a well-worded sentence.
Context Engineering: The Model Needed More Than Nice Words
Context engineering showed up once teams realized that the actual bottleneck was rarely the phrasing. It was what the model could see. A model with a perfect prompt and no access to the right document, the right database row, or the right tool output will still guess wrong. Tobi Lütke from Shopify put it simply: context engineering is the art of giving the model everything it needs so the task is actually solvable. Andrej Karpathy described it as the careful science of filling the context window with exactly the right information for the next step, not more, not less.
By late 2025, prompt engineering had become something people did inside context engineering rather than a separate skill on its own.
Harness Engineering: Making One Agent Run Trustworthy
Once teams started letting agents take multiple steps on their own, a new problem appeared. The agent might write code, run a test, look at the failure, and try again. That loop within a single task needed rules. What tools can it call? What happens if it gets stuck? How do you stop it from quietly making the wrong change to a file it was never supposed to touch?
This is harness engineering, and I spent a full piece on it earlier this year in From Prompts to Harnesses: How AI Engineering Has Grown Up. The short version: prompt engineering got the conversation started, context engineering made the answers consistent, and harness engineering is what actually makes an agent safe to run in production, because it stops depending on the model behaving well and starts depending on a system around the model that checks its work. Think of the harness as the seatbelt, the dashboard, and the guardrails for one agent doing one job. It covers things like giving the agent a clean view of the repository, exposing the right API contracts, watching logs and live CI status as part of its context, and building eval gates that catch bad output before it ships.
I went deeper into one well-known pattern for this layer in The Twelve-Factor Agents: Building Production-Ready LLM Applications, borrowing from the original Twelve-Factor App rules and adapting them for agents: one clear purpose per agent, explicit dependencies, and a strong separation between business logic and execution state. I also looked at the architectural side of this in AI Agent Architectures: Patterns, Applications, and Implementation Guide, where orchestrator-worker setups and blackboard-style coordination turn out to be different ways of answering the same question a harness has to answer: who is allowed to do what, and who checks the result.
Picking an architecture for the agents inside your harness is its own decision, and it is worth slowing down on, because the wrong pattern for the job tends to show up as flaky behavior that looks like a model problem but is actually a structure problem:
| Architecture | How it works | Best for | Watch out for |
|---|---|---|---|
| Single agent | One agent, one prompt loop, one set of tools | Simple, well-bounded tasks like answering support tickets or summarizing a document | Falls apart fast once the task needs more than a handful of steps |
| Orchestrator-worker | A central agent breaks the job into pieces and hands each piece to a specialist agent | Tasks that can be cleanly split, like "research this, then write this, then format this" | The orchestrator becomes a single point of failure if it makes a bad plan early on |
| Blackboard | Agents post partial answers to a shared space and pick up work opportunistically, with no central controller | Open-ended problems where the right order of steps is not known in advance, like diagnosis or research | Harder to debug, since there is no one place that decided what happens next |
| Event-driven | Agents react to events as they happen rather than being called in a fixed order | Systems that need to respond to changes in real time, like monitoring or alerting | Needs solid event delivery guarantees, or agents miss things silently |
| Graph or loop-based | A loop or graph decides which agent or sub-agent runs next, based on state and results so far | Long-running, multi-stage work where the next step depends on what the last step found | The whole thing is only as reliable as the state tracking and the checks between steps |
None of this works without the layer underneath it, either. The compute, storage, and serving choices that decide whether a harness can actually run reliably at scale are covered in AI Infrastructure for Agents and LLMs: Options, Tools, and Optimization and its follow-up, AI Infrastructure Guide: Tools, Frameworks, and Architecture Flows. And because a harness is still software that needs to be deployed and rolled back like anything else, Infrastructure as Code: How Automation Evolved to Power AI Workloads walks through why pinning model versions in config, the same way you pin a database connection string, has become a basic rule rather than a nice-to-have. I rounded up some of the tools doing this well in Developer Tools That Actually Matter in 2026.
There is also a second, smaller decision inside the harness itself: what kind of check are you actually running at each step? Some checks are deterministic and cheap; others are judgment calls made by another model. Both have a place, and most solid harnesses use a mix:
| Check type | What it means | Example | Speed and cost | Reliability |
|---|---|---|---|---|
| Computational | A fixed rule, run by regular code | Unit tests, linters, type checkers, schema validation | Fast and cheap | Very reliable, but only catches what you thought to check for |
| Inferential | Another model judges the output | LLM-as-judge review, an AI code reviewer, a second model checking tone or factual accuracy | Slower and more expensive | Catches fuzzier problems, but can itself be wrong or inconsistent |
For the fuller operational picture, the practices around monitoring, cost control, and incident response for agents running in production are laid out in the Shipping Production-Grade AI Agents refcard, including a simple three-question framework for any agent incident: what was the agent trying to do, what did it actually do, and what state did it change in the outside world.
Harness engineering solved a real problem: it made a single agent run safe enough to trust. But it still assumed a person was sitting there, kicking off the run, reading the result, and deciding what happens next.
Loop Engineering: Stop Being the One Who Presses the Button
This is the part that changed in 2026. Geoffrey Huntley, earlier in the year, described running a coding agent inside a plain loop in his terminal: give it the same prompt against a written spec, let it pick one task, implement it, then start a fresh copy of the agent and feed it the same prompt again. People started calling this the Ralph technique, after the simple while loop running underneath it. It looked almost too basic to matter, but it worked, and it pointed at something bigger.
Loop engineering takes that idea and makes it a discipline. Instead of typing a prompt, reading the answer, and typing the next prompt yourself, you build a small system that does that cycle for you. It checks what work is pending, decides what an agent should try next, hands the task off, checks whether the result actually meets the goal, saves what it learned, and either stops or starts the cycle again. Addy Osmani, who wrote one of the essays that got this term moving, framed it well: loop engineering means replacing yourself as the one who prompts the agent. You design the system that prompts it instead.
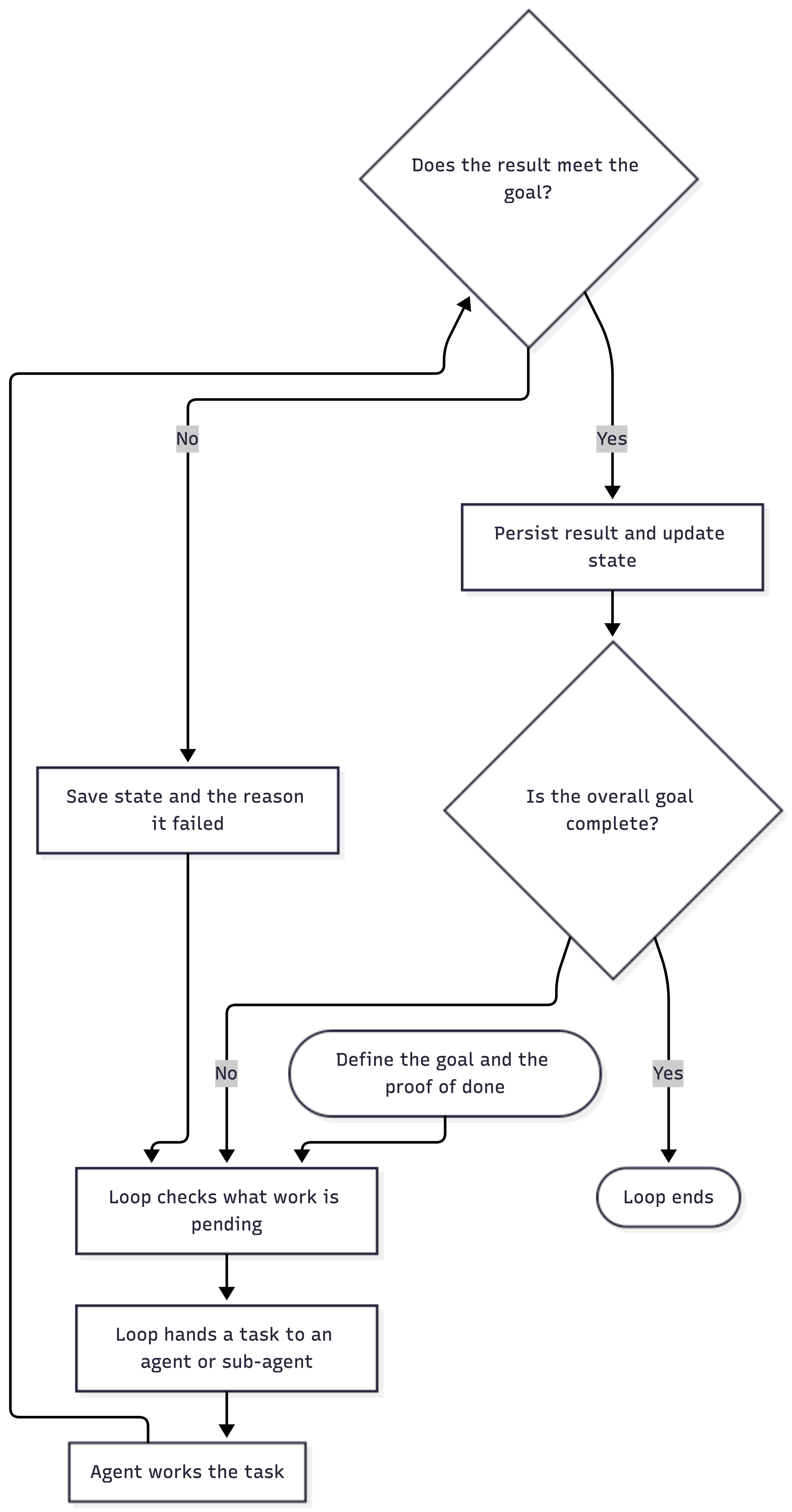
A few things matter a lot once you build one of these:
The goal has to be provable, not just stated. "Make the checkout flow better" gives a loop nothing to check itself against, so it will stop whenever it feels like it has done enough, which is rarely what you wanted. People running these loops for real work have settled on writing out the end state they expect, the proof needed to show it was reached, the rules that cannot be broken along the way, and a hard limit on how long or how much the loop is allowed to run.
The verifier is the actual bottleneck, not the model. A loop is only as good as its ability to tell good work from bad work. If the check at the end of each cycle is weak, the loop will happily mark broken work as done and move on. Most of the engineering effort in a good loop goes into that verification step, not into the prompt that kicks the agent off.
Prompts and context did not disappear, they moved inside the loop. The loop is still writing prompts and assembling context on every cycle. It is just doing it itself, using the same context engineering ideas from earlier, instead of a person typing it fresh each time. This is why I think of loop engineering as sitting on top of the other three rather than replacing any of them.
Not every loop looks the same, either. Once you decide a loop is the right tool, the next choice is how tightly you want to hold its leash:
| Loop style | How it runs | Good for | Risk |
|---|---|---|---|
| Closed loop, human approves each step | Loop proposes the next action, a person clicks approve | High-stakes changes, early days of trusting a new loop | Slow, defeats some of the point if you approve everything anyway |
| Open loop, runs to a budget or time limit | Loop runs unattended until it hits a turn limit, a cost cap, or finishes the goal | Overnight batches, backlog grooming, well-scoped refactors | Can burn budget on the wrong thing if the goal or verifier is weak |
| Single agent in a plain loop (the Ralph style) | One agent, one spec, fresh instance each cycle, no memory carried forward except what is written to disk | Small, well-defined coding tasks where starting fresh each time avoids the agent confusing itself | Repeats work it has no memory of, and needs a very clear spec to avoid drifting |
| Orchestrated loop with sub-agents | A controlling loop spawns specialized sub-agents for different parts of the task and merges results | Larger goals that naturally split into independent pieces | Coordination overhead, and a weak verifier at the merge step undoes everything underneath it |
Where This Connects to the Bigger Picture
None of these lives in isolation. A loop that spawns multiple agents to work on different pieces of a task at the same time needs the kind of coordination covered by multi-agent orchestration work, including how agents talk to tools through the Model Context Protocol and to each other through agent-to-agent protocols. And every loop running unattended for hours needs the same monitoring, cost tracking, and incident response discipline that harness engineering already worked out, just applied continuously instead of once per run.
There is also a real risk worth naming honestly: people are already calling the overuse of unattended loops "loopmaxxing," where a loop runs for hours, burns budget, and produces a pile of code nobody asked for because the goal was vague and the verifier was weak. A loop is not magic. It is a control system, and like any control system, it is only as good as what you tell it to check for.
Conclusion
I have watched this field rename itself every year or so since I started writing about agents, and each rename has felt a little like marketing at first glance. Loop engineering is different in one respect: it describes a real change in where the human sits in the workflow. We went from writing every prompt by hand, to curating what the model sees, to building safety nets around a single run, and now to designing a small system that runs the whole cycle on our behalf while we go do something else.
The job did not get smaller. It got one level removed from the keyboard. If you found context engineering useful, the next worthwhile habit to build is writing goals that can actually be proven true or false, because that is the one piece that a loop cannot do for itself.
If any of the earlier pieces in this chain are new to you, start with the prompt-to-context shift, then read how that grew into harness engineering in From Prompts to Harnesses: How AI Engineering Has Grown Up, and the production patterns for agents in the Twelve-Factor Agents piece. You can find the rest of what I have written on agents, infrastructure, and developer tools on my DZone author page.
Opinions expressed by DZone contributors are their own.
Comments